前言
面试题仅做学习参考,学习者阅后也要用心钻研其中的原理,重要知识需要系统学习、透彻学习,形成自己的知识链。以下五点建议希望对您有帮助,早日拿到一份心仪的offer。
- 做好细节工作,细致的人运气不会差
- 展现特别可以,但要建立在已充分展示实力的基础上
- 真诚比圆滑重要,请真诚地回答问题
- 把握当下,考场外的表现能起的作用微乎其微
- 没有通过不代表你不优秀,选人先考虑的是与岗位相匹配

Python 三程三器
- 进程
- 进程是资源分配的最小单位(内存、CPU、网络、io)
- 一个运行起来的程序就是一个进程
- 什么是程序(程序使我们存储在硬盘里的代码)
- 硬盘(256G)、内存条(8G)
- 当我们双击一个图标、打开程序的时候,实际上就是通过IO(读写)内存条里面
- 内存条就是我们所指的资源
- CPU分时
- CPU比你的手速快多了,分时处理每个线程,但是由于太快然你觉得每个线程都是独占cpu
- cpu是计算,只有时间片到了,获取cpu,线程真正执行
- 当你想使用 网络、磁盘等资源的时候,需要cpu的调度
- 进程具有独立的内存空间,所以没有办法相互通信
- 进程如何通信
- 进程queue(父子进程通信)
- pipe(同一程序下两个进程通信)
- managers(同一程序下多个进程通信)
- RabbitMQ、redis等(不同程序间通信)
- 进程如何通信
- 为什么需要进程池
- 一次性开启指定数量的进程
- 如果有十个进程,有一百个任务,一次可以处理多少个(一次性只能处理十个)
- 防止进程开启数量过多导致服务器压力过大
- 线程
- 有了进程为什么还需要线程
- 因为进程不能同一时间只能做一个事情
- 什么是线程
- 线程是操作系统调度的最小单位
- 线程是进程正真的执行者,是一些指令的集合(进程资源的拥有者)
- 同一个进程下的读多个线程共享内存空间,数据直接访问(数据共享)
- 为了保证数据安全,必须使用线程锁
- GIL全局解释器锁
- 在python全局解释器下,保证同一时间只有一个线程运行
- 防止多个线程都修改数据
- 线程锁(互斥锁)
- GIL锁只能保证同一时间只能有一个线程对某个资源操作,但当上一个线程还未执行完毕时可能就会释放GIL,其他线程就可以操作了
- 线程锁本质把线程中的数据加了一把互斥锁
- mysql中共享锁 & 互斥锁
- mysql共享锁:共享锁,所有线程都能读,而不能写
- mysql排它锁:排它,任何线程读取这个这个数据的权利都没有
- 加上线程锁之后所有其他线程,读都不能读这个数据
- mysql中共享锁 & 互斥锁
- 有了GIL全局解释器锁为什么还需要线程锁
- 因为cpu是分时使用的
- 死锁定义
- 两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去
- 多线程
- 为什么要使用多线程?
- 线程在程序中是独立的、并发的执行流。与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存、文件句柄
- 和其他进程应有的状态。
- 因为线程的划分尺度小于进程,使得多线程程序的并发性高。进程在执行过程之中拥有独立的内存单元,而多个线程共享
- 内存,从而极大的提升了程序的运行效率。
- 线程比进程具有更高的性能,这是由于同一个进程中的线程都有共性,多个线程共享一个进程的虚拟空间。线程的共享环境
- 包括进程代码段、进程的共有数据等,利用这些共享的数据,线程之间很容易实现通信。
- 操作系统在创建进程时,必须为改进程分配独立的内存空间,并分配大量的相关资源,但创建线程则简单得多。因此,使用多线程来实现并发比使用多进程的性能高得要多。
- 总结起来,使用多线程编程具有如下几个优点:?
- 进程之间不能共享内存,但线程之间共享内存非常容易。
- 操作系统在创建进程时,需要为该进程重新分配系统资源,但创建线程的代价则小得多。因此使用多线程来实现多任务并发执行比使用多进程的效率高
- python语言内置了多线程功能支持,而不是单纯地作为底层操作系统的调度方式,从而简化了python的多线程编程。
- 为什么要使用多线程?
- 有了进程为什么还需要线程


import threading import time def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep(3) for i in range(10): t = threading.Thread(target=sayhi,args=('t-%s'%i,)) t.start()
-
- join/setDaemon
- 当一个进程启动之后,会默认产生一个主线程,因为线程是程序执行流的最小单元,当设置多线程时,主线程会创建多个子线程,在python中,默认情况下(其实就是setDaemon(False)),主线程执行完自己的任务以后,就退出了,此时子线程会继续执行自己的任务,直到自己的任务结束。
- 当我们使用setDaemon(True)方法,设置子线程为守护线程时,主线程一旦执行结束,则全部线程全部被终止执行,可能出现的情况就是,子线程的任务还没有完全执行结束,就被迫停止。此时join的作用就凸显出来了,join所完成的工作就是线程同步,即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程在终止。
- join有一个timeout参数:
- 当设置守护线程时,含义是主线程对于子线程等待timeout的时间将会杀死该子线程,最后退出程序。所以说,如果有10个子线程,全部的等待时间就是每个timeout的累加和。简单的来说,就是给每个子线程一个timeout的时间,让他去执行,时间一到,不管任务有没有完成,直接杀死。
