在Hadoop中,每个MapReduce任务都被初始化为一个job,每个job又可分为两个阶段:map阶段和reduce阶段。这两个阶段分别用两个函数来表示。Map函数接收一个<key,value>形式的输入,然后同样产生一个<ey,value>形式的中间输出,Hadoop会负责将所有具有相同中间key值的value集合在一起传递给reduce函数,reduce函数接收一个如<key,(list of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key,value>形式。

简易代码:
public static class Map extends MapReduceBase implments Mapper<LongWritable,Text,Text,IntWritable>{ //设置常量1,用来形成<word,1>形式的输出 private fianll static IntWritable one = new IntWritable(1) private Text word = new Text(); public void map(LongWritable key,Text value,OutputCollector<Text,output,Reporter reporter) throws IOException{ //hadoop执行map函数时为是一行一行的读取数据处理,有多少行,就会执行多少次map函数 String line = value.toString(); //进行单词的分割,可以多传入进行分割的参数 StringTokenizer tokenizer = new StringTokenizer(line); //遍历单词 while(tokenizer.hasMoreTokens()){ //往Text中写入<word,1> word.set(tokenizer.nextToken()); output.collect(word,one); } } } //需要注意的是,reduce将相同key值(这里是word)的value值收集起来,形成<word,list of 1>的形式,再将这些1累加 public static class Reduce extends MapReduceBase implements Reducer<Text IntWritable,Text,IntWritable>{ public void reduce(Text key,Iterator<IntWritable> values,OutputCollector<Text,IntWritable> output,Reporter reporter) throws IOException{ //初始word个数设置 int sum = 0; while(values,hasNext()){ //单词个数相加 sum += value.next().get(); } output.collect(key,new IntWritbale(sum)); } }
执行概念总结:
job.setInputFormatClass(TextInputFormat.class);
1.InputFormat()和inputSplit
inputSplit是Hadoop定义的用来传送给每个单独的map的数据,InputSplit存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组,生成InputSplit的方法可以通过InputFormat(I)来设置。当数据传送给map时,map会将输入分片传送到inputFormat上,InputFormat则调用getREcordReduer()方法生成RecordReader,RecordReader再通过createKey()、createValue()方法创建可供map处理的<key,value>对,即<k1,v1>,简而言之InputFormat方法是用来生成可供map处理的<key,value>对的。
在这里如果不设置的话,TextInputFormat会是Hadoop默认的输入方法,在TextInputFormat中,每个人间(或其一部分)都会单独地作为map的输入,继承自FileInputFormat,之后,每行数据都会生成一条记录,每条记录则表示成<key,value>形式:
其中,key值是每个数据的记录在数据分片中的字节偏移量,数据类型是LongWritable.
value值是每行的内容,数据类型是Text。
job.setOutputValueClass(TextInputFormat.class);
2、OutputFormat
每一种输入格式都有一种输出格式与其对应。同样,默认的输出格式是TextOutputFormat,这种输出方式与输入类似,会将每条记录以一行的形式存入文本文件。不过它的键和值都可以以任意形式的,因为程序内部会调用toString()方法将键和值转换为String类型再输出。
3、map和reduce
map函数接收经过inputFormat处理产生的<k1,v1>,然后输出<k2,v2>,map函数老的版本写法是继承MapReduceBase然后实现Mapper接口,但是现在可以直接继承Mapper接口,此接口是一个泛型类型,有4种形式的参数,分别用来指定map的输入key值类型(LongWritable key),输入value值类型(Text value)、输出key值类型和(Text)输出value值类型(IntWritable,本例是reporter)。
reduce函数以map的输出作为输入,因此reduce的输入类型是<Text,IntWritable>.而reduce的输出是单词和它的数目,因此,它的输出类型是<Text,IntWritable>
4、任务调度
计算方面:Hadoop总会有限将任务分配给空闲的机器,使所有的任务能公平地分享系统资源,I/O方面:Hadoop会尽量将map任务分配给InputSplit所在机器,以减少网络I/O的消耗。
5、数据预处理与InputSplit的大小。
Hadoop会在处理每个block后将其作为一个InputSplit,因此合理地甚至block块大小是很重要的。也可通过合理地设置map任务的数量来调节map任务的数据输入。
6、map和reduce任务的数量
设置map任务槽和reduce任务槽,map/reduce任务槽是这个集群能够同时运行的map/reduce任务的最大数量。可以通过hadoop的配置文件设置每台机器最多可以同时运行map任务和reduce任务的个数,比如有10台机器,设置每台最多可以同时运行10个map任务和5个reduce任务,那么这个集群的map任务槽就是1000,reduce任务槽就是500.一般来说,设置的reduce任务数量应该是reduce任务槽的0.95或是1.75倍
7、combine函数
combine函数是用于在本地合并数据的函数,从wordcount程序中,词频是一个接近于zipf分布的,每个map任务可能会产生成千上万个<the,i>记录,若将这些记录一一传给reduce任务是很耗时的,所以可以设置一个combine函数,用于本地合并,大大减少网络I/O操作的消耗。
job.setCombinerClass(combine.class); //指定reduce函数为combine函数 job.setReducerClass(Reduce.class);
8、Hadoop流的工作原理
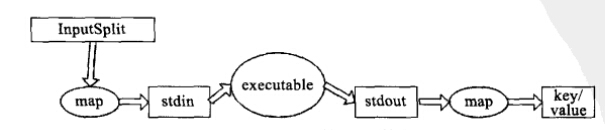
当一个可执行文件作为Mapper时,每个map任务会以一个独立的进程启动这个可执行文件,然后在map任务运行时,会把输入切分成行提供给可执行文件,并作为它的标准输入(stdin)内容。当可执行文件运行处结果时,map从标准输出(stdout)中手机数据,并将其转化为<key,value>对,作为map的输出。
参考:<Hadoop实战>