API网关服务:Spring Cloud Zuul-网关
通过前几章的介绍,我们对于Spring Cloud Netflix下的核心组件已经了解了一大半。这些组件基本涵盖了微服务架构中最为基础的几个核心设施,利用这些组件我们已经可以构建起一个简单的微服务架构系统,比如,通过使用Spring Cloud Eureka实现高可用的服务注册中心以及实现微服务的注册与发现;通过使用Spring Cloud Ribbon或Feign实现服务间负载均衡的接口调用;同时,为了使分布式系统更为健壮,对于依赖的服务调用使用Spring Cloud Hystrix来进行包装,实现线程隔离并加入熔断机制,以避免在微服务架构中因个别服务出现异常而引起级联故障蔓延。通过上述思路,我们可以设计出类似下图的基础系统架构。
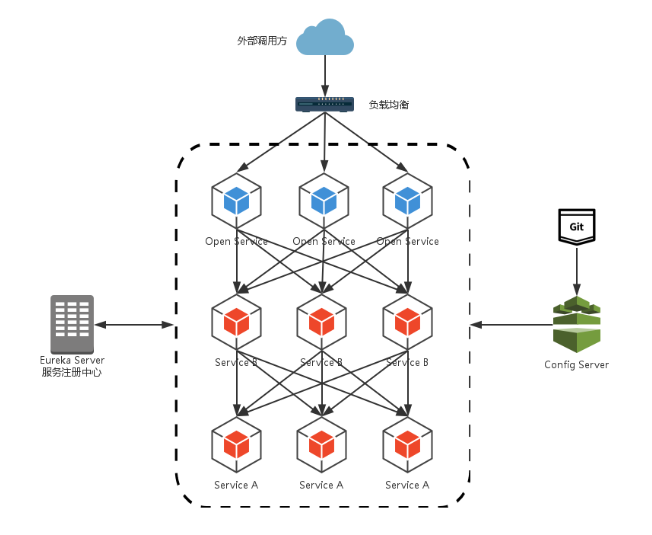
在该架构中,我们的服务集群包含内部服务ServiceA和ServiceB,他们都会向EurekaServer集群进行注册与订阅服务,而Open Service是一个对外的RESTful API服务,它通过F5、Nginx等网络设备或工具软件实现各个微服务的路由与负载均衡,并公开给外部的客户端调用。
在本章中,我们将把视线聚焦在对外服务这块内容,通常也称为边缘服务。首先需要肯定的是,上面的架构实现系统功能是完全没有问题的,但是我们还是可以进一步思考一下,这样的架构是否还有不足的地方会使运维人员或开发人员感到通过痛苦。
首先,我们从运维人员的角度来看看,他们平时都需要做一些什么工作来支持这样的架构。当客户端应用单击某个功能的时候往往会发出一些对微服务获取资源的请求到后端,这些请求通过F5、Nginx等设施的路由和负载均衡分配后,被转发到各个不同的服务实例上。而为了让这些设施能够正确路由与分发请求,运维人员需要手工维护这些路由规则与服务实例列表,当有实例增减或是IP地址变动等情况发生的时候,也需要手动地去同步修改这些信息以保持实例信息与中间件设置内容的一致性。在系统规模不大的时候,维护这些信息的工作还不会太过复杂,但是如果当系统规模不断增大,那么这些看似简单的维护任务会变得越来越难,并且出现配置错误的概率也会逐渐增加。很显然,这样的做法并不可取,所以我们需要一套机制来有效降低维护路由规则与服务实例列表的难度。
其次,我们再从开发人员的角度来看看,在这样的架构下,会产生一些怎样的问题呢?大多数情况下,为了保证对外服务的安全性,我们在服务端实现的微服务接口,往往都会有一定的权限校验机制,比如对用户登录状态的校验等;同时为了防止客户端在发起请求时被篡改等安全方面的考虑,还会有一些签名校验的机制存在。这时候,由于使用了微服务架构的理念,我们将原本处于一个应用中的多个模块拆成了多个应用,但是这些应用提供的接口都需要这些校验逻辑,我们不得不在这些应用中都实现这样一套校验逻辑。随着微服务规模的扩大,这些校验逻辑的冗余变得越来越多,突然有一天我们发现这一套校验逻辑有个BUG需要修复,或者需要对其做一些扩展和优化,此时我们就不得不去每个应用里修改这些逻辑,而这样的修改不仅会引起开发人员的抱怨,更会加重测试人员的负担。所以,我们也需要一套机制能够很好地解决微服务架构中,对于微服务接口访问时各前置校验的冗余问题。
为了解决上面这些常见的架构问题,API网关的概念应运而生。API网关是一个更为智能的应用服务器,它的定义类似于面向对象设计模式中的Facade模式,它的存在就像是整个微服务架构系统的门面一样,所有的外部客户端访问都需要经过它来进行调度和过滤。它除了要实现请求路由、负载均衡、校验过滤等功能之外,还需要更多能力,比如与服务治理框架的结合、请求转发时的熔断机制、服务的聚合等一系列高级功能。
既然API网关对于微服务架构这么重要,那么在Spring Cloud中是否有相应的解决方案呢?答案是肯定的,在Spring Cloud中提供了基于Netflix Zuul实现的API网关组件---Spring Cloud Zuul。那么,它是如何解决上面这两个普遍问题的呢?