- 没有设置守护线程时,主线程将会等待timeout的累加和这样的一段时间,时间一到,主线程结束,但是并没有杀死子线程,子线程依然可以继续执行,直到子线程全部结束,程序退出。线程池
- 对于任务数量不断增加的程序,每有一个任务就生成一个线程,最终会导致线程数量的失控,例如,整站爬虫,假设初始只有一个链接a,那么,这个时候只启动一个线程,运行之后,得到这个链接对应页面上的b,c,d,,,等等新的链接,作为新任务,这个时候,就要为这些新的链接生成新的线程,线程数量暴涨。在之后的运行中,线程数量还会不停的增加,完全无法控制。所以,对于任务数量不端增加的程序,固定线程数量的线程池是必要的。
- join/setDaemon
import threading import time start_time = time.time() def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep(3) t_objs = [] #将进程实例对象存储在这个列表中 for i in range(50): t = threading.Thread(target=sayhi,args=('t-%s'%i,)) t.start() #启动一个线程,程序不会阻塞 t_objs.append(t) print(threading.active_count()) #打印当前活跃进程数量 for t in t_objs: #利用for循环等待上面50个进程全部结束 t.join() #阻塞某个程序 print(threading.current_thread()) #打印执行这个命令进程 print("----------------all threads has finished.....") print(threading.active_count()) print('cost time:',time.time() - start_time)
import threading import time start_time = time.time() def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep(3) for i in range(50): t = threading.Thread(target=sayhi,args=('t-%s'%i,)) t.setDaemon(True) #把当前线程变成守护线程,必须在t.start()前设置 t.start() #启动一个线程,程序不会阻塞 print('cost time:',time.time() - start_time)
import requests from concurrent.futures import ThreadPoolExecutor def fetch_request(url): result = requests.get(url) print(result.text) url_list = [ 'https://www.baidu.com', 'https://www.google.com/', #google页面会卡住,知道页面超时后这个进程才结束 'http://dig.chouti.com/', #chouti页面内容会直接返回,不会等待Google页面的返回 ] pool = ThreadPoolExecutor(10) # 创建一个线程池,最多开10个线程 for url in url_list: pool.submit(fetch_request,url) # 去线程池中获取一个线程,线程去执行fetch_request方法 pool.shutdown(True)
- 协程
- 什么是协程
- 协程微线程,纤程,本质是一个单线程
- 协程能在单线程处理高并发
- 线程遇到I/O操作会等待、阻塞,协程遇到I/O会自动切换(剩下的只有CPU操作)
- 线程的状态保存在CPU的寄存器和栈里而协程拥有自己的空间,所以无需上下文切换的开销,所以快、
- 为甚么协程能够遇到I/O自动切换
- 协程有一个gevent模块(封装了greenlet模块),遇到I/O自动切换
- 协程缺点
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上
- 线程阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
- 协程最大的优点
- 不仅是处理高并发(单线程下处理高并发)
- 特别节省资源(500日活,用php写需要两百多态机器,但是golang只需要二十多太机器)
- 200多台机器一年
- 二十多天机器一年
- 协程为何能处理大并发
- greeenlet遇到I/O手动切换
- 协程遇到I/O操作就切换,其实Gevent模块仅仅是对greenlet的封装,将I/O的手动切换变成自动切换
- 协程之所以快是因为遇到I/O操作就切换(最后只有CPU运算)
- 这里先演示用greenlet实现手动的对各个协程之间切换
- 其实Gevent模块仅仅是对greenlet的再封装,将I/O间的手动切换变成自动切换
- 什么是协程
from greenlet import greenlet def test1(): print(12) #4 gr1会调用test1()先打印12 gr2.switch() #5 然后gr2.switch()就会切换到gr2这个协程 print(34) #8 由于在test2()切换到了gr1,所以gr1又从上次停止的位置开始执行 gr2.switch() #9 在这里又切换到gr2,会再次切换到test2()中执行 def test2(): print(56) #6 启动gr2后会调用test2()打印56 gr1.switch() #7 然后又切换到gr1 print(78) #10 切换到gr2后会接着上次执行,打印78 gr1 = greenlet(test1) #1 启动一个协程gr1 gr2 = greenlet(test2) #2 启动第二个协程gr2 gr1.switch() #3 首先gr1.switch() 就会去执行gr1这个协程
