我们都说,Java 是一门面向对象型程序设计语言,但是它设计出来的「基本数据类型」仿佛又打破了这一点,所以,只能说 Java 是非 100% 纯度的面向对象程序设计语言。
但是,为什么 Sun 公司一直没有删除「基本数据类型」,而是为它增设了具有面向对象设计思想的「包装类型」呢?
想必是有道理的,那么本文就试着分析一下「基本数据类型」存在的意义以及具有哪些优势点,还有「包装类」的具体实现细节。
基本类型 VS 对象类型
Java 中预定义了八种基本数据类型,包括:byte,int,long,double,float,boolean,char,short。基本类型与对象类型最大的不同点在于,基本类型基于数值,对象类型基于引用。
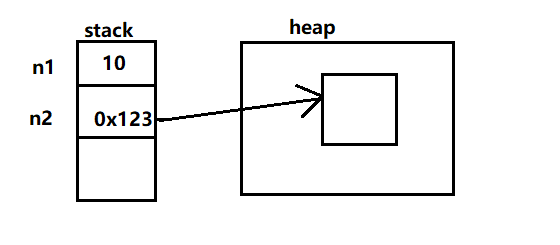
基本类型的变量在栈的局部变量表中直接存储的具体数值,而对象类型的变量则存储的堆中引用。
显然,相对于基本类型的变量来说,对象类型的变量需要占用更多的内存空间。
上面说到,基本类型基于数值,所以基本类型是没有类而言的,是不存在类的概念的,也就是说,变量只能存储数值,而不具备操作数据的方法。对象类型则截然不同,变量实际上是某个类的实例,可以拥有属性方法等信息,不再单一的存储数值,可以提供各种各样对数值的操作方法,但代价就是牺牲一些性能并占用更多的内存空间。
之所以 Java 里没有一刀切了基本类型,就是看在基本类型占用内存空间相对较小,在计算上具有高于对象类型的性能优势,当然缺点也是不言而喻的。
所以一般都是结合两者在不同的场合下适时切换,那么 Java 中提供了哪些「包装类型」来弥补「基本类型」不具备面向对象思想的劣势呢?
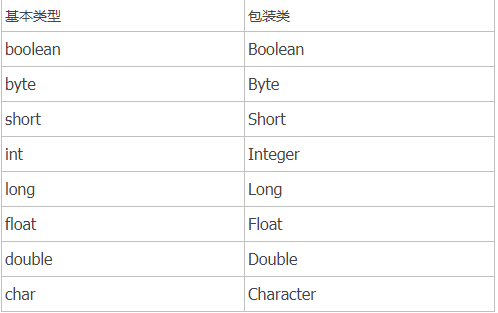
可以看到,除了 int 和 char 两者的包装类名变化有些大以外,其余六种基本类型对应的包装类名,都是大写了首字母而已。
下面我们以 int 和 Integer 为例,通过源码简单看看包装类具体是如何实现的。
int 与 Integer
首先需要明确一点的是,既然 Integer 是 int 的包装类型,那么必然 Integer 也能像 int 一样存储整型数值。
/**
* The value of the {@code Integer}.
*
* @serial
*/
private final int value;
Integer 类的内部定义了一个私有字段 value,专门用于保存一个整型数值,整个包装类就是围绕着这个 value 封装了各种不同操作的方法。
而接着我们看看如何构建一个包装类实例:
public Integer(int value) {
this.value = value;
}
public Integer(String s) throws NumberFormatException {
this.value = parseInt(s, 10);
}
Integer 类中提供两种构造器给我们构建和初始化一个 Integer 类实例。第一种比较直接,允许你直接传入一个整型数值对 value 进行初始化。第二种间接一点,允许你传入一个数字的字符串,Integer 内部会尝试着将字符串向整型数值进行转换,如果成功则初始化 value,否则将抛出一个异常。
所以我们可以通过以下代码将一个 int 类型变量转换成一个 Integer 的包装类实例:
int age = 22;
Integer iAge = new Integer(age);
接着,我们知道使用 System.out.println 方法打印一个 Integer 实例时,虚拟机会使用 Integer 实例的 toString 方法的返回值作为打印方法的参数。
那么 Integer 内部是如何实现将一个数值转换为一个整型数值的呢?可能这个问题大家很少想过,因为这样的细小的问题基本都被封装的很好了,我们一般的开发并不需要过多的关心,但是如果让你来写,你能准确的写出来吗?