首先,对于路由规则与服务实例的维护问题:Spring Cloud Zuul通过与Spring Cloud Eureka进行整合,将自身注册为Eureka服务治理下的应用,同时,从Eureka中获得了所有其他微服务的实例信息。这样的设计非常巧妙地将服务治理体系中维护的实例信息利用起来,使得将维护服务实例的工作交给了服务治理框架自动完成,不再需要人工介入。而对于路由规则的维护:Zuul默认会将通过以服务名作为ContextPath的方式创建路由映射,大部分情况下,这样的默认设置已经可以实现我们大部分的路由需求,除了一些特殊情况(比如兼容一些老的URL)还需要做一些特别的配置。但是相比于之前架构下的运维工作量,通过引入Spring Cloud Zuul实现API网关后,已经能够大大减少了。
其次,对于类似签名校验、登录校验在微服务架构中的冗余问题。理论上来说,这些校验逻辑在本质上与微服务应用自身的业务并没有多大的关系,所以它们完全可以独立成一个单独的服务存在,只是它们被剥离和独立出来之后,并不是给各个微服务调用,而是在API网关服务上进行统一调用来对微服务接口做前置过滤,以实现对微服务接口的拦截和校验。Spring Cloud Zuul提供了一套过滤器机制,它可以很好地支持这样的任务。开发者可以通过使用Zuul来创建各种校验过滤器,然后指定那些规则的请求需要执行校验逻辑,只有通过校验的才会被路由到具体的微服务接口,不然就返回错误提示。通过这样的改造,各个业务层的微服务应用就不再需要费业务性质的校验逻辑了,这使得我们的微服务应用可以更专注于业务逻辑的开发,同时微服务的自动化测试也变得更容易实现。
微服务架构虽然可以将我们的开发但愿拆分 得更为细致,有效降低了开发难度,但是它所引出的各种问题如果处理不当会成为实施过程中的不稳定因素,甚至掩盖掉原本实施微服务带来的优势。所以,在微服务架构的实施方案中,API网关服务的使用几乎成为了必然的选择。
下面我们将详细介绍Spring Cloud Zuul的使用方法、配置属性以及一些不足之处和需要进行的思考。
快速入门
介绍了这么多关于API网关服务的概念和作用,在这一节中,我们不妨用实际的示例来直观地体验一下Spring Cloud Zuul中封装的API网关是如何使用和运作,并应用到微服务架构中去的。
构建网关
首先,在实现各种API网关服务的高级功能之前,我们需要做一些准备工作,比如,构建起最基本的API网关服务,并且单搭建几个用于路由和过滤使用的微服务应用等。对于微服务应用,我们可以直接使用之前章节实现的hello-service和feign-consumer。虽然之前我们一直讲feign-consumer视为消费者,但是在Eureka的服务注册与发现体系中,每个服务既是提供者也是消费者,所以feign-consumer实质上也是一个服务提供者。之前我们访问的http://localhost:9001/feign-consumer等一系列接口就是它提供的服务。读者也可以使用自己实现的微服务应用,因为这部分不是本章的重点,任何微服务应用都可以被用来进行后续的试验。这里我们详细介绍一下API网关服务的构建过程。
1. 构建一个基础的Spring Boot工程,命名为api-gateway,并在pom.xml中引入spring-cloud-starter-zuul依赖,具体如下:
<parent>
<groupld>org.springframework.boot</groupid>
<artifactld>spring - boot - starter - paren七</artifactid>
<version>l.3.7.RELEASE</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactld>spring-cloud-starter-zuul</artifactid>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupld>org.springframework.cloud</groupld>
<artifactid>spring-cloud-dependencies</artifactid>
<version>Brixton.SRS</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
对于spirng-cloud-starter-zuul依赖,可以通过查看它的依赖内容来了解到:该模块中不仅包含了Netflix Zuul的核心依赖zuul-core,它还包括了下面这些网关服务需要的重要依赖。
a. spring-cloud-starter-hystrix:该依赖用来在网关服务中实现微服务转发时候的保护机制,通过线程隔离和断路器,防止微服务的故障引发API网关资源无法释放,从而影响其他应用的对外服务。
b. spring-cloud-starter-ribbon:该依赖用来实现在网关服务进行路由转发时候的客户端负载均衡以及请求重试。
c. spirng-boot-starter-actuator:该依赖用来提供常规的微服务管理端点。另外,在Spring Cloud Zuul中还特别体用了/routes 端点来返回当前的所有路由规则。
2. 创建应用主类,使用@EnableZuulProxy注解开启Zuul的API网关服务功能。
@EnableZuulProxy @SpringCloudApplication public class Application{ public static void main(String[] args){ new SpringApplicationBuilder(Application.class).web(true).run(args); } }
3. 在application.properties中配置Zuul应用的基础信息,如应用名、服务端口号等,具体内容如下:
spring.application.name=api-gateway
server.post=5555
完成上面的工作后,通过Zuul实现的API网关服务网就构建完毕了。
请求路由
下面,我们将通过一个简单的示例来为上面构建的网关服务增加请求路由的给功能。为了演示请求路由的功能,我们先将之前准备的Eureka服务注册中心和微服务应用都启动起来。
传统路由方式
使用Spring Cloud Zuul实现路由功能非常简单,只需要对api-gateway服务增加一些关于路由规则的配置,就能实现传统的路由转发功能,比如:
zuul.routes.api-a-url.path=/api-a-url/** zuul.routes.api-a-url.url=http://localhost:8080/
该配置定义了发往API网关服务的请求中,所有符合/api-a-url/**规则的访问都将被路由转发到http://localhost:8080/地址上,也就是说,当我们访问http://localhost:5555/api-a-url/hello的时候,API网络服务会将该请求路由到http://localhost:8080/hello提供的微服务接口上。其中,配置属性zuul.routes.api-a-url.path中的api-a-url部分为路由的名字,可以任意定义,但是一组path和url映射关系的路由名要相同,下面将要介绍的面向服务的映射方式也是如此。
面向服务的路由
很显然,传统路由的配置方式对于我们来说并不友好,它同样需要运维人员话费大量的时间来维护各个路由path与url的关系。为了解决这个问题,spring Cloud Zuul实现了Spring Cloud Eureka的无缝整合,我们可以让路由的path不是映射具体的url,而是让它映射到某个具体的服务,而具体的url则交给Eurek的服务发现机制去自动维护,我们称这类路由为面向服务的路由。在Zuul中使用服务路由也同样简单,只需做下面这些配置。
1. 为了与Eurek整合,我们需要在api-gateway的pom.xml中引入spring-cloud-starter-eureka依赖,具体如下:
<dependency> <groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId> </dependency>
2. 在api-gateway的application.properties配置文件中指定Eureka注册中心的位置,并且配置服务路由。具体如下:
zuul.routes.api-a.path=/api-a/** zuul.routes.api-a.serviceId=hello-service zuul.routes.api-b.path=/api-b/** zuul.routes.api-b.serviceId=feign-consumer eureka.client.serviceIUrl.defaultZone=http://localhost:1111/eureka/
针对我们之前准备的两个微服务应用hello-service和feign-consumer,在上面的配置中分别定义了两个名为api-a和api-b的路由来映射它们。另外,通过指定EurekaServer服务注册中心的位置,除了将自己注册成服务之外,同时也让Zuul能够获得hello-service和feign-consumer服务的实例清单,以实现path映射服务,再从服务中挑选实例来进行请求转发的完整路由机制。
在完成了上面的服务路由配置之后,我们可以将eureka-server、hello-service、feign-consumer以及这里用spring Cloud Zuul构建的api-gateway都启动起来。启动完毕,在eureka-server的信息面板中,我们可以看到,除了hello-service和feign-consumer之外,多了一个网关服务API-GATEWAY。

通过上面的搭建工作,我们已经可以通过服务网关来访问hello-service和feign-consumer这两个服务了。根据配置的映射关系,分别向网关发起下面这些请求。
1. http://localhost:5555/api-a/hello:该url符合/api-a/**规则,由api-a路由负责转发,该路由映射的serviceId为hello-service,所以最终/hello请求会被发送到hello-service服务的某个实例上去。
2. http://localhost:5555/api-b/feign-consumer:该url符合/api-b/**规则,由api-b路由负责转发,该路由映射的serviceId为feign-consumer,所以最终/feign-consumer请求会被发送到feign-consumer服务的某个实例上去。
通过面向服务的路由配置方式,我们不需要再为各个路由维护微服务应用的具体实例的位置,而是通过简单的path与serviceId的映射组合,使得维护工作变得非常简单。这完全归功于spirng cloud Eureka的服务发现机制,它使得API网关服务可以自动化完成服务实例清单的维护,完美地解决了对路由映射实例的维护问题。
请求过滤
在实现了请求路由功能之后,我们的微服务应用提供的接口就可以通过统一的API网关入口被客户端访问到了。但是,每个客户端用户请求微服务应用提供的接口时,它们的访问权限往往都有一定的限制,系统并不会讲所有的微服务接口都对它开放。然而,目前的服务路由并没有限制权限这样的功能,所有请求都会被毫无保留地转发到具体的应用并返回结果,为了实现对客户端请求的安全校验和权限控制,最简单和粗暴的方法就是为每个微服务应用都实现一套用于校验签名和鉴别权限的过滤器或者拦截器。不过,这样的做法并不可取,它会增加日后系统的维护难度,因为同一个系统中的各种校验逻辑很多情况下都是大致相同或类似的,这样的实现方式会使得相似的校验逻辑代码被分散到了各个微服务中去,冗余代码的出现是我们不希望看到的。所以,比较好的做法就是将这些校验逻辑剥离出去,构建出一个独立的鉴权服务。在完成了剥离之后,有不少开发者会直接在微服务应用中通过调用鉴权服务来实现校验,但是这样的做法仅仅只是解决了鉴权逻辑的分离,并没有在本质上将这部分不属于冗余的逻辑从原有的微服务应用中拆分出,冗余的拦截器或过滤器依然会存在。
对于这样的问题,更好的做法是通过前置的网关服务来完成这些非业务性质的校验。由于网关服务的加入,外部客户端访问我们的系统已经有了统一入口,既然这些校验与具体业务无关,那何不在请求到达的时候就完成校验和过滤,而不是转发后再过滤而导致更长的请求延迟。同时,通过在网关中完成校验和过滤,微服务应用端就可以去除各种复杂的过滤器和拦截器了,这使得微服务应用接口的开发和测试复杂度也得到了相应降低。
为了在API网关中实现对客户端请求的校验,我们将继续介绍spring Cloud Zuul的另外一个核心功能:请求过滤。Zuul允许开发者在API网关上通过定义过滤器来实现对请求的拦截和过滤,实现的方法非常简单,我们只需要继承ZuulFilter抽象类并实现它定义的4个抽象函数就可以完成对请求的拦截和过滤了。
下面的代码定义了一个简单的Zuul过滤器,它实现了在请求被路由之前检查HttpServletRequest中是否有accessToken参数,若有就进行路由,若没有就拒绝访问,返回401 Unauthorized错误。
public class AccessFilter extends ZuulFilter{ private static Logger log = LoggerFactory.gerLogger(AccessFilter.class); @Override public String filterType() { return "pre"; } @Override public int filterOrder () { return O; } @Override public boolean shouldFilter() { return true; } @Override public Object run() { RequestContext ctx = RequestContext.getCurrentContext(); HttpServletRequest request = ctx.getRequest();
log.info("send {} request to{}", request.getMethod () ,request.getRequestURL().toString());
Object accessToken = request.getParameter("accessToken"); if(accessToken == null) { log.warn("access token is empty"); ctx.setSendZuulResponse(false); ctx.setResponseStatusCode(401); return null; } log.info("access token ok"); return null; } }
在上面实现的过滤器代码中,我们通过继承ZuulFilter抽象类并重写下面4个方法来实现自定义的过滤器。这4个方法分别定义了如下内容。
1. filterType:过滤器的类型,它决定过滤器在请求的那个生命周期中执行。这里定义为pre,代表会在请求被路由之前执行。
2. filterOrder:过滤器的执行顺序。当请求在一个阶段中存在多个过滤器时,需要根据该方法返回的值来依次执行。
3. shouldFilter:判断该过滤器是否需要被执行。这里我们直接返回了true,因此该过滤器对所有请求都会生效。实际运用中我们可以利用该函数来指定过滤器的有效范围。
4. run:过滤器的具体逻辑。这里我们通过ctx.setSendZuulResponse(false)令zuul过滤该请求,不对其进行路由,然后通过ctx.setResponseStatus-Code(401)设置了其返回的错误代码,当然也可以进一步优化我们的返回,比如,通过ctx.setResponseBody(body)对返回的body内容进行编辑等。
在实现了自定义过滤器之后,它并不会直接生效,我们还需要为其创建具体的Bean才能启动该过滤器,比如,在应用主类中增加如下内容:
@EnableZuulProxy @SpringCloudApplication public class Application{ public static void main(String[] args){ new SpringApplicationBuilder(Application.class).web(true).run(args); } @Bean public AccessFilter accessFilter(){ return new AccessFilter(); } }
在对api-gateway服务完成了上面的改造之后,我们可以重新启动它,并发起下面的请求,对上面定义的过滤器做一个验证。
1. http://localhost:5555/api-a/hello:返回401错误。
2. http://localhost:5555/api-a/hello&accessToken=token:正确路由到hello-service的/hello接口,并返回Hello World。
到这里,对于API网关服务的快速入门示例就完成了。通过对Spring Cloud Zuul两个核心功能的介绍,相信读者已经能够体会到API网关服务对微服务架构的重要性了,就目前掌握的API网关知识,我们可以将具体原因总结如下:
1. 它作为系统的统一入口,屏蔽了系统内部各个微服务的细节。
2. 它可以与服务治理框架结合,实现自动化的服务实例维护以及负载均衡的路由转发。
3. 它可以实现接口权限校验与微服务业务逻辑的解耦。
4. 通过服务网关中的过滤器,在各生命周期中去校验请求的内容,将原本在对外服务层做的校验前移,包含了微服务的无状态性,同时降低了微服务的测试难度,让服务本身更集中关注业务逻辑的处理。
实际上,基于spirng cloud Zuul实现的API网关服务除了上面所示的优点之外,它还有一些更加强大的功能,我们将在后续的章节对其进行更深入的介绍。通过本节的内容,我们只是希望以一个简单的例子带领读者先来简单认识一下API网关服务提供的基础功能以及它在微服务架构中的重要地位。
路由详解
在“快速入门”一节的请求路由示例中,我们对spring Cloud Zuul中的两类路由功能已经做了简单的使用介绍。在本节中,我们将进一步详细介绍关于Spring Cloud Zuul的路由功能,以帮助读者更好地理解和使用它。
传统路由配置
所谓的传统路由配置方式就是在不依赖于服务发现机制的情况下,通过在配置文件中具体制定每个路由表达式与服务实例的映射关系来实现API网关对外部请求的路由。
没有Eureka等服务治理框架的帮助,我们需要根据服务实例的数量采用不同方式的配置来实现路由规则。
1. 单实例配置:通过zuul.routes.<route>.path与zuul.routes.<route>.url参数对的方式进行配置,比如:
zuul.routes.user-service.path=/user-service/** zuul.routes.user-service.url=http://localhost:8080/
该配置实现了对符合/user-service/**规则的请求路径转发到http://localhost:8080/地址的路由规则。比如,当有一个请求http://localhost:5555/user-service/hello被发送到API网关上,由于/user-service/hello能够被上述配置的path规则匹配,所以API网关会转发到http://localhost:8080/hello地址。
2. 多实例配置:通过zuul.routes.<route>.path与zuul.routes.<route>.serviceId参数对的方式进行配置,比如:
zuul.routes.user-service.path=/user-service/** zuul.routes.user-service.serviceId=user-service ribbon.eureka.enabled=false user-service.ribbon.listOfServers=http://localhost:8080/,http://localhost:8081/
该配置实现了对符合/user-service/**规则的请求路径准发到http://localhost:8080/和http://localhost:8081/两个实例地址的路由规则。它的配置方式与服务路由的配置方式一样,都采用了zuul.routes.<route>.path与zuul.routes.<route>.serviceId参数对的映射方式,只是这里的serviceId是由用户手动命名的服务名称,配合ribbon.listOfServers参数实现服务与实例的维护。由于存在多个实例,API网关在进行路由转发时需要实现负载均衡策略,于是这里还需要Spring Cloud Ribbon的配合。由于在Spring Cloud Zuul中自带了对Ribbon的依赖,所以我们只做一些配置即可,比如上面示例中关于Ribbon的各个配置,他们的具体作用如下所示。
1. ribbon.eureka.enabled:由于zuul.routes.<route>.serviceId指定的是服务名称,默认情况下Ribbon会根据服务发现机制来获取配置服务名对应的实例清单。但是,该示例并没有整合类似Eureka之类的服务治理框架,所以需要将该参数设置为false,否则配置的serviceId获取不到对应实例的清单。
2. user-service.ribbon.listOfServers:该参数内容与zuul.routes.<route>.serviceId的配置相对应,开头的user-service对应了serviceId的值,这两个参数的配置相当于在该应用内部手工维护了服务和实例的对应关系。
不论是单实例还是多实例的配置方式,我们都需要为每一对映射关系指定一个名称,也就是上面配置中的<route>,每一个<route>对应了一条路由规则。每条路由规则都需要通过path属性来定义一个用来匹配客户端请求的路径表达式,并通过url或serviceId属性来指定请求表达式映射具体实例地址或服务名。
服务路由配置
对于服务路由,我们在快速入门示例中已经有过基础的介绍和体验,Spring Cloud Zuul通过与Spring Cloud Eureka的整合,实现了对服务实例的自动化维护,所以在使用服务路由配置的时候,我们不需要像传统路由配置方式那样为serviceId指定具体的服务实例地址,只需要通过zuul.routes.<route>.path与zuul.routes.<route>.serviceId参数对的方式进行配置即可。
比如下面的示例,它实现了对符合/user-service/**规则的请求路径转发到名为user-service的服务实例上去的路由规则。其中<route>可以指定为任意的路由名称。
zuul.routes.user-service.path=/user-service/** zuul.routes.user-service.serviceId=user-service
对于面向服务的路由配置,除了使用path与serviceId映射的配置方式之外,还有一种更简洁的配置方式:zuul.routes.<serviceId>=<path>,其中<serviceId>用来指定路由的具体服务名,<path>用来配置匹配的请求表达式。比如下面的例子,它的路由规则等价于上面通过path与serviceId组合使用的配置方式。
zuul.routes.user-service=/user-service/**
传统路由的映射方式比较直观且容易理解,API网关直接根据请求的URL路径找到最匹配的path表达式,直接转发给该表达式对应的url或对应serviceId下配置的实例地址,以实现外部请求的路由。那么当采用path与serviceId以服务路由的方式实现时,在没有配置任何实例地址的情况下,外部请求经过API网关的时候,它是如何被解析并转发到服务具体实例的呢?