-
-
- Gevent遇到I/O自动切换
- Gevent是一个第三方库,可以通过gevent实现并发同步或异步编程,Gevent原理是只要是遇到I/O操作就自动切换下一个协程
- Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程
- 在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程
- Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
- Gevent原理是只要遇到I/O操作就会自动切换到下一个协程
-
from urllib import request import gevent,time from gevent import monkey monkey.patch_all() #把当前程序所有的I/O操作给我单独做上标记 def f(url): print('GET: %s' % url) resp = request.urlopen(url) data = resp.read() print('%d bytes received from %s.' % (len(data), url)) #1 并发执行部分 time_binxing = time.time() gevent.joinall([ gevent.spawn(f, 'https://www.python.org/'), gevent.spawn(f, 'https://www.yahoo.com/'), gevent.spawn(f, 'https://github.com/'), ]) print("并行时间:",time.time()-time_binxing) #2 串行部分 time_chuanxing = time.time() urls = [ 'https://www.python.org/', 'https://www.yahoo.com/', 'https://github.com/', ] for url in urls: f(url) print("串行时间:",time.time()-time_chuanxing) # 注:为什么要在文件开通使用monkey.patch_all() # 1. 因为有很多模块在使用I / O操作时Gevent是无法捕获的,所以为了使Gevent能够识别出程序中的I / O操作。 # 2. 就必须使用Gevent模块的monkey模块,把当前程序所有的I / O操作给我单独做上标记 # 3.使用monkey做标记仅用两步即可: 第一步(导入monkey模块): from gevent import monkey 第二步(声明做标记) : monkey.patch_all()
- Gevent实现简单的自动切换小例子
- 注:在Gevent模仿I/O切换的时候,只要遇到I/O就会切换,哪怕gevent.sleep(0)也要切换一次
import gevent def func1(): print('�33[31;1m第一次打印�33[0m') gevent.sleep(2) # 为什么用gevent.sleep()而不是time.sleep()因为是为了模仿I/O print('�33[31;1m第六次打印�33[0m') def func2(): print('�33[32;1m第二次打印�33[0m') gevent.sleep(1) print('�33[32;1m第四次打印�33[0m') def func3(): print('�33[32;1m第三次打印�33[0m') gevent.sleep(1) print('�33[32;1m第五次打印�33[0m') gevent.joinall([ # 将要启动的多个协程放到event.joinall的列表中,即可实现自动切换 gevent.spawn(func1), # gevent.spawn(func1)启动这个协程 gevent.spawn(func2), gevent.spawn(func3), ]) # 运行结果: # 第一次打印 # 第二次打印 # 第三次打印 # 第四次打印 # 第五次打印 # 第六次打印
-
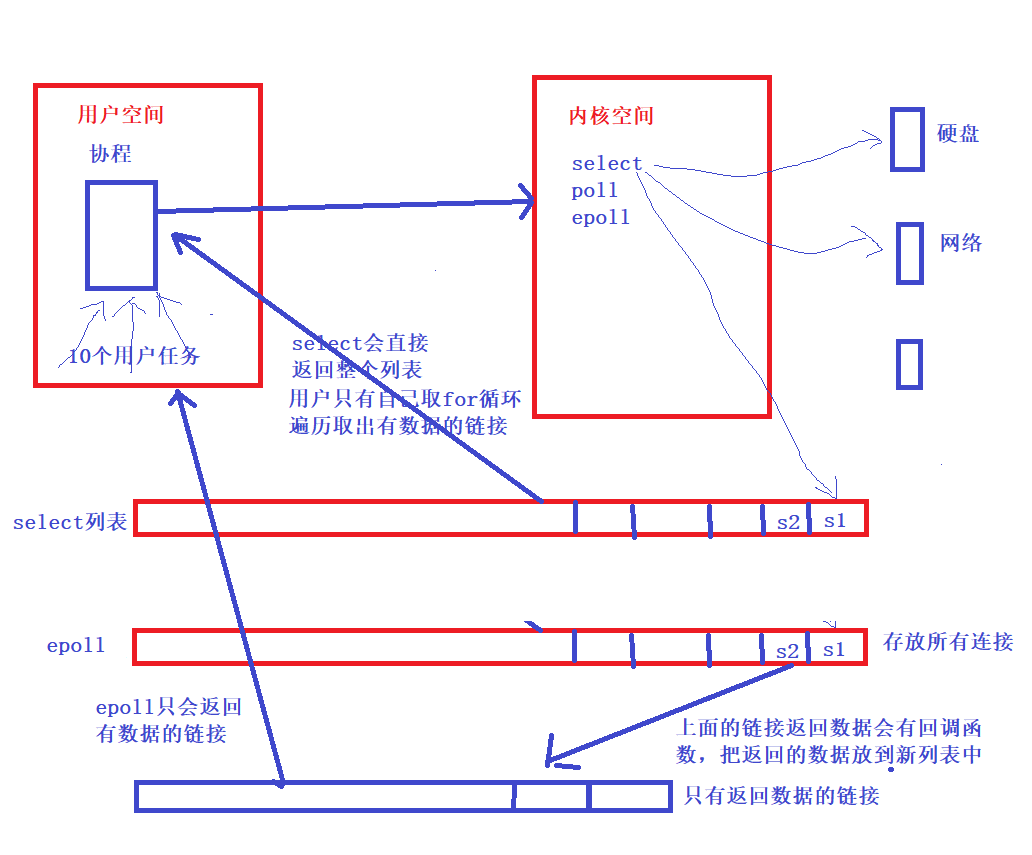
- select、epool、pool
- I/O的实质是什么?
- I/O的实质是将硬盘中的数据,或收到的数据实现从内核态 copy到 用户态的过程
- 本文讨论的背景是Linux环境下的network IO。
- 比如微信读取本地硬盘的过程
- 微信进程会发送一个读取硬盘的请求----》操作系统
- 只有内核才能够读取硬盘中的数据---》数据返回给微信程序(看上去就好像是微信直接读取)
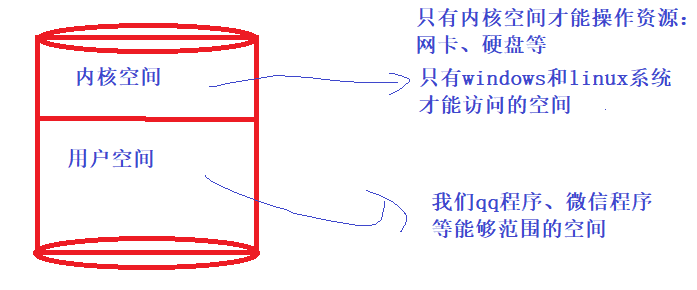
- 用户态 & 内核态
- 系统空间分为两个部分,一部分是内核态,一部分是用户态的部分
- 内核态:内核态的空间资源只有操作系统能够访问
- 用户态:我们写的普通程序使用的空间
- select、epool、pool
-
- select
- 只能处理1024个连接(每一个请求都可以理解为一个连接)
- 不能告诉用户程序,哪一个连接是活跃的
- pool
- 只是取消了最大1024个活跃的限制
- 不能告诉用户程序,哪一个连接是活跃的
- epool
- 不仅取消了1024这个最大连接限制
- 而且能告诉用户程序哪一个是活跃的
- select
-
- 猴子补丁
- monkey patch指的是在运行时动态替换,一般是在startup的时候.
