分类评估方法
精确率与召回率
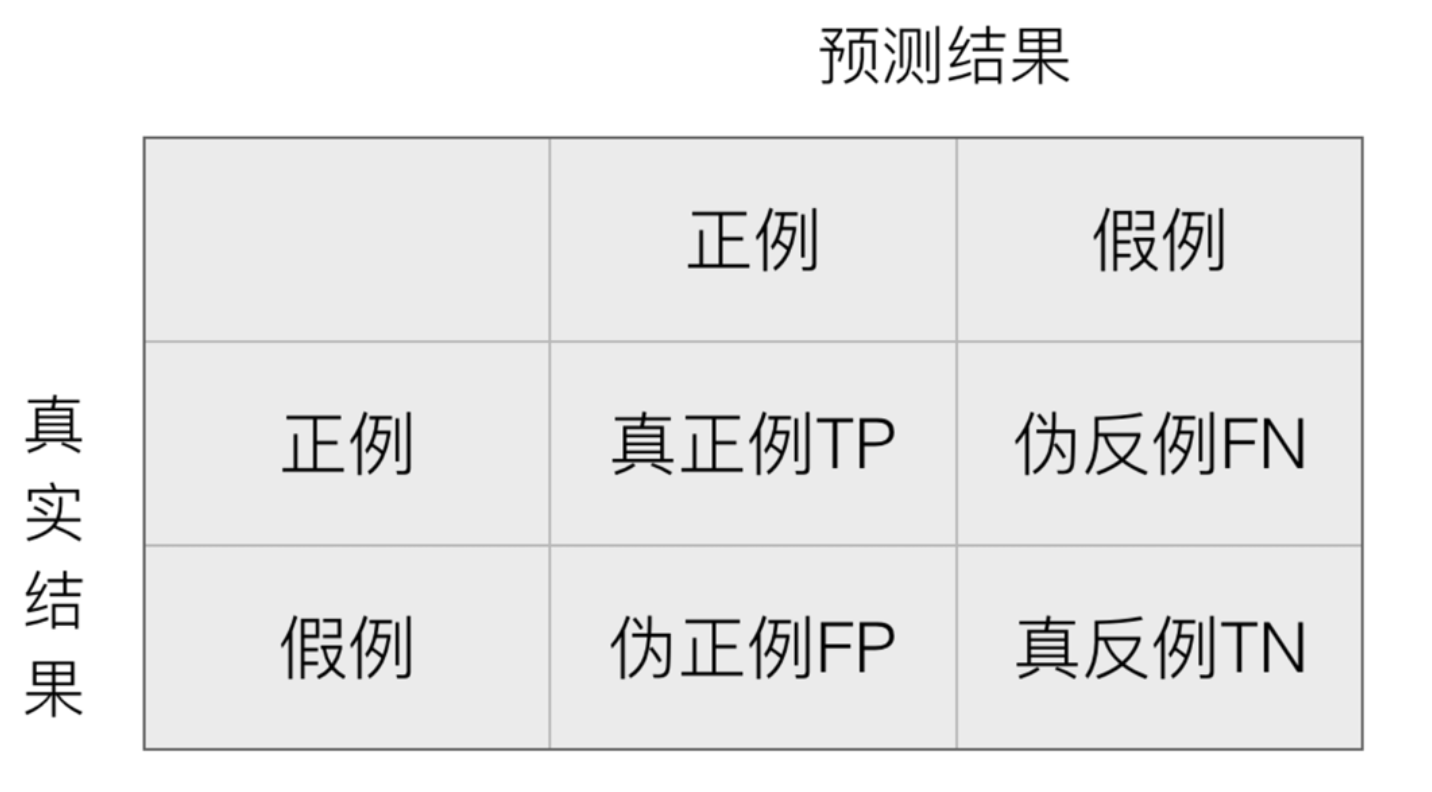
混淆矩阵:在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)。如下图
精确率(Precision)与召回率(Recall)
- 精确率:预测结果为正例样本中真实为正例的比例。比如预测10个人为真,结果真实值为8个人真,2个人为假,那么精确值为0.8.