在本章一开始,我们就提到了Zuul巧妙地整合了Eureka来实现面向服务的路由。实际上,我们可以直接将API网关也看作Eureka服务治理下的一个普通微服务应用。它除了会将自己注册到Eureka服务注册中心上之外,也会从注册中心获取所有服务以及它们的实例清单。所以,在Eureka的帮助下,API网关服务本身就已经维护了系统中所有serviceId与实际地址的映射关系。当有外部请求到达API网关的时候,根据请求的URL路径找到最佳匹配的path规则,API网关就可以知道要将请求路由到哪个具体的serviceId上去。由于在API网关中已经知道serviceId对应服务实例的地址清单,那么只需要通过Ribbon的负载均衡策略,直接在这些清单中选择一个具体的实例进行转发就能完成路由工作了。
服务路由的默认规则
虽然通过Eureka与Zuul的整合已经为我们省去了维护服务实例清单的大量配置工作,剩下只需要再维护请求路径的匹配表达式与服务名的映射关系即可。但是在实际的运用过程中会发现,大部分的路由配置规则几乎都会采用服务名作为外部请求的前缀,比如下面的例子,其中path路径的前缀使用了user-service,而对应的服务名称也是user-service。
zuul.routes.user-service.path=/user-service/** zuul.routes.user-service.serviceId=user-service
对于这样具有规则性的配置内容,我们总是希望可以自动化完成。非常庆幸,Zuul默认实现了这样的贴心功能,当我们为Spring Cloud Zuul构建的API网关服务引入Spring Cloud Eureka之后,它为Eureka中的每个服务都自动创建一个默认路由规则,这些默认规则的path会使用serviceId配置的服务名作为请求前缀,就如上面的例子那样。
由于默认情况下所有Eureka上的服务都会被Zuul自动地创建映射关系来进行路由,这会使得一些我们不希望对外开放的服务也可能被外部访问到。这个时候,我们可以使用zuul.ignored-services参数来设置一个服务名匹配表达式来定义不自动创建路由的规则。Zuul在自动创建服务路由的时候会根据该表达式来进行判断,如果服务名匹配表达式,那么Zuul将跳过该服务,不为其创建路由规则。比如,设置为zuul.ignored-services=*的时候,Zuul将对所有的服务都不自动创建路由规则。在这种情况下,我们就要在配置文件中逐个为需要路由的服务添加映射规则(可以使用path与serviceId组合的配置方式,也可使用更为简洁的zuul.routes.<serviceId>=<path>配置方式),只有在配置文件中出现的映射规则会被创建路由,而从Eureka中获取的其他服务,Zuul将不再为它们创建路由规则。
自定义路由映射规则
我们在构建微服务系统进行业务逻辑开发的时候,为了兼容外部不同版本的客户端程序(尽量不强迫用户升级客户端),一般都会采用开闭原则来进行设计与开发(面向对象编程中规定“软件中的对象(类,模块,函数等等)应该对于扩展是开放的,但是对于修改是封闭的”,这意味着一个实体是允许在不改变它的源代码的前提下变更它的行为)。这使得系统在迭代过程中,有时候会需要我们为一组互相配合的微服务定义一个版本表示来方便管理它们的版本关系,根据这个标识我们可以很容易地知道这些服务需要一起启动并配合使用。比如可以采用类似这样的命名:userservice-v1、userservice-v2、orderservice-v1、orderservice-v2。默认情况下,Zuul自动为服务创建的路由表达式会采用服务名作为前缀,比如针对上面的userservice-v1和userservice-v2,它会产生/userservice-v1和/userservice-v2两个路径表达式来映射,但是这样生成出来的表达式规则比较单一,不利于通过路径规则来进行管理。通常的做法是为这些不同版本的微服务应用生成以版本代号作为路由前缀定义的路由规则,比如/v1/userservice/。这时候,通过这样具有版本号前缀的URL路径,我们就可以很容易地通过路径表达式来归类和管理这些具有版本信息的微服务了。
针对上面所述的需求,如果我们的各个微服务应用都遵循了类似userservice-v1这样的命名规则,通过-分隔的规范来定义服务名和服务版本标识的话,那么,我们可以使用Zuul中自定义服务与路由映射关系的功能,来实现为符合上述规则的微服务自动化地创建类似/v1/userservice/**的路由匹配规则。实现步骤非常简单,只需在API网关程序中,增加如下Bean的创建即可:
@Bean public PatternServiceRouteMapper serviceRouteMapper(){ return new PatternServiceRouteMapper(
}
PatternServiceRouteMapper对象可以让开发者通过正则表达式来自定义服务与路由映射的生成关系。其中构造函数的第一个参数是用来匹配服务名称是否符合该自定义规则的正则表达式,而第二个参数则是定义根据服务名中定义的内容转换出的路径表达式规则。当开发者在API网关中定义PatternServiceRouteMapper实现之后,只要符合第一个参数定义规则的服务名,都会优先使用该实现构建出的路径表达式,如果没有匹配上的服务则还是会使用默认的路由映射规则,即采用完整服务名作为前缀的路径表达式。
路径匹配
不论是使用传统路由的配置方式还是服务路由的配置方式,我们都需要为每个路由规则定义匹配表达式,也就是上面所说的path参数。在Zuul中,路由匹配的路径表达式采用了Ant风格定义。
Ant风格的路径表达式使用起来非常简单,它一共有下面这三种通配符。

我们可以通过下表中的示例来进一步理解这三个通配符的含义并进行参考使用。

另外,当我们使用通配符的时候,经常会碰到这样的问题:一个URL路径可能会被多个不同路由的表达式匹配上。比如,有这样一个场景,我们在系统建设的一开始实现了user-service服务,并且配置了如下路由规则:
zuul.routes.user-service.path=/user-service/** zuul.routes.user-service.serviceId=user-service
但是随着版本的迭代,我们对user-service服务做了一些功能拆分,将原属于user-service服务的某些功能拆分到了另一个全新的服务user-service-ext中去,而这些拆分的外部调用URL路径希望能够符合规则/user-service/ext/**,这个时候我们需要就在配置文件中增加一个路由规则,完整配置如下:
zuul.routes.user-service.path=/user-service/** zuul.routes.user-service.serviceId=user-service
