1. 操作系统发展史:
1. 手工操作--穿孔卡片:程序员将对应于程序和数据的已穿孔的纸带(或卡片)装入输入机,然后启动输入机把程序和数据输入计算机内存,接着通过控制台开关启动程序针对数据运行;计算完毕,打印机输出计算结果;用户取走结果并卸下纸带(或卡片)后,才让下一个用户上机。
特点:1:用户独占全机。不会出现因资源已被其他用户占用而等待的现象,但资源的利用率低。
2: CPU 等待手工操作。CPU的利用不充分
2. 联机批处理系统:作业的I/O由CPU来处理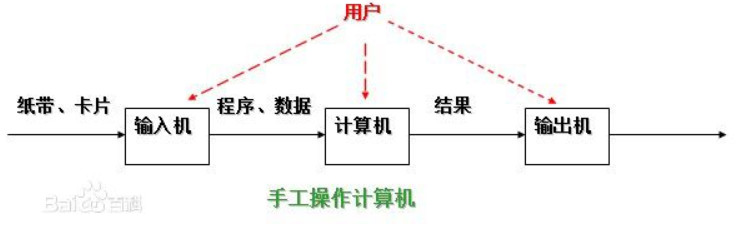
3. 多道程序系统: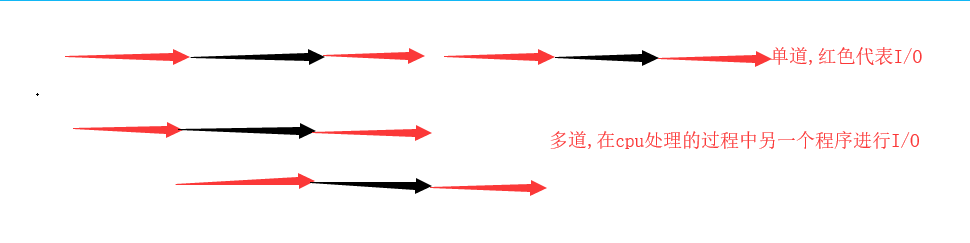
多道技术实现了空间上的复用与时间上的复用,提高了cpu的利用率
1:空间上的复用: 多个程序公用一套计算机硬件
2: 时间上的复用: 切换加保存状态
1.当一个程序遇到IO操作,操作系统会剥夺该程序的CPU执行权限(提高了CPU的利用率,也不影响程序的执行效率
2.当一个程序长时间占用CPU,操作系统也会剥夺该程序的CPU的执行权限(降低了程序的执行效率
2. 进程理论:是系统进行资源分配和调度的基本单位,是对正在运行的程序过程的抽象,程序就是一坨代码,进程就是运行的程序
1.并发与并行
并发: 看起来乡同时运行的程序
并行: 真正意义上的同时执行,单核的计算机不能实现并行,但是可以实现并发
2. 同步异步:任务的提交方式
同步: 任务提交之后,原地等待的任务的执行并拿到返回结果才走,期间什么事情都不做
异步: 任务提交后,不在原地等待,而是继续执行下一行代码,结果通过异步回调拿到
3 阻塞 非阻塞: 表示程序法的运行状态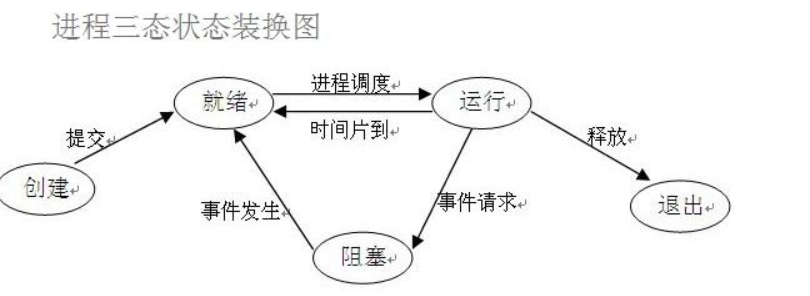
阻塞: 阻塞态
非阻塞: 就绪态,运行态
3. 进程python中代码实现:
1.process 模块介绍: process 是一个创建进程的模块,借助这个模块就可以完成进程的创建
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号 参数介绍: group参数未使用,值始终为None target表示调用对象,即子进程要执行的任务 args表示调用对象的位置参数元组,args=(1,2,'egon',) kwargs表示调用对象的字典,kwargs={'name':'egon','age':18} name为子进程的名称
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了。
2. 创建进程的俩种方式:
import time from multiprocessing import Process def func(i): print('开始创建子进程') time.sleep(i) print('子进程结束') # windows创建进程会将代码以模块的方式 从上往下执行一遍 # linux会直接将代码完完整整的拷贝一份 # windows创建进程一定要在if __name__ == '__main__':代码块内创建 否则报错 if __name__ == '__main__': p = Process(target=func,args=(2,)) # 创建一个进程对象 p.start() # 告诉系统创建一个进程 print("主") # 由于程序执行速度比创建进程快,所以会先输出主然后才看到开始创建 '''主 开始创建子进程 子进程结束 '''
from multiprocessing import Process import time class MyProcess(Process): # 继承Process类 def __init__(self,i): super().__init__() self.i = i def run(self): # 必须定义此方法,start调用的就是此方法 print('开始创建子进程') time.sleep(self.i) print('子进程结束') if __name__ == '__main__': p = MyProcess(1) p.start() print('主')
创建进程就是在内存中重新开辟一块内存空间,将允许产生的代码丢进去,一个进程对应在内存就是一块独立的内存空间
进程与进程之间数据是隔离的 无法直接交互,但是可以通过某些技术实现间接交互
3.join 方法:
import time from multiprocessing import Process def func(name,i): print(f'{name}开始创建子进程') time.sleep(i) print(f'{name}子进程结束') if __name__ == '__main__': p = Process(target=func,args=('111',2,)) p1 = Process(target=func,args=('222',3,)) p2 = Process(target=func,args=('333',1,)) p.start() # 进程的创建顺序是随机的,只是告诉操作系统需要创建一个进程而已 p1.start() p2.start() p.join() # 主进程代码等待子进程运行结束 p1.join() p2.join() print("主") # 先把主进程创建完之后才执行主进程代码
