自从Linux系统诞生之始,监控系统就随之出现。
当然说到监控系统,我们就必须聊到SNMP协议,SNMP分为管理端(NMP)和被管理端。
管理端周期性的到被监控端采集数据,被监控端还需要有权限收集数据,然后将数据回馈给NMS。
SNMP是一种常见的协议,众多网络工具和众多操作系统都支持。
比如常见的路由交换都内置SNMP的agent,既可以作为管理端又可以作为被管理端。
linux有net-snmp这个包。SNMP大致有三个版本,比较通行v2c,无论是v1还是v2安全性都很差,数据传输是明文的,认证机制也很薄弱,但尽管如此,v3仍不通行。
但好在支持网络管理的功能。很多开源的监控软件都有自己开发的agent,这样安全性就会好了很多。
如果想简单的获取数据,使用SNMP会比较快捷。SNMP只负责数据采集,数据采集之后如何存储、如何分析是个问题。
早期的cacti监控系统,就是调用SNMP的功能,然后进行一些其它操作。使用PHP编写。不需要安装agent。支持模板,使用rrd(轮转数据库)。
cacti利用SNMP采集数据,利用rrd保存数据并绘图。cacti本身没有报警功能,可以安装插件来进行报警。
cacti只是比较原始的、功能比较单一的监控系统,后面陆续有Nagios、Zabbix、Prometheus等监控系统出现。
监控对象也从原来的对服务器、程序、web页面等方面衍生到了对容器等多方面的监控。
下面会简要说明常见的一些监控系统:
1.Nagios
Nagios原名为NetSaint,由Ethan Galstad开发并维护。Nagios是一个老牌监控工具,由C语言编写而成。
主要针对于主机监控(CPU、内存、磁盘等)和网络监控(SMTP、POP3、HTTP和NNTP等),也支持用户自定义监控脚本。
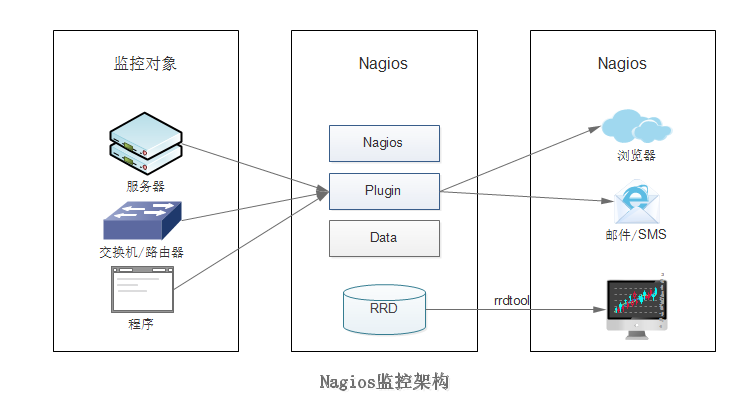
Nagios的整体架构非常清晰,它通过Plugin采集各种监控数据。
Nagios数据被保存在RRD环形数据库中,特别适合存储时序数据。
总体来说,Nagios的报警功能还是非常强大,支持软状态切换、支持依赖关系定义。
但是Nagios只关心正常与否的问题,不适合实时监控,你无法的获取某个监控项时间段的状态。
与Zabbix一样,在大规模集群、高性能服务要求等场景下,Nagios会显得有点力不从心。
2.Zabbix
Zabbix基本上可以满足中小型公司对于监控的需求,其支持多种采集方式、支持多种协议。
基本上可以做到监控一切需要监控的监控项,其发展已经非常成熟,有非常完善的内置监控项,
同时组件较少,上手难度不高,管理也特别方便,是很多创业公司的首选。
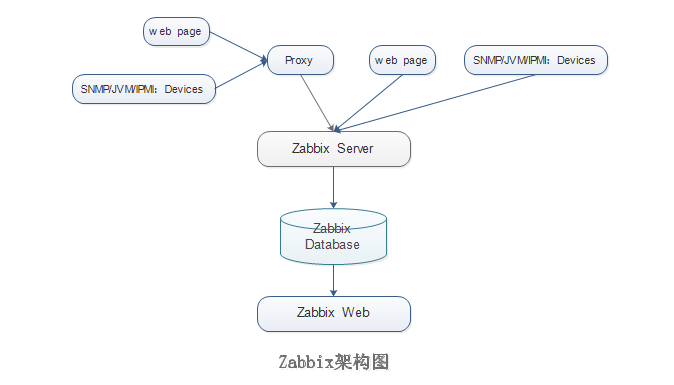
zabbix的组件并不是非常多,虽然清晰明确,但是制约了其性能。主要组件有以下部分:
(1)Zabbix Server
Zabbix的核心组件,由C语言编写而成,主要负责接收Agent发送的监控信息,并进行汇总存储。主要工作内容有以下三点:
设备注册:将需要监控的对象纳入监控系统中,有手动配置和自动发现两种方式。
数据收集:包括主动收集和被动收集,然后将数据保存到数据库中。
数据清理和告警触发:通过触发器与采集的数据匹配,满足条件则会进行告警。
Zabbix Server把基本能做的事情都做了,这样非常制约其性能,在其后出现的监控系统中都会将其功能进行拆分。
(2)Zabbix Database
用于存储配置信息及Zabbix收集到的监控数据,支持多种类型的数据库,包括MySQL、Oracle、PostgreSQL等。
由于Zabbix诞生的时间比较久远,采用的都是关系型数据库,
因此在监控大规模集群或者监控项繁多的情况下可能会存在问题。
(3)Zabbix Web
Zabbix的GUI组件,由PHP编写而成,通常与Server运行在同一台机器上,
提供监控数据的展现和系统配置,主要配置包括监控模板、告警等。
(4)Proxy
可选组件,常用于分布式监控环境中,代理Server收集部分被监控的监控数据,
并按照一定的频率统一发往Server端。Proxy有自己的数据库,主要为了解决以下两个问题。
Server和Agent之间网络不连通。
减轻Server的压力。
Proxy并不能完全解决Server组件负载的过重的麻烦。
(5)Agent
主要用来采集被监控端的数据。
3.Open-Flacon
Open-Falcon是小米开源的企业级监控工具,由Go语言开发而成,包括小米、滴滴、美团在内的互联网公司都在使用。
Open-Falcon是一款灵活、可扩展并且高性能的监控方案。
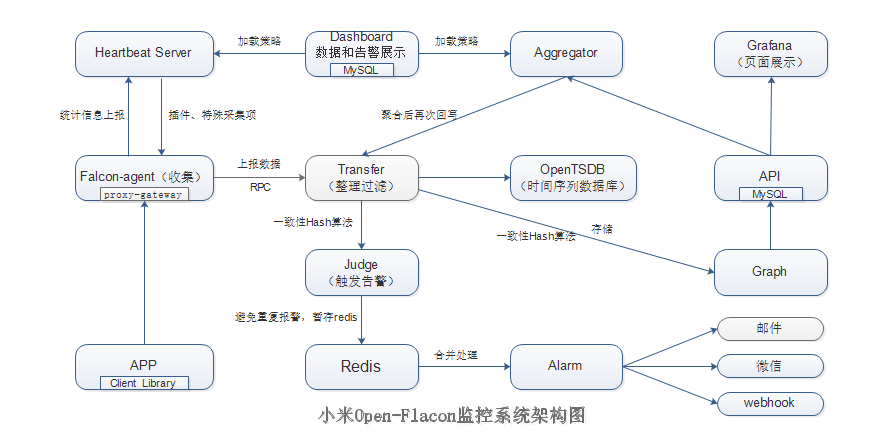
它的主要组件有以下部分:
(1)Falcon-agent
用Go语言开发的Daemon程序,运行在每台Linux服务器上,用于采集主机上的各种指标数据。
主要包括CPU、内存、磁盘、文件系统、内核参数、Socket连接等,目前已经支持200多项监控指标。
并且,Agent支持用户自定义的监控脚本,脚本必须返回Agent指定的数组格式。Agent采集的数据会通过RPC方式上报到Tranfer。
为了避免单个Transfer发生故障,Agent支持配置多个Transfer地址,还可以忽略多余的监控指标。
Agent本身也可以成为一个Proxy-gateway代理网关,接收第三方HTTP请求并将其转发到Transfer中。
类似zabbix的agent,Kubernetes自带监控体系中的cAdvisor,Nagios中的Plugin,
本质就是一个被封装的SNMP协议的客户端,都是用来进行数据采集的,也是监控系统中必备的组件了。
(2)Hearthbeat server
简称HBS(心跳服务),每个Agent都会周期性地通过RPC方式将自己地状态上报给HBS,
主要包括主机名、主机IP、Agent版本和插件版本,Agent还会从HBS获取自己需要执行的采集任务和自定义插件。
(3)Transfer