- 用过gevent就会知道,会在最开头的地方gevent.monkey.patch_all();把标准库中的thread/socket等给替换掉.这样我们在后面使用socket的时候可以跟平常一样使用,无需修改任何代码,但是它变成非阻塞的了
- 猴子补丁
- 装饰器
-
- 什么是装饰器
- 装饰器本质是函数,用来给其他函数添加新的功能
- 特点:不修改调用方式、不修改源代码
- 装饰器的应用场景
- 用户认证,判断用户是否登录
- 计算函数运行时间(算是一个功能、在项目里用的不多)
- 插入日志的时候
- redis缓存
- 为什么使用装饰器
- 结合应用场景说需求
- 如何使用装饰器
- 装饰器求函数运行时间
- Python 闭包
-
- 当一个嵌套函数在其外部区域引用了一个值时,该嵌套函数就是一个闭包。其意义就是会记录这个值。
- 什么是装饰器
def A(x): def B(): print(x) return B
deco(*args,**kwargs): start_time = time.time() func(*args,**kwargs) #run test1 stop_time = time.time() print("running time is %s"%(stop_time-start_time)) return deco # @timer # test1=timer(test1) def test1(): time.sleep(3) print("in the test1") test1()
#! /usr/bin/env python # -*- coding: utf-8 -*- import time def auth(auth_type): print("auth func:",auth_type) def outer_wrapper(func): def wrapper(*args, **kwargs): print("wrapper func args:", *args, **kwargs) print('运行前') func(*args, **kwargs) print('运行后') return wrapper return outer_wrapper @auth(auth_type="local") # home = wrapper() def home(): print("welcome to home page") return "from home" home()
- 生成器
- 什么是生成器
- 生成器就是一个特殊的迭代器
- 一个有yield关键字的函数就是一个生成器
- 生成器是这样一个函数,它记住上一次返回时在函数体中的位置。
- 对生成器函数的第二次(或第 n 次)调用跳转至该函数中间,而上次调用的所有局部变量都保持不变。
- yield简单说来就是一个生成器,这样函数它记住上次返 回时在函数体中的位置。对生成器第 二次(或n 次)调用跳转至该函 次)调用跳转至该函数。
- 生成器哪些场景应用
- 生成器是一个概念,我们平常写代码可能用的并不多,但是python源码大量使用
- 比如我们tornado框架就是基于 生成器+协程
- 在我们代码中使用举例
- 比如我们要生成一百万个数据,如果用生成器非常节省空间,用列表浪费大量空间
- 什么是生成器
import time t1 = time.time() g = (i for i in range(100000000)) t2 = time.time() lst = [i for i in range(100000000)] t3 = time.time() print('生成器时间:',t2 - t1) # 生成器时间: 0.0 print('列表时间:',t3 - t2) # 列表时间: 5.821957349777222
-
- 为什么使用生成器
- 节省空间
- 高效
- 如何使用
- 为什么使用生成器
#!/usr/bin/python # -*- coding: utf-8 -*- def read_big_file_v(fname): block_size = 1024 * 8 with open(fname,encoding="utf8") as fp: while True: chunk = fp.read(block_size) # 当文件没有更多内容时,read 调用将会返回空字符串 '' if not chunk: break print(chunk) path = r'C:aaalutingedc-backend ttt.py' read_big_file_v(path)
- 迭代器
-
- 什么是迭代器
- 迭代器是访问集合内元素的一种方法
- 总是从集合内第一个元素访问,直到所有元素都被访问过结束,当调用 __next__而元素返回会引发一个,StopIteration异常
- 有两个方法:_iter_ _next_
- _iter_ : 返回迭代器自身
- _next_: 返回下一个元素
- 可迭代对象
- 内置iter方法的,都是可迭代的对象。 list是可迭代对象,dict是可迭代对象,set也是可迭代对象
- 定义
- 迭代器:可迭代对象执行iter方法,得到的结果就是迭代器,迭代器对象有next方法
- 它是一个带状态的对象,他能在你调用next()方法的时候返回容器中的下一个值,任何实现了iter和next()方法的对象都是迭代器,iter返回迭代器自身,next返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常
- 什么是迭代器
Python 面向对象
- 什么是面向对象
- 使用模板的思想,将世界完事万物使用对象来表示一个类型
- 方法
- 静态方法
- 特点:名义上归类管理,实际上不能访问类或者变量中的任意属性或者方法
- 作用:让我们代码清晰,更好管理
- 调用方式: 既可以被类直接调用,也可以通过实例调用
- 类方法
- 作用:无需实例化直接被类调用
- 特性:类方法只能访问类变量,不能访问实例变量
- 类方法使用场景:当我们还未创建实例,但是需要调用类中的方法
- 调用方式:既可以被类直接调用,也可以通过实例调用
- 属性方法
- 属性方法把一个方法变成一个属性,隐藏了实现细节,调用时不必加括号直接d.eat即可调用self.eat()方
- 魔法方法
- 单例模式
- 单例模式:永远用一个对象得实例,避免新建太多实例浪费资源
- 实质:使用__new__方法新建类对象时先判断是否已经建立过,如果建过就使用已有的对象
- 使用场景:如果每个对象内部封装的值都相同就可以用单例模式
- 单例模式
- 静态方法
class Foo(object): instance = None def __init__(self): self.name = 'alex' def __new__(cls, *args, **kwargs): if Foo.instance: return Foo.instance else: Foo.instance = object.__new__(cls,*args,**kwargs) return Foo.instance obj1 = Foo() # obj1和obj2获取的就是__new__方法返回的内容 obj2 = Foo() print(obj1,obj2) # 运行结果: <__main__.Foo object at 0x00D3B450>
<__main__.Foo object at 0x00D3B450> # 运行结果说明: # 这可以看到我们新建的两个Foo()对象内存地址相同,说明使用的•同一个类,没有重复建立类
-
- __new__
- 产生一个实例
- __init__
- 产生一个对象
- __del__