public String toString() {
return toString(value);
}
首先,默认无参的 toString 方法会调用内部有参的另一个 toString 方法。
public static String toString(int i) {
if (i == Integer.MIN_VALUE)
return "-2147483648";
int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i);
char[] buf = new char[size];
getChars(i, size, buf);
return new String(buf, true);
}
如果你的值等于 Integer.MIN_VALUE,那么直接返回预定义好的字符串即可,否则将会通过一个方法 stringSize 确定当前传入的整数 i 是一个几位的整数,也就是它需要使用几个字符进行表示,该方法的具体细节我们等会说,这是一个实现很优雅的算法。
确定了 size,于是可以创建字符数组,并通过 getChars 方法完成数值向字符串的转换,并最后构建一个字符串对象返回。
我们先看看这个 stringSize 方法的具体实现是怎样的:
final static int [] sizeTable = { 9, 99, 999, 9999, 99999, 999999, 9999999,
99999999, 999999999, Integer.MAX_VALUE };
static int stringSize(int x) {
for (int i=0; ; i++)
if (x <= sizeTable[i])
return i+1;
}
这段代码的实现于我用文字来描述可能不是那么清晰,我举个例子,你就能很快明白了。
例如:x 等于 85,那么比 x 大并且最接近 x 的 sizeTable 元素是 99(两位数中最大的数值),索引为 1,于是我们得到 x 是一个两位数(1+1)。
仔细想一想,还是很好理解的,sizeTable 中的每个元素都是同等位数数字下最大的数值,99 是两位数中最大的,999 是三位数中最大的,等等。那么当 x 最接近某个索引的元素时,即说明 x 的位数和该元素是一样的,然后计算该元素的位数即可。
接着我们看看核心的 getChars 方法是如何实现的:
static void getChars(int i, int index, char[] buf) {
int q, r;
int charPos = index;
char sign = 0;
if (i < 0) {
sign = '-';
i = -i;
}
while (i >= 65536) {
q = i / 100;
// really: r = i - (q * 100);
r = i - ((q << 6) + (q << 5) + (q << 2));
i = q;
buf [--charPos] = DigitOnes[r];
buf [--charPos] = DigitTens[r];
}
for (;;) {
q = (i * 52429) >>> (16+3);
r = i - ((q << 3) + (q << 1)); // r = i-(q*10) ...
buf [--charPos] = digits [r];
i = q;
if (i == 0) break;
}
if (sign != 0) {
buf [--charPos] = sign;
}
}
别看这个方法的代码不多,但是却要求你有一定的二进制位运算基础。首先需要明确几个形参所代表的含义,i 就是我们待转换成字符串的整型数值,index 是该数字的位数,buf 数组是转换后的字符存储的容器,用于存储结果。
首先,如果 i 是一个负数,那么变量 sign 的值给它赋为「-」,标识它是一个负数,并将它取正,毕竟正数更方便我们操作。
接着是一个循环,只要 i 大于 65536(2^16),就一直执行循环体。
q = i / 100;
// q * (2^6 + 2^5 + 2^2) = q * 100
r = i - ((q << 6) + (q << 5) + (q << 2));
q 得到的是 i 去掉个位和十位后的值,而 r 得到的就是丢失的十位和个位,举个例子:如果 i 等于 12345,那么 q 等于 123,r 等于 45 。
最后重置 i 的值以便进入下一次循环,并通过下面两条语句完成个位和十位的存储。
buf [--charPos] = DigitOnes[r];
buf [--charPos] = DigitTens[r];
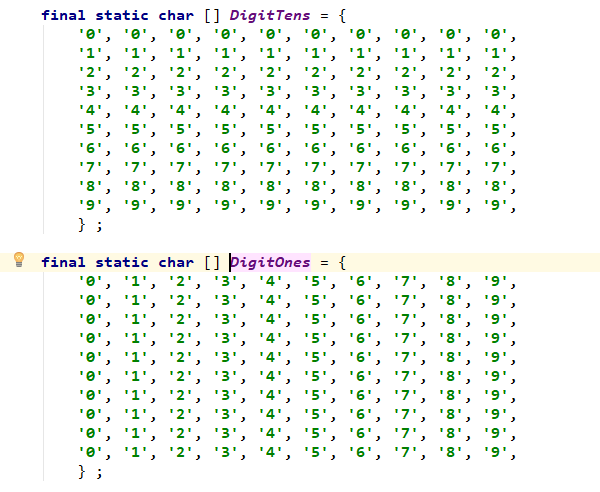