4. 测试进程间的数据是隔离的:
from multiprocessing import Process num = 100 def test(): global num num = 666 if __name__ == '__main__': p = Process(target=test) p.start() p.join() print(num) # 100 还是100证明进程间的数据是相互隔离的,进程是各自在内存中开辟一片各自内存空间
5. 进程对象及其他方法
import time from multiprocessing import Process,current_process import os def test(name,i): print(f'{name}子进程正在创建',os.getpid(),os.getppid()) print(current_process().name) # Process-1 time.sleep(i) print(f'{name}子进程运行结束') if __name__ == '__main__': p = Process(target=test,args=('111',1)) p.start() print(p.is_alive()) # True # p.terminate() # 杀死进程 # time.sleep(2) # print(p.is_alive()) # False # time.sleep(3) p.join() print(p.is_alive()) # False 判断进程是否还活着 print(current_process().name) # MainProcess print('主',os.getpid(),os.getppid()) # os,getpid() 获取进程id ,os,getppid()获取父进程的进程id
6: 守护进程 : 会随着主进程的结束而结束
主进程创建守护进程
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
from multiprocessing import Process import time def test(): print('正在创建') time.sleep(3) print('结束') if __name__ == '__main__': p = Process(target=test) p.daemon = True # 将该进程设置为守护进程,必须放在start前面,否则报错,使用daemon p.start() time.sleep(1) print('主') # 正在创建, 主
7. 互斥锁: 当多个进程操作同一份数据的时候,会造成数据的错乱.这个时候必须进行加锁处理,将并发变成串行,虽然效率降低了,但是提高了数据的安全
注意:锁不要轻易使用,容易造成死锁现象,旨在处理数据的部分枷锁,不要再全局枷锁,锁必须再主进程中产生,交给子进程去使用
抢票代码实例:
from multiprocessing import Process,Lock import json import time def search(name): with open('data','r',encoding='utf-8') as f: data = f.read() num = json.loads(data) print(f'用户{name}查询余票为:{num}') def buy(name): with open('data','r',encoding='utf-8') as f: data = f.read() num = json.loads(data) time.sleep(1) if num > 0: num -= 1 with open('data','w',encoding='utf-8') as f: json.dump(num,f) print(f'{name}抢票成功') else: print('没票了') def run(name,mutex): search(name) mutex.acquire() # 抢锁,只要有人抢到了锁,其他人必须等待此人释放锁 buy(name) mutex.release() # 释放锁 if __name__ == '__main__': mutex = Lock() # 生成锁 for name in range(10): p = Process(target=run,args=(name,mutex)) p.start()
8: 僵尸进程和孤儿进程
僵尸进程:就是之一些进程结束后占用的资源(PID等)没有被回收。自由使用join方法和父进程正常死亡后,才会回收子进程占用资源
孤儿进程:父进程非正常结束,子进程资源没有回收。Windows系统与Linux系统都有‘儿童福利院’,可以回收这些进行资源。
4: 进程间的通信 基于管道与队列 队列:管道+锁 IPC
1.队列: 创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递
Queue([maxsize])