- 析构方法,删除无用的内存对象(当程序结束会自动执行析构方法)
- __new__
- 特性
- 封装
- 对类中属性和方法进行一种封装,隐藏了实现细节
- 继承
- 之类继承父类后,就具有了父类的所有属性和方法,先继承,后重写
- 多态
- 一种接口,多种表现形状
- 中国人、和美国人都能讲话,调用中国人类讲中文,调用美国人类讲英文
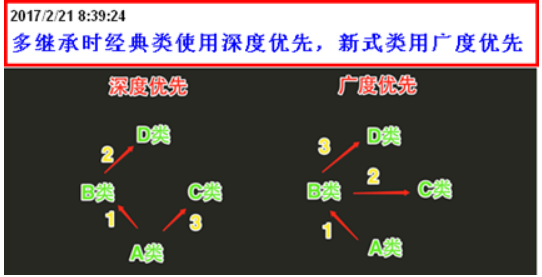
- 新式类经典类的区别
- pythn3无论新式类还是经典类都是用 广度优先
- python2中,新式类:广度优先,经典类:深度优先
- 封装
class D: def talk(self): print('D') class B(D): pass # def talk(self): # print('B') class C(D): pass def talk(self): print('C') class A(B,C): pass # def talk(self): # print('A') a = A() a.talk()
- 属性
- 公有属性(类变量)
- 如果函数、方法或者属性的名称没有以两个下划线开始,则为公有属性;
- 普通属性(实例变量)
- 以self作为前缀的属性;
- 私有属性
- 函数、方法或者属性的名称以两个下划线开始,则为私有类型;
- 局部变量
- 类的方法中定义的变量没有使用self作为前缀声明,则该变量为局部变量;
- 公有属性(类变量)
- 反射
- hasattr: 判断当前类是否有这个方法
- getattr: 通过字符串反射出这个方法的内存地址
- setattr:将当前类添加一个方法
- delatrr: 删除实例属性
Python 常识概念
- 深浅拷贝
- 底层原理
- 浅copy: 不管多么复杂的数据结构,浅拷贝都只会copy一层
- deepcopy : 深拷贝会完全复制原变量相关的所有数据,在内存中生成一套完全一样的内容,我们对这两个变量中任意一个修改都不会影响其他变量
- 底层原理

-
- 可变与不可变数据的区别
- 可变类型(mutable):列表,字典
- 不可变类型(unmutable):数字,字符串,元组
- 这里的可变不可变,是指内存中的那块内容(value)是否可以被改变。如果是不可变类型,在对对象本身操作的时候,必须在内存中新申请一块区域(因为老区域#不可变#)。如果是可变类型,对对象操作的时候,不需要再在其他地方申请内存,只需要在此对象后面连续申请(+/-)即可,也就是它的address会保持不变,但区域会变长或者变短。
- copy.copy() 浅拷贝
- copy.deepcopy() 深拷贝
- 浅拷贝是新创建了一个跟原对象一样的类型,但是其内容是对原对象元素的引用。这个拷贝的对象本身是新的,但内容不是。拷贝序列类型对象(列表元组)时,默认是浅拷贝。
- 可变与不可变数据的区别
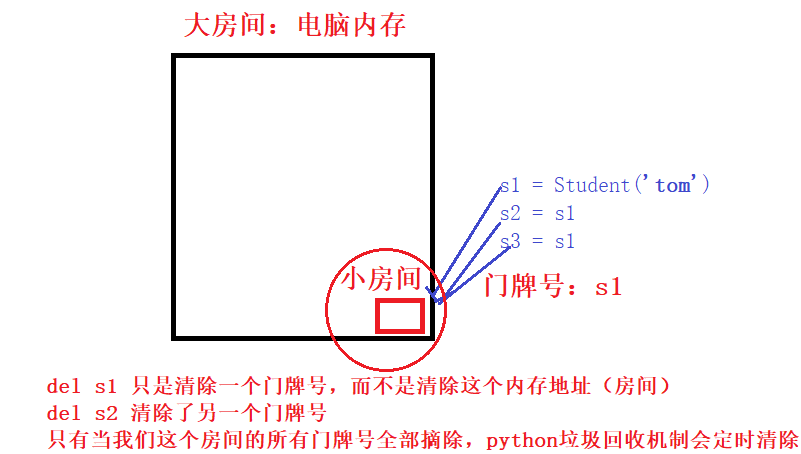
- 垃圾回收机制
- 引用计数
- 原理
- 当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1.
- 当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
- 优点
- 引用计数有一个很大的优点,即实时性,任何内存,一旦没有指向它的引用,就会被立即回收,而其他的垃圾收集技术必须在某种特殊条件下才能进行无效内存的回收。
- 缺点
- 引用计数机制所带来的维护引用计数的额外操作与Python运行中所进行的内存分配和释放,引用赋值的次数是成正比的,
- 显然比其它那些垃圾收集技术所带来的额外操作只是与待回收的内存数量有关的效率要低。
- 同时,因为对象之间相互引用,每个对象的引用都不会为0,所以这些对象所占用的内存始终都不会被释放掉。
- 原理
- 标记清楚
- 它分为两个阶段:第一阶段是标记阶段,GC会把所有的活动对象打上标记,第二阶段是把那些没有标记的对象非活动对象进行回收。
- 对象之间通过引用(指针)连在一起,构成一个有向图
- 从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。
- 根对象就是全局变量、调用栈、寄存器。
- 引用计数
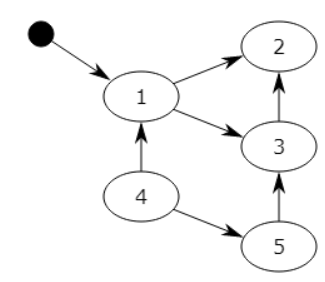
-
-
- 在上图中,可以从程序变量直接访问块1,并且可以间接访问块2和3,程序无法访问块4和5
- 第一步将标记块1,并记住块2和3以供稍后处理。
- 第二步将标记块2,第三步将标记块3,但不记得块2,因为它已被标记。
- 扫描阶段将忽略块1,2和3,因为它们已被标记,但会回收块4和5。
- 分代回收
- 分代回收是建立在标记清除技术基础之上的,是一种以空间换时间的操作方式。
- Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代)
- 他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
- 新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发
- 把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推
- 老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
-
- TCP/UDP
- TCP/UDP比较
- TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
- TCP提供可靠的服务,也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
- TCP通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。
- UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
- 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
- TCP对系统资源要求较多,UDP对系统资源要求较少。
- 注:UDP一般用于即时通信(QQ聊天 对数据准确性和丢包要求比较低,但速度必须快),在线视频等
- 三次挥手四次握手
- 三次握手:
- 第一次握手:建立连接时,客户端发送SYN包到服务器,其中包含客户端的初始序号seq=x,并进入SYN_SENT状态,等待服务器确认。
- 第二次握手:服务器收到请求后,必须确认客户的数据包。同时自己也发送一个SYN包,即SYN+ACK包,此时服务器进入SYN_RECV状态。
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送一个序列号(seq=x+1),确认号为ack(客户端)=y+1,此包发送完毕,
- 客户端和服务器进入ESTAB_LISHED(TCP连接成功)状态,完成三次握手。
- 四次挥手:
- 第一次挥手:首先,客户端发送一个FIN,用来关闭客户端到服务器的数据传送,然后等待服务器的确认。其中终止标志位FIN=1,序列号seq=u。
- 第二次挥手:服务器收到这个FIN,它发送一个ACK,确认ack为收到的序号加一。
- 第三次挥手:关闭服务器到客户端的连接,发送一个FIN给客户端。
- 第四次挥手:客户端收到FIN后,并发回一个ACK报文确认,并将确认序号seq设置为收到序号加一。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
- 三次握手:
- 相关的问题
- 为什么需要三次握手?