zuul.routes.user-service-ext.path=/user-service/ext/**
zuul.routes.user-service-ext.serviceId=user-service-ext
此时,调用user-service-ext服务的URL路径实际上会同时被/user-service/**和/user-service/ext/**两个表达式所匹配。在逻辑上,API网关服务需要优先选择/user-service/ext/**路由,然后再匹配/user-service/**路径才能实现上述需求。但是如果使用上面的配置方式,实际上是无法保证这样的路由优先顺序的。
从下面的路由匹配算法中,我们可以看到它在使用路由规则匹配请求路径的时候是通过线性遍历的方式,在请求路径获取到第一个匹配的路由规则之后就返回并结束匹配过程。所以当存在多个匹配的路由规则时,匹配结果完全取决于路由规则的保存顺序。
@Override public Route getMatchingRoute{final String path) {
... ZuulRoute route = null; if (!matchesignoredPatterns(adjustedPath)) { for (Entry<String, ZuulRoute> entry : this. routes. get () . entrySet ()) { String pattern = entry. getKey () ; log.debug("Matching pattern:" + pattern); if (this.pathMatcher.match(pattern, adjustedPath)) { route = entry.getValue(); break;
}
}
}
log.debug("route matched="+ route);
return getRoute(route,adjustdPath);
}
下面所示的代码是基础的路由规则加载算法,我们可以看到这些路由规则是通过LinkedHashMap保存的,也就是说,路由规则的保存是有序的,而内容的加载时通过遍历配置文件中路由规则依次加入的,所以导致问题的根本原因是对配置文件中内容的读取。
protected Map<String,ZuulRoute> locateRoutes(){ LinkedHashMap<String,ZuulRoute> routesMap= new LinkedHashMap<String,ZuulRoute>();
for(ZuulRoute route : this.properties.getRoutes().values()){
routesMap.put(route.getPath(),route);
}
return routesMap; }
由于properties的配置内容无法保证有序,所以当出现这种情况的时候,为了保证路由的优先顺序,我们需要使用YAML文件来配置,以实现有序的路由规则,比如使用下面的定义:
zuul: routes: user-service-ext: path: /user-service/ext/** serviceld: user-service-ext user-service: path : / user-service/** serviceld: user-service
忽略表达式
通过path参数定义的Ant表达式已经能够完成API网关上的路由规则配置功能,但是为了更细颗粒度和更为灵活地配置路由规则,Zuul还提供了一个忽略表达式参数zuul.ignored-patterns。该参数可以用来设置不希望被API网关进行路由的URL表达式。
比如,以快速入门中的示例为基础,如果不希望/hello接口被路由,那么我们可以这样设置:
zuul.ignored-patterns=/**/hello/** zuul.routes.api-a.path=/api-a/** zuul.routes.api-a.serviceId=hello-service
然后,可以尝试通过网关来访问hello-service的/hello接口http://localhost:5555/api-a/hello。虽然该访问路径完全符合path参数定义的/api-a/**规则,但是由于该路径符合zuul.ignored-patterns参数定义的规则,所以不会被正确路由。同时,我们在控制台或日志中还能看到没有匹配路由的输出信息:
o.s.c.n.z.f.pre.PreDecorationFilter : No route found for uri: /api-a/hello
另外,该参数在使用时还需要注意它的范围并不是对某个路由,而是对所有路由。所以在设置的时候需要全面考虑URL规则,防止忽略了不该被忽略的URL路径。
路由前缀
为了方便全局地位路由规则增加前缀信息,Zuul提供了zuul.prefix参数来进行设置。比如,希望为网关上的路由规则都增加/api前缀,那么我们在配置文件中增加配置:zuul.pregix=/api。另外,对于代理前缀会默认从路径中移除,我们可以通过设置zuul.stripPrefix=false来关闭该移除代理前缀的动作,也可以通过zuul.routes.<route>.strip-prefix=true来对指定路由关闭移除代理前缀的动作。
注意:在使用zuul.prefix参数的时候,目前版本的实现还存在一些Bug,所以请谨慎使用,或是避开会引发Bug的配置规则。具体会引发Bug的规则如下:
假设我们设置zuul.prefix=/api,当路由规则的path表达式以/api开头的时候,将会产生错误的映射关系。可以进行下面的配置实验来验证这个问题:
zuul.routes.api-a.path=/api/a/** zuul.routes.api-a.serviceId=hello-service zuul.routes.api-b.path=/api-b/** zuul.routes.api-b.serviceId=hello-service
zuul.routes.api-c.path=/ccc/** zuul.routes.api-c.serviceId=hello-service
这里配置了三个路由关系,/api/a/**、/api-b/**、/ccc/**,这三个路径规则都将被路由到hello-service服务上去。当我们没有设置zuul.prefix=/api的时候,一切运作正常。但是在增加了zuul.prefix=/api配置后,会得到下面这样的路由关系:

从日志信息中我们看到,以/api开头的路由规则解析除了两个看似就有问题的映射URL,我们可以通过该输出的URL来访问,实际是路由不到正确的服务接口的,只有非/api开头的路由规则/ccc/**能够正常路由。
上述实验基于Brixton.SR7和Camden.SR3测试均存在问题,所以在使用该版本或以下版本时候,务必避免让路由表达式的起始字符串与zuul.prefix参数相同。
本地跳转
在Zuul实现的API网关路由功能中,还支持forward形式的服务端跳转配置。实现方式非常简单,只需通过使用path与url的配置方式就能完成,通过url中使用forward来指定需要跳转的服务器资源路径。
下面的配置实现了两个路由规则,api-a路由实现了将符合/api-a/**规则的请求抓发到http://localhost:8001/:而api-b路由则使用了本地跳转,它实现了将符合/api-b/**规则的请求转发到API网关中以/local为前缀的请求上,由API网关进行本地处理。比如,当API网关接收到请求/api-b/hello,它符合api-b的路由规则,所以该请求会被API网关转发到网关的/local/hello请求上进行本地处理。
zuul.routes.api-a.path=/api-a/** zuul.routes.api-a.url=http://localhost:8001/ zuul.routes.api-b.path=/api-b/** zuul.routes.api-b.url=forward:/local
这里要注意,由于需要在API网关上实现本地跳转,所以相应的我们也需要为本地跳转实现对应的请求接口。按照上面的例子,在API网关上还需要增加一个/local/hello的接口实现才能让api-b路由规则生效,比如下面的实现。否则Zuul在进行forward转发的时候会因为找不到该请求而返回404错误。
@RestController public class HelloController{ @RequestMapping("/local/hello") public String hello(){ return "hello world local"; } }
Cookie与头信息
默认情况下,Spring Cloud Zuul在请求路由时,会过滤掉HTTP请求头信息中的一些敏感信息,防止它们被传递到下游的外部服务器。默认的敏感头信息通过zuul.sensitiveHeaders参数定义,包括Cookie、Set-Cookie、Authorization三个属性。所以,我们在开发Web项目时常用的Cookie在Spring Cloud Zuul网关中默认是不会传递的,这就会引发一个常见的问题:如果我们要将使用了Spring Security、Shiro等安全框架构建的Web应用通过Spring Cloud Zuul构建的网关来进行路由时,由于Cookie信息无法传递,我们的Web应用将无法实现登录和鉴权。为了解决这个问题,配置的方法有很多。
1、通过设置全局参数为空来覆盖默认值,具体如下:
zuul.sensitiveHeader=
这种方法并不推荐,虽然可以实现Cookie的传递,但是破坏了默认设置的用意。在微服务架构的API网关之内,对于无状态的RESTful API请求肯定要远多于这些Web 类应用请求的,甚至还有一些架构设计会将Web类应用和App客户端一样都归为API网关之外的客户端应用。
2、通过指定路由的参数来配置,方法有下面两种。
#方法一:对指定路由开启自定义敏感头 zuul.routes.<router>.customSensitiveHeaders=true #方法二:将指定的路由的敏感头设置为空 zuul.routes.<router>.sensitiveHeader=
比较推荐使用这两种方法,仅对指定的Web应用开启对敏感信息的传递,影响范围小,不至于引起其他服务的信息泄露。
重定向问题
在解决了Cookie问题之后,我们已经能够通过网关来访问并登录到我们的Web应用了。但是这个时候又会发现另一个问题:虽然可以通过网关访问登录页面并发起的登录请求,但是登录成功之后,我们跳转到的页面URL却是具体Web应用实例的地址,而不是通过网关的路由地址。这个问题非常严重,因为使用API网关的一个重要原因就是要将网关作为统一入口,从而不暴露所有的内部服务细节。那么是什么原因导致了这个问题呢?
通过浏览器开发工具查看登录以及登录之后的请求详情,可以发现,引起问题的大致原因是由于Spring Security或Shiro在登录完成之后,通过重定向的方式跳转到登录后的页面,此时登录后的请求结果状态码为302,请求响应头信息中的Location执行了具体的服务实例地址,而请求头信息中的Host也指向了具体的服务实例IP地址和端口。所以,该问题的根本原因在于Spring Cloud Zuul在路由请求时,并没有将最初的Host信息设置正确。那么如何解决这个问题呢?
针对这个问题,目前在spring-cloud-netflix-core-1.2.x版本的Zuul中增加了一个参数配置,能够使得网关在进行路由转发前为请求设置Host头信息,以标识最初的服务端请求地址。具体配置方式如下:
zuul.addHostHeader=true
由于Spring Cloud的版本依赖原因,目前的Brixton版本采用spring-cloud-netflix-core-1.1.x,只有Camden版本采用了spring-cloud-netflix-core-1.2.x。所以重定向的问题如果要在Zuul中解决,最简单的方法就使用Camden版本。如果要在Brixton版本中解决,可以参考Camden的PreDecorationFilter的实现扩展过滤器链来增加Host信息。
Hystrix和Ribbon支持
在“快速入门”一节中介绍spring-cloud-starter-zuul依赖时,我们提到了它自身就包含了对spring-cloud-starter-hystrix和spring-cloud-starter-ribbon模块的依赖,所以Zuul天生就拥有线程隔离和断路器的自我保护功能,以及对服务调用的客户端负载均衡功能。但是需要注意,当使用path与url的映射关系来配置路由规则的时候,对于路由转发的请求不会采用hystrixCommand来包装,所以这类路由请求没有线程隔离和断路器的保护,并且也不会有负载均衡的能力。因此,我们在使用Zuul的时候尽量使用path和serviceId的组合来进行配置,这样不仅可以保证API网关的健壮和稳定,也能用到Ribbon的客户端负载均衡功能。
我们在使用Zuul搭建API网关的时候,可以通过Hystrix和Ribbon的参数来调整路由请求的各种超时时间等设置,比如下面这些参数的设置。
