RDD工作原理:
主要分为三部分:创建RDD对象,DAG调度器创建执行计划,Task调度器分配任务并调度Worker开始运行。
SparkContext(RDD相关操作)→通过(提交作业)→(遍历RDD拆分stage→生成作业)DAGScheduler→通过(提交任务集)→任务调度管理(TaskScheduler)→通过(按照资源获取任务)→任务调度管理(TaskSetManager)

举例:以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的。
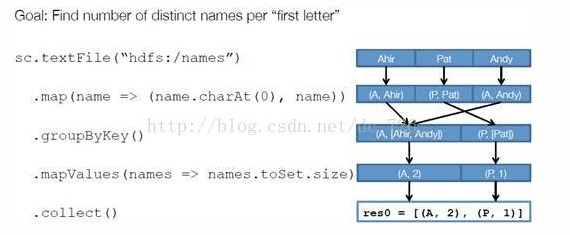
步骤 1 :创建 RDD 。 上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好所有 RDD( 内部的五项信息 ) 。
步骤 2 :创建执行计划。 Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计划。
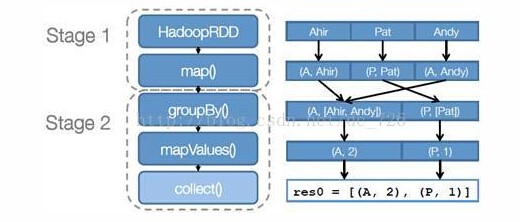
步骤 3 :调度任务。 将各阶段划分成不同的 任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
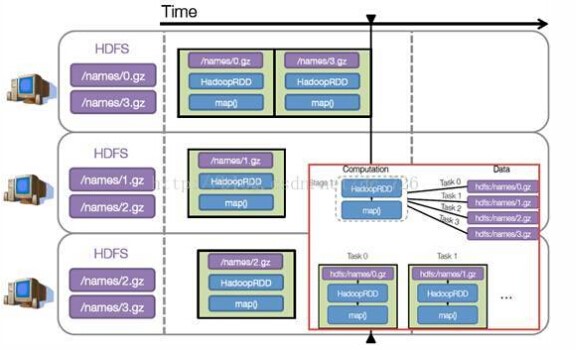
假设本例中的 hdfs://names 下有四个文件块,那么 HadoopRDD 中 partitions 就会有四个分区对应这四个块数据,同时 preferedLocations 会指明这四个块的最佳位置。现在,就可以创建出四个任务,并调度到合适的集群结点上。
Task管理和序列化:
Task的运行要解决的问题不外乎就是如何以正确的顺序,有效地管理和分派任务,如何将Task及运行所需相关数据有效地发送到远端,以及收集运行结果
Task的派发源起于DAGScheduler调用TaskScheduler.submitTasks将一个Stage相关的一组Task一起提交调度。
在TaskSchedulerImpl中,这一组Task被交给一个新的TaskSetManager实例进行管理,所有的TaskSetManager经由SchedulableBuilder根据特定的调度策略进行排序,TaskSchedulerImpl的resourceOffers函数中,当前被选择的TaskSetManager的ResourceOffer函数被调用并返回包含了序列化任务数据的TaskDescription,最后这些TaskDescription再由SchedulerBackend派发到ExecutorBackend去执行
系列化的过程中,上一节中所述App依赖文件相关属性URL等通过DataOutPutStream写出,而Task本身通过可配置的Serializer来序列化,当前可配制的Serializer包括如JavaSerializer ,KryoSerializer等
Task的运行结果在Executor端被序列化并发送回SchedulerBackend,由于受到Akka Frame Size尺寸的限制,如果运行结果数据过大,结果会存储到BlockManager中,这时候发送到SchedulerBackend的是对应数据的BlockID,TaskScheduler最终会调用TaskResultGetter在线程池中以异步的方式读取结果,TaskSetManager再根据运行结果更新任务状态(比如失败重试等)并汇报给DAGScheduler等