- 目的:为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。主要防止资源的浪费。
- 具体过程:当客户端发出第一个连接请求报文段时并没有丢失,而是在某个网络节点出现了长时间的滞留,以至于延误了连接请求在某个时间之后才到达服务器。这应该是一个早已失效的报文段。但是服务器在收到此失效的连接请求报文段后,以为是客户端的一个新请求,于是就想客户端发出了确认报文段,同意建立连接。假设不采用三次握手,那么只要服务器发出确认后,新的连接就可以建立了。但是由于客户端没有发出建立连接的请求,因此不会管服务器的确认,也不会向服务器发送数据,但服务器却以为新的运输连接已经建立,一直在等待,所以,服务器的资源就白白浪费掉了。
- 如果在TCP第三次握手中的报文段丢失了会出现什么情况?
- 客户端会认为此连接已建立,如果客户端向服务器发送数据,服务器将以RST包响应,这样就能感知到服务器的错误了。
- 为什么要四次挥手?
- 为了保证在最后断开的时候,客户端能够发送最后一个ACK报文段能够被服务器接收到。如果客户端在收到服务器给它的断开连接的请求之后,回应完服务器就直接断开连接的话,若服务器没有收到回应就无法进入CLOSE状态,所以客户端要等待两个最长报文段寿命的时间,以便于服务器没有收到请求之后重新发送请求。
- 防止“已失效的连接请求报文”出现在连接中,在释放连接的过程中会有一些无效的滞留报文,这些报文在经过2MSL的时间内就可以发送到目的地,不会滞留在网络中。这样就可以避免在下一个连接中出现上一个连接的滞留报文了。
- 为什么TCP连接的时候是3次?2次不可以吗?
- 因为需要考虑连接时丢包的问题,如果只握手2次,第二次握手时如果服务端发给客户端的确认报文段丢失,此时服务端已经准备好了收发数(可以理解服务端已经连接成功)据,而客户端一直没收到服务端的确认报文,所以客户端就不知道服务端是否已经准备好了(可以理解为客户端未连接成功),这种情况下客户端不会给服务端发数据,也会忽略服务端发过来的数据。
- 如果是三次握手,即便发生丢包也不会有问题,比如如果第三次握手客户端发的确认ack报文丢失,服务端在一段时间内没有收到确认ack报文的话就会重新进行第二次握手,也就是服务端会重发SYN报文段,客户端收到重发的报文段后会再次给服务端发送确认ack报文。
- 为什么TCP连接的时候是3次,关闭的时候却是4次?
-
- 因为只有在客户端和服务端都没有数据要发送的时候才能断开TCP。而客户端发出FIN报文时只能保证客户端没有数据发了,服务端还有没有数据发客户端是不知道的。而服务端收到客户端的FIN报文后只能先回复客户端一个确认报文来告诉客户端我服务端已经收到你的FIN报文了,但我服务端还有一些数据没发完,等这些数据发完了服务端才能给客户端发FIN报文(所以不能一次性将确认报文和FIN报文发给客户端,就是这里多出来了一次)。
- 为什么客户端发出第四次挥手的确认报文后要等2MSL的时间才能释放TCP连接?
- 这里同样是要考虑丢包的问题,如果第四次挥手的报文丢失,服务端没收到确认ack报文就会重发第三次挥手的报文,这样报文一去一回最长时间就是2MSL,所以需要等这么长时间来确认服务端确实已经收到了。
- 如果已经建立了连接,但是客户端突然出现故障了怎么办?
- TCP设有一个保活计时器,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
- 为什么需要三次握手?
- TCP/UDP比较
高阶函数
-
- map
- 第一个参数接收一个函数名,第二个参数接收一个可迭代对象
- 利用map,lambda表达式将所有偶数元素加100
# -*- coding:utf8 -*- l1= [11,22,33,44,55] ret = map(lambda x:x-100 if x % 2 != 0 else x + 100,l1) print(list(ret)) # 运行结果: [-89, 122, -67, 144, -45] # lambda x:x-100 if x % 2 != 0 else x + 100 # 如果 "if x % 2 != 0" 条件成立返回 x-100 # 不成立:返回 x+100 def F(x): if x%2 != 0: return x-100 else: return x+100 ret = map(F,l1) print(list(ret))
-
- reduce
- 字符串反转
- 把上一次的执行结果单做参数返回
# -*- coding:utf8 -*- '''使用reduce将字符串反转''' s = 'Hello World' from functools import reduce result = reduce(lambda x,y:y+x,s) # # 1、第一次:x=H,y=e => y+x = eH # # 2、第二次:x=l,y=eH => y+x = leH # # 3、第三次:x=l,y=leH => y+x = lleH print( result ) # dlroW olleH
-
- filter
- filter()函数可以对序列做过滤处理,就是说可以使用一个自定的函数过滤一个序列,把序列的每一项传到自定义的过滤函数里处理,并返回结果做过滤。
- 最终一次性返回过滤后的结果。
- filter()函数有两个参数:
- 第一个,自定函数名,必须的
- 第二个,需要过滤的列,也是必须的
- filter()函数有两个参数:
- 利用 filter、lambda表达式 获取l1中元素小于33的所有元素 l1 = [11, 22, 33, 44, 55]
- filter
l1= [11,22,33,44,55] a = filter(lambda x: x<33, l1) print(list(a)) # -*- coding:utf8 -*- def F(x): if x<33: return x b = filter(F,l1) print(list(b))
-
- sorted
- 经典面试题只 列表排序
- sorted
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)] # [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)] print( sorted(students, key=lambda s: s[2], reverse=False) ) # 按年龄排序 # 结果:[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)] def f(x): # ('john', 'A', 15) return x[2] print( sorted(students, key=f, reverse=False) ) # 按年龄排序
-
-
- 对字典的value排序
-
d = {'k1':1, 'k3': 3, 'k2':2}
# d.items() = [('k1', 1), ('k3', 3), ('k2', 2)]
a = sorted(d.items(), key=lambda x: x[1])
print(a) # [('k1', 1), ('k2', 2), ('k3', 3)]
-
-
- 两个列表编一个字典
-
L1 = ['k1','k2','k3'] L2 = ['v1','v2','v3'] print( list(zip(L1,L2))) # zip(L1,L2) : [('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')] # dict( [('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')] ) = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