负责监控agent发送的监控数据,并对数据进行处理,在过滤后通过一致性Hash算法将数据发送到Judge或者Graph。
为了支持存储大量的历史数据,Transfer还支持OpenTSDB。Transfer本身没有状态,可以随意扩展。
数据的处理和汇总也是每个监控系统必须的流程,类似的组件由Heapster、Logstash。
(4)Jedge
告警模块,Transfer转发到Judge的数据会触发用户设定的告警规则,如果满足,则会触发邮件、微信或者回调接口。
这里为了避免重复告警,引入了Redis暂存告警,从而完成告警合并和抑制。
(5)Graph
RRD数据上报、归档、存储的组件。Graph在收到数据以后,会以RRDtool的数据归档方式存储数据,同时提供RPC方式的监控查询接口。
在Nagios和catia中,也是将数据保存在RDD环形数据库中,Zabbix的存储数据相对多样,可以是MySQL、Oracle等
而在kubernetes自带的监控体系中,也是可以保存到多种存储系统中,例如InfluxDB、Kafka等
灵活的存储的体系是开源软件的一种必要的设计原则。
(6)API
主要提供查询接口,不但可以从Grapg里面读取数据,还可以对接MySQL,用于保存告警、用户等信息。
(7)Dashboard
由Python开发而成,提供Open-Falcon的数据和告警展示,监控数据来自Grash,Dashboard允许用户自定义监控面板。
(8)Aggregator
聚合组件,聚合某集群下所有机器的某个指标的值,提供一种集群视角的监控体验。
通过定时从Graph获取数据,按照集群聚合产生新的监控数据并将监控数据发送到Transfer。
总的说来,小米的这套Open-Falcon监控系统设计的还是特别合理,功能也特别丰富。
但是这类系统相比于Zabbix来说,管理起来还是相对复杂,同时对于二次开发还是有一定要求。
其相对于其它一些常见的开源监控杆系统来说,其监控的业务场景更大,不像Zabbix免费版本只适合中小型企业。
它能够支持中大型公司复杂业务监控场景的高可用的需求。
4.Prometheus
Prometheus的基本原理是通过HTTP周期性抓取被监控组件的状态,
任意组件只要提供对应的HTTP接口并且符合Prometheus定义的数据格式,就可以接入Prometheus监控。
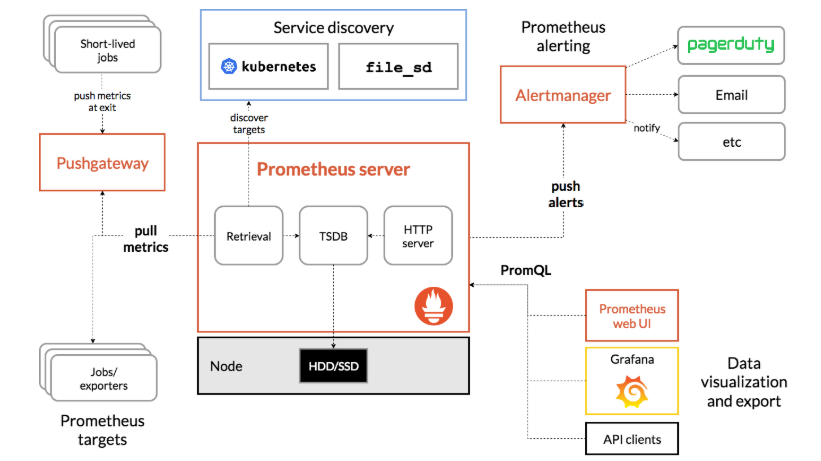
Prometheus Server负责定时在目标上抓取metrics(指标)数据,
每个抓取目标都需要暴露一个HTTP服务接口用于Prometheus定时抓取。
TSDB通过一定的规则清理和整理数据,并把得到的结果存储到新的时间序列中。一般有以下两种存储方式:
一种是本地存储。通过Prometheus自带的时序数据库将数据保存到本地磁盘,为了性能考虑,建议使用SSD。
另一种是远端存储,适用于存储大量监控数据。通过中间层的适配器的转化,