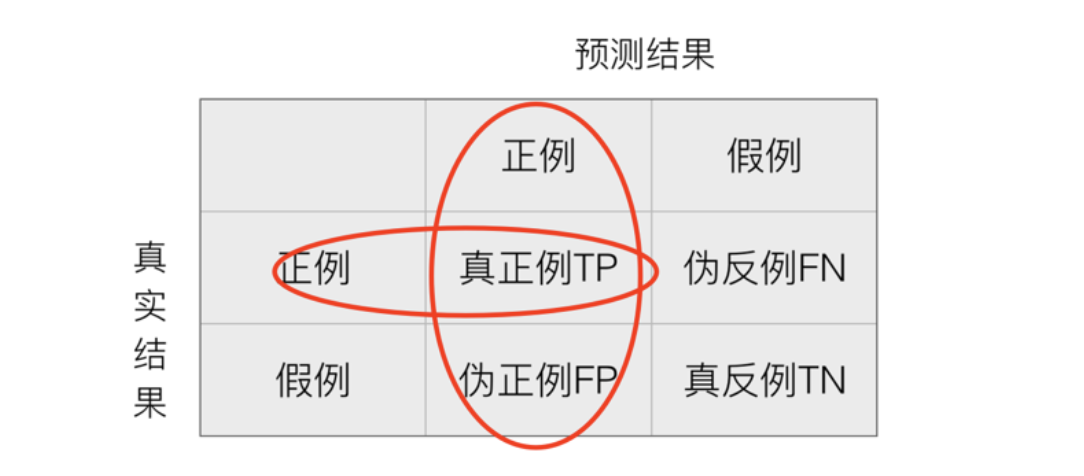
- 召回率:真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力)。比如真实值有20个,但是预测出真实值有16个,那么召回率为0.8.

F1-score
F1-score,反映了模型的稳健型
公式
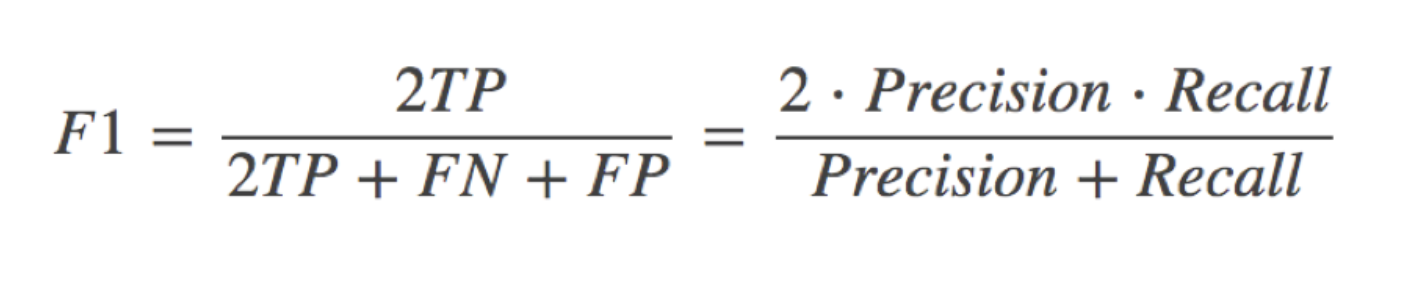
代码api:
- sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
- y_true:真实目标值
- y_pred:估计器预测目标值
- labels:指定类别对应的数字
- target_names:目标类别名称
- return:每个类别精确率与召回率
案例:癌症分类预测-良/恶性乳腺癌肿瘤预测
导包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report,roc_auc_score
获取数据
# 1.获取数据
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",
names = names)
数据处理
# 2.1 缺失值处理
data = data.replace(to_replace="?",value=np.nan)
data = data.dropna()
# 2.2 确定特征值,目标值
x = data.iloc[:,1:-1]
x.head()