-
-
- 匿名函数
-
(x,y,z): return x+y+z f = lambda x:x if x % 2 != 0 else x + 100 print(f(10)) # 110
-
-
- 三元运算
-
name = 'Tom' if 1 == 1 else 'fly' print(omname) # 运行结果: T
- 读写文件
- ReadLine():逐行读取,适合读大文件
- Readlines():一次性读取所有文件, 将文件按行读取成列表
- read():指定读取指定大小的文件(默认一次读取所有)
- 经典面试题:现在有一个5G的文件,用python写入另一个文件里
- 我们使用了一个 while 循环来读取文件内容,每次最多读取 8kb 大小
- 这样可以避免之前需要拼接一个巨大字符串的过程,把内存占用降低非常多
#!/usr/bin/python # -*- coding: utf-8 -*- def read_big_file_v(fname): block_size = 1024 * 8 with open(fname,encoding="utf8") as fp: while True: chunk = fp.read(block_size) # 当文件没有更多内容时,read 调用将会返回空字符串 '' if not chunk: break print(chunk) path = r'C:aaalutingedc-backend ttt.py' read_big_file_v(path)
- 常用模块
- subprocess模块
- subprocess原理以及常用的封装函数
- 运行python的时候,我们都是在创建并运行一个进程。像Linux进程那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序
- 在Python中,我们通过标准库中的subprocess包来fork一个子进程,并运行一个外部的程序。
- subprocess包中定义有数个创建子进程的函数,这些函数分别以不同的方式创建子进程,所以我们可以根据需要来从中选取一个使用
- 另外subprocess还提供了一些管理标准流(standard stream)和管道(pipe)的工具,从而在进程间使用文本通信。
- subprocess原理以及常用的封装函数
- subprocess模块
#1、返回执行状态:0 执行成功 retcode = subprocess.call(['ping', 'www.baidu.com', '-c5']) #2、返回执行状态:0 执行成功,否则抛异常 subprocess.check_call(["ls", "-l"]) #3、执行结果为元组:第1个元素是执行状态,第2个是命令结果 >>> ret = subprocess.getstatusoutput('pwd') >>> ret (0, '/test01') #4、返回结果为 字符串 类型 >>> ret = subprocess.getoutput('ls -a') >>> ret '. .. test.py' #5、返回结果为'bytes'类型 >>> res=subprocess.check_output(['ls','-l']) >>> res.decode('utf8') '总用量 4 -rwxrwxrwx. 1 root root 334 11月 21 09:02 test.py '
subprocess.check_output(['chmod', '+x', filepath]) subprocess.check_output(['dos2unix', filepath])
-
- subprocess.Popen()
- 实际上,上面的几个函数都是基于Popen()的封装(wrapper),这些封装的目的在于让我们容易使用子进程
- 当我们想要更个性化我们的需求的时候,就要转向Popen类,该类生成的对象用来代表子进程
- 与上面的封装不同,Popen对象创建后,主程序不会自动等待子进程完成。我们必须调用对象的wait()方法,父进程才会等待 (也就是阻塞block)
- 从运行结果中看到,父进程在开启子进程之后并没有等待child的完成,而是直接运行print。
- subprocess.Popen()
#1、先打印'parent process'不等待child的完成 import subprocess child = subprocess.Popen(['ping','-c','4','www.baidu.com']) print('parent process') #2、后打印'parent process'等待child的完成 import subprocess child = subprocess.Popen('ping -c4 www.baidu.com',shell=True) child.wait() print('parent process')
child.poll() # 检查子进程状态 child.kill() # 终止子进程 child.send_signal() # 向子进程发送信号 child.terminate() # 终止子进程
-
- subprocess.PIPE 将多个子进程的输入和输出连接在一起
- subprocess.PIPE实际上为文本流提供一个缓存区。child1的stdout将文本输出到缓存区,随后child2的stdin从该PIPE中将文本读取走
- child2的输出文本也被存放在PIPE中,直到communicate()方法从PIPE中读取出PIPE中的文本。
- 注意:communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成
- subprocess.PIPE 将多个子进程的输入和输出连接在一起
import subprocess #下面执行命令等价于: cat /etc/passwd | grep root child1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE) child2 = subprocess.Popen(["grep","root"],stdin=child1.stdout, stdout=subprocess.PIPE) out = child2.communicate() #返回执行结果是元组 print(out) #执行结果: (b'root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin ', None)
import subprocess list_tmp = [] def main(): p = subprocess.Popen(['ping', 'www.baidu.com', '-c5'], stdin = subprocess.PIPE, stdout = subprocess.PIPE) while subprocess.Popen.poll(p) == None: r = p.stdout.readline().strip().decode('utf-8') if r: # print(r) v = p.stdout.read().strip().decode('utf-8') list_tmp.append(v) main() print(list_tmp[0])
-
- paramiko模块(详细介绍)
- Paramiko模块作用
- 如果需要使用SSH从一个平台连接到另外一个平台,进行一系列的操作时,
- 比如:批量执行命令,批量上传文件等操作,paramiko是最佳工具之一。