创建共享的进程队列。maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。另外,还需要运行支持线程以便队列中的数据传输到底层管道中。
Queue的实例q具有以下方法:
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)。。
方法介绍
q.close()
关闭队列,防止队列中加入更多数据。调用此方法时,后台线程将继续写入那些已入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果q被垃圾收集,将自动调用此方法。关闭队列不会在队列使用者中生成任何类型的数据结束信号或异常。例如,如果某个使用者正被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
q.cancel_join_thread()
不会再进程退出时自动连接后台线程。这可以防止join_thread()方法阻塞。
q.join_thread()
连接队列的后台线程。此方法用于在调用q.close()方法后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread()方法可以禁止这种行为。
其他方法(了解)
2.队列代码实例:
from multiprocessing import Queue q = Queue(2) q.put(1) # put 添加数据 q.put(2) # q.put(3) # 当队列中数据已满再存不会报错而是原地等待 print(q.full()) # 判断队列使否满 print(q.get()) # 取值.取完后再次获取,程序会阻塞 print(q.get_nowait()) # 取值,不等待直接报错 # full get_nowait empty 不适用与多进程,只适用于单进程 print(q.empty()) # 判断队列中的数据是否为空
3. 进程间通信IPC机制:
from multiprocessing import Process,Queue def func(q): q.put('你好') def func1(q): print(q.get()) if __name__ == '__main__': q = Queue() # 不写值默认最大 p = Process(target=func,args=(q,)) p1 = Process(target=func1,args=(q,)) p.start() p1.start() # 结果 通信成功 # 你好
4.JoinableQueue([maxsize]): 创建可连接的共享进程队列。这就像是一个Queue对象,但队列允许项目的使用者通知生产者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
JoinableQueue的实例p除了与Queue对象相同的方法之外,还具有以下方法:
q.task_done()
使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常。
q.join()
生产者将使用此方法进行阻塞,直到队列中所有项目均被处理。阻塞将持续到为队列中的每个项目均调用q.task_done()方法为止。
下面的例子说明如何建立永远运行的进程,使用和处理队列上的项目。生产者将项目放入队列,并等待它们被处理。
5.生产者消费者模型
from multiprocessing import JoinableQueue,Process import time import random def producer(name,food,q): for i in range(15): data = f'{name}生产了{food} {i}' time.sleep(random.random()) q.put(data) print(data) def consumer(name,q): while 1: date = q.get() if date == None:break print(f'{name}吃了{date}') q.task_done() # #向q.join()发送一次信号,证明一个数据已经被取走了 if __name__ == '__main__': q = JoinableQueue() p = Process(target=producer,args=('小明','包子',q)) p1 = Process(target=producer,args=('小红','饺子',q)) c = Process(target=consumer,args=('大明',q)) c1 = Process(target=consumer,args=('大红',q)) p.start() p1.start() c.daemon = True ##p1,p2结束了,证明c1,c2肯定全都收完了p1,p2发到队列的数据 #因而c1,c2也没有存在的价值了,不需要继续阻塞在进程中影响主进程了。应该随着主进程的结束而结束,所以设置成守护进程就可以了。 c1.daemon = True c.start() c1.start() p.join() p1.join() q.join() # #使用此方法进行阻塞,直到队列中所有项目均被处理。 # q.put(None) # q.put(None)