y = data["Class"]
y.head()
# 2.3 分割数据
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=22,test_size=0.2)
特征工程(标准化)
# 3.特征工程(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
机器学习(逻辑回归)
# 4.机器学习(逻辑回归)
estimator = LogisticRegression()
estimator.fit(x_train,y_train)
模型评估
# 模型评估
# 5.1 打印分数
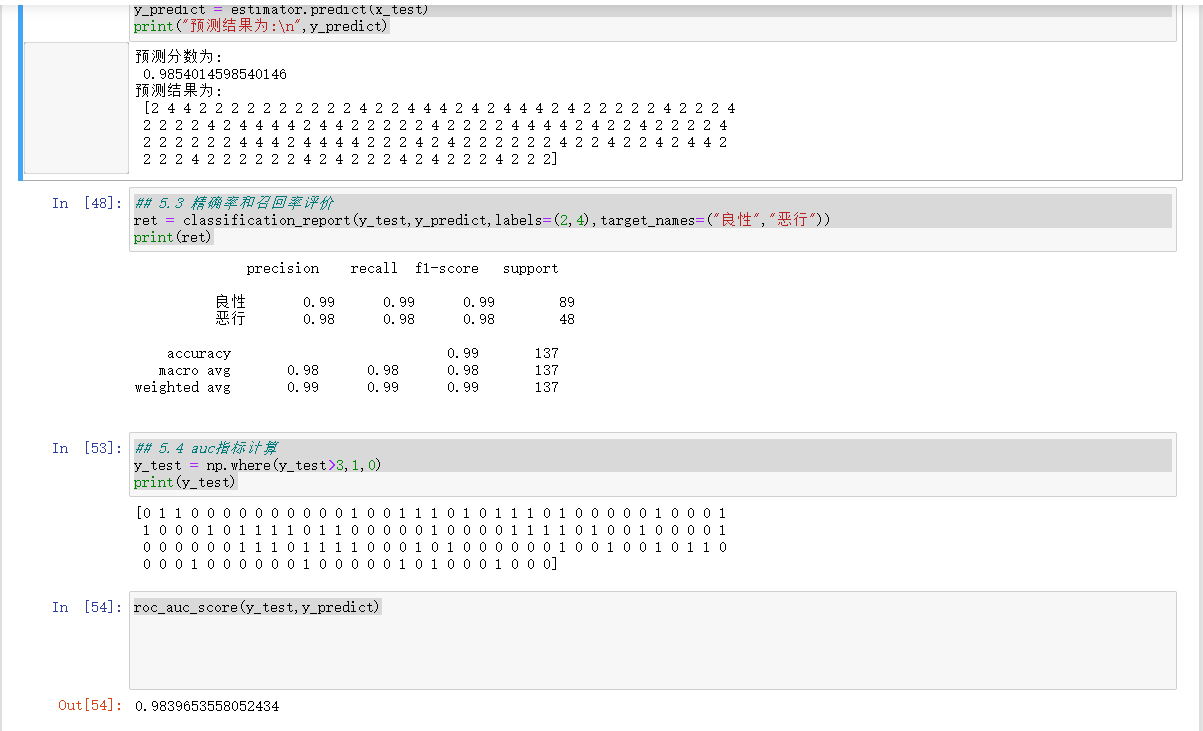
score = estimator.score(x_test,y_test)
print("预测分数为:
",score)
# 5.2 打印预测结果
y_predict = estimator.predict(x_test)
print("预测结果为:
",y_predict)
## 5.3 精确率和召回率评价
ret = classification_report(y_test,y_predict,labels=(2,4),target_names=("良性","恶行"))
print(ret)
## 5.4 auc指标计算
y_test = np.where(y_test>3,1,0)
print(y_test)
roc_auc_score(y_test,y_predict)