- paramiko是用python语言写的一个模块,遵循SSH2协议,支持以加密和认证的方式,进行远程服务器的连接
- 由于使用的是python这样的能够跨平台运行的语言,所以所有python支持的平台,如Linux, Solaris, BSD,MacOS X, Windows等,paramiko都可以支持
- 如果需要使用SSH从一个平台连接到另外一个平台,进行一系列的操作时,paramiko是最佳工具之一
- 现在如果需要从windows服务器上下载Linux服务器文件:
- a. 使用paramiko可以很好的解决以上问题,它仅需要在本地上安装相应的软件(python以及PyCrypto)
- b. 对远程服务器没有配置要求,对于连接多台服务器,进行复杂的连接操作特别有帮助。
- Paramiko模块作用
- re模块(详细介绍)
- paramiko模块(详细介绍)
|
函数 |
描述 |
|
compile(pattern[, flags]) |
根据正则表达式字符串创建模式对象 |
|
search(pattern, string[, flags]) |
在字符串中寻找模式 |
|
match(pattern, 常用模块[, flags]) |
在字符串的开始处匹配模式 |
|
split(pattern, string[, maxsplit=0]) |
根据模式的匹配项来分割字符串 |
|
findall(pattern, string) |
列出字符串中模式的所有匹配项并以列表返回 |
|
sub(pat, repl, string[, count=0]) |
将字符串中所有pat的匹配项用repl替换 |
|
escape(string) |
将字符串中所有特殊正则表达式字符转义 |
- Python2和Python3的区别
- 不等于<>比较运算符,python3不识别,pyhon2.7中!=和<>都能运行。
- print函数的使用,python3必须加括号,python2加不加都行。
- python2 的默认编码是ASCII,python3的默认编码是UTF-8。
- python3字符串解码后会在内存里自动转换成Unicode,而python2不会。如果在文件头指定了解码编码,python2和python3都会按指定解码,所有系统都支持Unicode,所以python3只要指定对了解码编码,在哪个系统上都可以正常显示,python2如果不是gbk编码的,解码后windous就会是乱码。
- python2中有Unicode数据类型,python3中没有,字符串都是Unicode格式的str数据类型。
- 用户输入不同,python3中只有input()输出都是str和python2中的raw_input()一样,而python2中也有input(),输入字符串要带引号,数字输出相应的数字类型
- python2以前没有布尔型,0表示False,用1表示True;Python3 把 True 和 False 定义成关键字,它们的值还是 1 和 0,可以和数字运算。
- python2的除法中不是浮点数则只返回商,python3除法返回值正常。
- python3运行程序可以识别相同目录下普通文件夹中的模块,python2只能识别文件夹标识后的包中的模块。
- 创建类时,python2分为经典类和新式类,新式类就是继承object的类,经典类是没有继承的类,而python3中全部是新式类,默认继承object。在属性查找时,经典类查找方式为深度优先,新式类是广度优先。仅python3中有类的mro函数方法,输出继承父类的顺序列表。
- with(上下文管理)
- 上下文管理器对象存在的目的是管理 with 语句,就像迭代器的存在是为了管理 for 语句一样。
- with 语句的目的是简化 try/finally 模式。这种模式用于保证一段代码运行完毕后执行某项操作,即便那段代码由于异常、 return 语句或 sys.exit() 调用而中止,也会执行指定的操作。 finally 子句中的代码通常用于释放重要的资源,或者还原临时变更的状态。
- ==上下文管理器协议包含enter和exit两个方法==。 with 语句开始运行时,会在上下文管理器对象上调用enter方法。 with 语句运行结束后,会在上下文管理器对象上调用exit方法,以此扮演 finally 子句的角色。
- ==执行 with 后面的表达式得到的结果是上下文管理器对象,把值绑定到目标变量上(as 子句)是在上下文管理器对象上调用enter方法的结果==。with 语句的 as 子句是可选的。对 open 函数来说,必须加上 as子句,以便获取文件的引用。不过,有些上下文管理器会返回 None,因为没什么有用的对象能提供给用户。
- is和==比较
- 基本要素
- id(身份标识)
- type(数据类型)
- value(值)。
- is和==都是对对象进行比较判断作用的,但对对象比较判断的内容并不相同。
- ==比较操作符和is同一性运算符区别
- ==是python标准操作符中的比较操作符,用来比较判断两个对象的value(值)是否相等,例如下面两个字符串间的比较:
- 基本要素
# >> a = 'yms' # >> b = 'yms' # >> a == b # True
-
- is也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同。
>> x = y = [4,5,6] >> z = [4,5,6] >> x == y True >> x == z True >> x is y True >> x is z False >> >> print id(x) 3075326572 >> print id(y) 3075326572 >> print id(z) 3075328140
-
- 前三个例子都是True,这什么最后一个是False呢?x、y和z的值是相同的,所以前两个是True没有问题。至于最后一个为什么是False,看看三个对象的id分别是什么就会明白了。
- 下面再来看一个例子,同一类型下的a和b的(a==b)都是为True,而(a is b)则不然。
>> a = 1 #a和b为数值类型 >> b = 1 >> a is b True >> id(a) 14318944 >> id(b) 14318944 >> a = 'cheesezh' #a和b为字符串类型 >> b = 'cheesezh' >> a is b True >> id(a) 42111872 >> id(b) 42111872 >> a = (1,2,3) #a和b为元组类型 >> b = (1,2,3) >> a is b False >> id(a) 15001280 >> id(b) 14790408 >> a = [1,2,3] #a和b为list类型 >> b = [1,2,3] >> a is b False >> id(a) 42091624 >> id(b) 42082016 >> a = {'cheese':1,'zh':2} #a和b为dict类型 >> b = {'cheese':1,'zh':2} >> a is b False >> id(a) 42101616 >> id(b) 42098736 >> a = set([1,2,3])#a和b为set类型 >> b = set([1,2,3]) >> a is b False >> id(a) 14819976 >> id(b) 14822256
- 通过以上三个示例可以看出,只有数值型和字符串型的情况下,a is b才为True,当a和b是tuple,list,dict或set型时,a is b为False
 Python基础到此就分解完了,有不足的地方请留言,多多支持,持续更新中哦!!
Python基础到此就分解完了,有不足的地方请留言,多多支持,持续更新中哦!!