Spark 内部管理机制
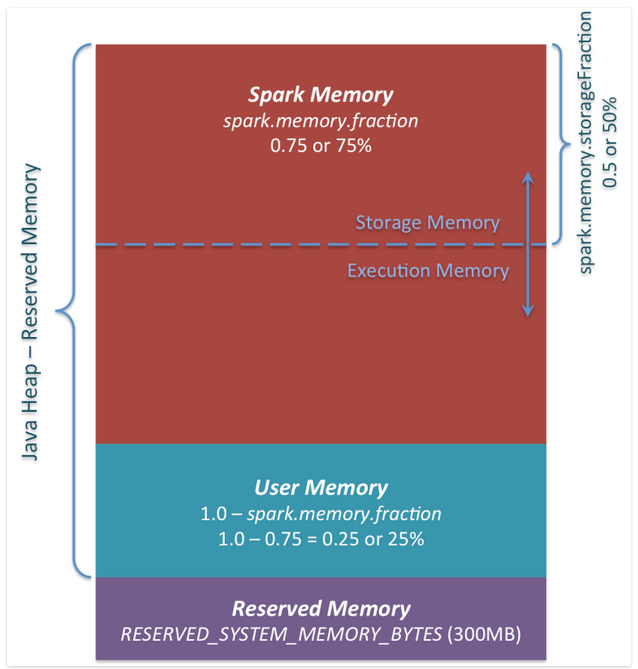
Spark的内存管理自从1.6开始改变。老的内存管理实现自自staticMemoryManager类,然而现在它被称之为”legacy”. “Legacy” 默认已经被废弃掉了,它意味着相同的代码在1.5版本与1.6版本的输出结果将会不同。需要注意的是,出于兼容性的考虑,你依旧可以使用”legacy”,通过设置spark.memory.useLegacyMode改变。 自从spark1.6版本开始,内存管理将实现自UnifiedMemoryManager.那么新的内存管理如下图:
1、预留内存。
为系统预留的内存。同时它是写死的300MB大小。这300MB的内存大小并不在spark计算与缓存内存之中,同时它在任何情况下都不能被改变,除非重新编译或者是设置参数spark.testing.reservedMemory。
事实上,它并不被spark所用,即便你想将所有的内存设置为堆内存为spark缓存数据,你也无法占用这一部分内存资源。(用来存储spark的对象信息等)所以如果你不给spark的每个executor至少1.5*Reserved Memory = 415MB,将会报 please use larger heap size的错误信息。
2、 计算内存
它是一个为spark分配的内存池。它取决于你使用它的方式,可将数据结构用于transformations操作,比如,你可以将你的聚合类操作使用mapPartitions转换为hash表的形式进行操作。那么它将消耗spark的使用内存。
在spark1.6.0的内存池中,计算内存的容量为(“java Heap”-300MB)*(1-spark.memory.fraction),如果按照默认的设置为(“java-heap”-“Reserved Memory) * 0.25。所以在代码中,我们需要根据数据量来设定相关的参数,来防止OOM的发生。
3、 存储内存
Spark的存储内存被也分为存储内存与执行内存。它们的比例可通过spark.memory.storageFraction来设置。默认值为0.5 。使用这种新的内存管理机制的好处在于,使用边界不再是静态的。
Storage Memory 这个资源池被Spark用来缓存数据以及那些没有进行展开的序列化数据作的临时空间,所有的boradcast的广播变量也存储于该缓存块中。那些没有展开的序列化数据将会被返回driver。以及所有的boadcast广播数据的等级来源于 MEMORY_AND_DISK的设置等级。
Execution Memory 这个资源池按我的理解,用来执行shuffle操作的task。它主要用于shuffle过程中map结果的缓存,是以hash作为聚合散列的。同时,支持如果没有足够的内存时,将map的结果写入磁盘。所以,不是说shuffle操作就直接将数据写入磁盘的,也是有个内存缓冲区,我还在想,连hadoop都有缓冲环了,spark还是直接写磁盘吗?NONONO。。
本文翻译自一位国外大神的博客:https://0x0fff.com/spark-memory-management/