这两条赋值语句也很有意思,由于 r 必然是一个两位数,所以无论怎样 r 不会超过 100 。例如:r 等于 56,那么 DigitOnes[r] 将得到 6,DigitTens[r] 将得到 5 。
这段代码的设计还是很巧妙的,那么通过这个循环,大于 65536 的位数都被倒序存储进 buf 数组中了。
接着的一个 for 循环完成就是对小于 65536 的位部分的存储。
q = (i * 52429) >>> (16+3);
r = i - ((q << 3) + (q << 1));
因为 2^ 19 等于 524288,所以 (i * 52429) >>> (16+3) 等效于 i * 52429 / 524288 约等于 i * 0.1000003814697 ,而 q 是整型数值,所以最终 q 的值其实就等于 i / 10 。
可能为了效率才将简单的除以十的操作搞这么复杂的吧,最终 q 存储的是 i 去掉个位后的数值,r 存储的是丢失的个位。
例如:i 等于 1234,那么 q 等于 123,r 等于 4 。
于是可以通过类似的思想一位一位的存储:
buf [--charPos] = digits [r];
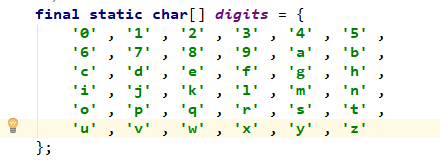
而最后,判断 sign 标志位以决定输出该字符串的时候是否需要带上符号「-」以表示该数值的正负性。
总结一下整个 toString 方法,核心点就两件事,一是确定该数值的位数,即需要用几个字符进行表述,二是根据数值转换成字符串。第一步很简单,不用多说,第二步针对 value 值的大小分步骤进行,大于 65536 的数值采取每次两位的速度存储,小于 65536 的数值位采取一位的速度存储。
Integer 类中还有一类方法,valueOf,这是一个很重要的方法,jdk 1.5 以后实现的自动拆装箱就是基于它的,具体的我们后面说,先看这个方法的实现。
该方法用到一个 IntegerCache 缓存机制,so,我们先看看这个缓存机制在 Integer 中的实现情况:
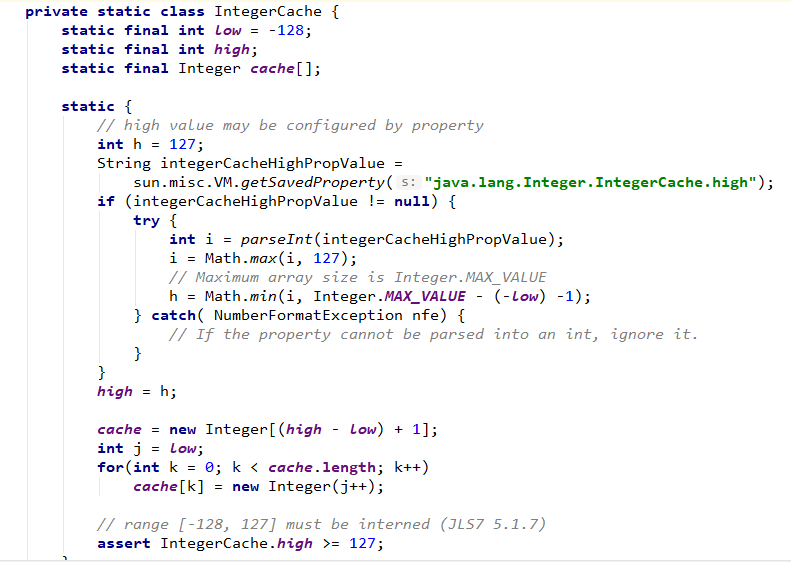
自 jdk 1.5 以后,sun 加入了这个缓存类用于复用指定范围内的 Integer 实例,把内容相同的对象缓存起来,减少内存开销。默认可以缓存数值在 [-128,127] 之间的实例,当然你可以通过启动虚拟机参数 -XX:AutoBoxCacheMax 指定缓存区间的最大数值。
而程序的第一步就是读取虚拟机启动参数判断程序启动时是否指定了可缓存的最大数值,如果 integerCacheHighPropValue 为 null,那么说明并没有显式指定,于是使用 127 作为可缓存的最高限定。
否则,根据参数进行一些计算,如果设定的参数小于 127,那么将取 127 作为缓存的最高限定值。理论上,我们可以缓存最大到 Integer.MAX_VALUE ,但是实际上是做不到的,因为 Integer[] 数组可定义的最大长度就是 Integer.MAX_VALUE,而我们还有 127 个负数待缓存,显然数组容量是不够的。
所以 IntegerCache 其实最大能缓存到 Integer.MAX_VALUE - 129,一旦是设定的参数大于这个值,将默认取用这个值作为最高缓存限定。
所以,最终 IntegerCache 能够缓存的数值区间介于 [low,high] 之间。
然后我们看 valueOf 这个方法是如何使用 IntegerCache 的:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
如果 i 介于我们的缓存区间的话,将直接从 IntegerCache 中返回直接引用,只是它这里的取值方式有点意思。
cache[0] = -128(128 + -128) cache[1] = -127(128 + -127)
cache[2] = -126(128 + -126) cache[3] = -125(128 + -125)
......
cache[128 + i] = i;
因为 cache 是从 -128 开始缓存的,而索引又是从 0 开始的,所以任意一个数值距离 -128 的差值就是该值缓存在 cache 中的索引。
所以,一旦 i 位于我们缓存的值区间,那么将直接从缓存池中返回直接引用,否则将会实际创建一个 Integer 实例返回。
我们这里分析了三到四个方法的源码实现,其实 Integer 类中还有很多工具性的方法,限于篇幅我们不能一一叙述,大家可以自行学习一下。
有关于包装类型和基本类型之间的关系想必大家已经稍有了解了,还有一些有关自动拆装箱以及一些经典的面试题放在下篇文章。
文章中的所有代码、图片、文件都云存储在我的 GitHub 上:
(https://github.com/SingleYam/overview_java)
欢迎关注微信公众号:扑在代码上的高尔基,所有文章都将同步在公众号上。