目前Prometheus支持OpenTSDB、InfluxDB、Elasticsearch等后端存储,
通过适配器实现Prometheus存储remote write和remote read接口,便可以接入Prometheus作为远端存储使用。
HDD代表硬盘,SSD是固态硬盘。
Prometheus通过PromQL和其它API可视化地展示收集地数据。
Prometheus支持多种方式地图标可视化,例如Grafana、自带的PromDash及自生提供的模板引擎。
Prometheus还提供HTTP API拆查询方式、自定义所需的输出。
Prometheus提供了PushGateway的支持,这些系统主动推送metrics到PushGateway,而后Prometheus定时去gateway上抓取数据。
AlertManager是独立于Prometheus的一个组件,在触发了预先设置在Prometheus中的高级规则后,Prometheus会推送告警信息到AlertManager。
AlertManager提供了非常灵活的告警方式,可以通过邮件、slack等途径推送。
AlertManager支持高可用部署,为了解决多个AlertManager重复告警的问题,引入Gossip,在多个AlerManager之间通过Gossip同步告警信息。
5.Heapster+InfuxDB+Grafana
Heapster是Google专门面向Kubernetes开发的性能数据集中监控系统,可以与多种系统对接,构成完整的监控平台。
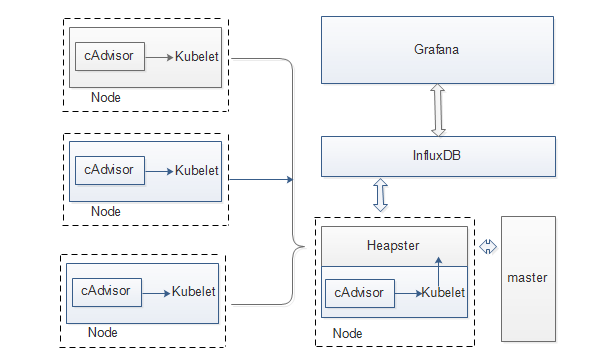
主要组件如下所示:
(1)cAdvisor
是Google开发的容器监控组件,部署在每一个Kubernetes Node节点上,
负责收集所在主机及该主机上所有容器的性能数据,包括CPU、Memory、FileSystem、Network I/O等
Heapster:负责汇总各Node节点上cAdvisor的数据,并可以保存多种后端存储系统(例如InfluxDB、Kafka等)。
Heapster的工作流程:访问master节点,获取当前集群节点的信息,然后访问各节点的Kubelet组件API,再通过调用cAdvisor的API来收集该节点上所有容器的性能数据。
Heapster对采集到的数据进行聚合,将结果保存(sink)到多种后端存储,例如InfluxDB、Elasticsearch等,为容器集群的监控和性能分析提供了强大的支持。
(2)InfluxDB
是用一种Go语言编写的分布式时序数据库,能够存储监控数据、应用数据、IoT传感数据等各种场景中大规模带时间戳的数据,
支持使用类SQL语句进行实时查询,提供可定制的数据存储保留策略,还提供RESTful API进行数据的存储和访问。
(3)Grafana
是一款页面展示工具,提供多种分析插件,可以支持多种主流数据库(InfluxDB、Elasticsearch、Graphite、CloudWatch等)的数据展示。
它可将保持在InfluxDB中的数据以图表、曲线等形式进行展示,方便运维人员实时监控整个集群的运行状态。
总的来说,Heapster只是针对kubernetes来设计的监控平台。
因为其是通过调用kubelet的API接口,kubelet再调用cAdvisor的API接口来进行数据的收集。
随后通过Heapster将数据存储到数据库,最后通过其它的组件展示出来。
下面针对Prometheus、Zabbix、Nagios和Open-Falcon这几种监控系统的对比:
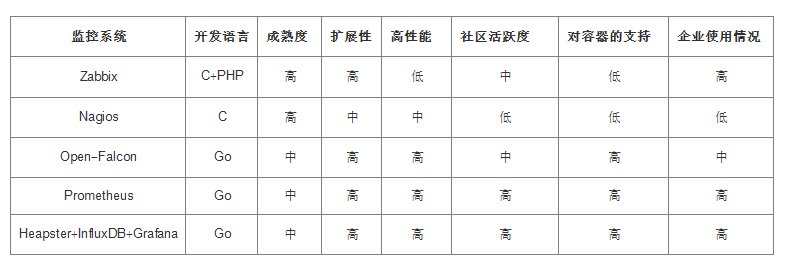
从开发语言上看,为了应对高并发和快速迭代的需求,监控系统的开发语言已经慢慢从C转移到了Go。
不得不说,Go凭借简洁的语法和优雅的并发,在Java占据业务开发领域,C占领底层开发领域的情况下,
准确定义中间件开发需求,在当前的开源中间件产品中被广泛应用。
从系统成熟方面来看,Zabbix和Nagios都是老牌监控系统:Zabbix诞生于1998年,Nagios诞生于1999年,系统功能都比较稳定,成熟度较高。
而Prometheus和Open-Falcon都是最近几年才诞生,虽然功能还在不断迭代、更新,但是毕竟还很年轻,
而Heapster则完全要依赖于kubernetes,因此更加年轻。
从系统扩展性能来看,Zabbix和Open-Falcon都可以自定义各种监控脚本,Zabbix不仅可以做到主动推送,还可以做到被动拉取。
Prometheus则定义了一套监控数据规范,并通过各种exporter扩展系统采集能力。
从数据存储方面来看,Zabbix采用关系型数据库存储数据,这极大限制了Zabbix的数据采集能力。
Nagios和Open-Falcon都采用了RDD数据存储方式。Open-Falcon还加入了一致性Hash算法进行数据分片,
并且可以对接到OpenTSDB,而且Prometheus自己开发了一套高性能时序数据库,
在V3版本时可以达到每秒千万级别的数据存储,可通过对接第三方时序数据库扩展对历史数据的存储性能。
从社区活跃度方面来看,目前Zabbix和Nagios的社区活跃度比较低,
尤其是Nagios和Open-Falcon的社区虽然也比较活跃,但基本都是国内的公司在参与。
Prometheus的社区活跃度很高,并且得到CNCF的支持,后期的发展值得期待。
从容器支持方面来看,由于Zabbix和Nagios出现的比较早,当时容器还没有诞生,所以它们对容器的支持自然比较差。
Open-Falcon虽然提供了容器监控的功能,但支持力度有限。
Prometheus的动态发现机制,不仅支持Swarm原生集群,还支持Kubernetes容器集群监控,是目前容器集群监控的最佳方案。
总的来说,Nagios在网络监控方面有广泛应用,zabbix在传统的服务器监控相关方面占绝对优势。
Prometheus则是容器领域的标配,Heapster在kubernetes1.11版本之后,逐渐被废弃。