1、hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds:该参数可以用来设置API网关中路由转发请求的HystrixCommand执行超时时间,单位为毫秒。当路由转发请求的命令执行时间超过该配置值之后,Hystrix会将该执行命令标记为TIMEOUT并抛出异常,Zuul会对该异常进行处理并返回如下JSON信息给外部调用方。
{ "timestamp": 1481350975323, "status": 500, "error": "Internal Server Error", "exception": "com.netflix.zuul.exception.ZuulException", "message": "TIMEOUT" }
2、ribbon.ConnectTimeout:该参数用来设置路由转发请求的时候,创建请求连接的超时时间。当ribbon.ConnectTimeout的配置值小于hystrix.command.default.execution.isolation.tread.timeoutInMillseconds配置值的时候,若路由请求出现连接超时,会自动进行重试路由请求,如果重试依然失败,Zuul会返回如下JSON信息给外部调用方。
{ "times七amp": 1481352582852, "status": 500, "error": "Internal Server Error", "exception": "com.netflix.zuul.exception.ZuulException", "message": "NUMBEROF RETRIES NEXTSERVER EXCEEDED" }
如果ribbon.ConnectTimeout的配置值大于hystix.command.default.execution.isolation.thread.timeoutInMillseconds配置值的时候,当出现路由请求连接超时时,由于此时对于路由转发的请求命令已经超时,所以不会进行重试路由请求,而是直接请求命令超时处理,返回TIMEOUT的错误信息。
3、ribbon.ReadTimeout:该参数用来设置路由转发请求的超时时间。它的处理与ribbon.ConnectTimeout类似,只是它的超时是对请求连接建立之后的处理时间。当ribbon.ReadTimeout的配置值小于hystirx.command.default.execution.isolation.thread.timeoutInMilliseconds配置值的时候,若路由请求的处理时间超过该配置值且依赖服务的请求还未响应的时候,会自动进行重试路由请求。如果重试后依然没有获得请求响应,Zuul会返回MUMBEROF_RETRIES_NEXTSERVER_EXCEEDED错误。如果ribbon.ReadTimeout的配置值大于hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds配置值,若路由请求的处理时间超过该配置值且依赖服务的请求还未响应时,不会进行路由重试请求,而是直接按请求命令超时处理,返回TIMEOUT的错误信息。
根据上面的介绍我们可以知道,在使用Zuul的服务路由时,如果路由转发请求发生超时(连接超时或后处理超时),只要超时时间的设置小于Hystirix的命令超时时间,那么它就会自动发起重试。但是在有些情况下,我们可能需要关闭重试机制,那么可以通过下面的两个参数来进行设置。
zuul.retryable=false zuul.routes.<route>.retryable=false
其中,zuul.retryable用来全局关闭重试机制,而zuul.routes.<route>.retryable=false则是指定路由关闭重试机制。
过滤器详解
在本章一开始的快速入门示例中,我们已经介绍了一部分关于请求过滤的功能。在本节中,我们将对Zuul的请求过滤器功能做进一步的介绍和总结。
过滤器
通过快速入门的示例,我们对于Zuul的第一印象通常是这样的:它包含了对请求的路由和过滤两个功能,其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础;而过滤器功能则负责对请求的处理进程进行干预,是实现请求校验、服务聚合等功能的基础。然而实际上,路由功能在真正运行时,它的路由映射和请求转发都是由几个不同的过滤器完成的。其中,路由映射主要通过pre类型的过滤器完成,它将请求路径与配置的路由规则进行匹配,以找到需要转发的目标地址;而请求转发的部分则是route类型的过滤器来完成,对pre类型过滤器获得的路由地址进行转发。所以,过滤器可以说是Zuul实现API网关功能最为核心的部件,每一个进入Zuul的HTTP请求都会经过一系列的过滤器处理链得到请求响应并返回给客户端。
在Spring Cloud Zuul中实现的过滤器必须包含4个基本特征:过滤类型、执行顺序、执行条件、具体操作。这些元素看起来非常熟悉,实际上它就是ZuulFilter接口中定义的4个抽象方法:
String filterType();
int filterOrder();
boolean shouldFilter();
Object run();
它们各自的含义与功能总结如下。
1、filterType:该函数需要返回字符串来代表过滤器的类型, 而这个类型就是HTTP请求过程中定义的各个阶段。在Zuul中默认定义了4中不同生命周期的过滤器类型,具体如下所示。
a. pre:可以在请求被路由之前调用。
b. routing:在路由请求时被调用。
c. post:在routing和error过滤器之后被调用。
d. error:处理请求时发生错误时被调用。
2、filterIrder:通过int值来定义过滤器的执行顺序,数值越小优先级越高。
3、shouldFilter:返回一个boolean值来判断该过滤器是否要执行。我们可以通过此方法来指定过滤器的有效范围。
4、run:过滤器的具体逻辑。在该函数中,我们可以实现自定义的过滤逻辑,来确定是否要拦截当前的请求,不对其进行后续的路由,或是在请求路由返回结果之后,对结果做些加工等。
请求生命周期
对于Zuul中的过滤器类型filterType,我们已经做过一些简单的介绍。Zuul默认定义了4种不同的过滤器类型,它们覆盖了一个外部HTTP请求到达API网关,直到返回请求结果的全部生命周期。下图源自Zuul的官方WiKi中关于请求生命周期的图解,它描述了一个HTTP请求到达API网关之后,如何在各种不同类型的过滤器之间流转的详细过程。
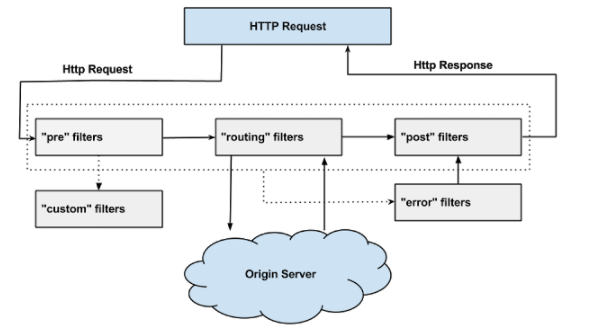
从上图中我们可以看到,当外部HTTP请求到达API网关服务的时候,首先它会进入第一个阶段pre,在这里它会被pre类型的过滤器进行处理,该类型过滤器的主要目的是在进行请求路由之前做一些前置加工,比如请求的校验等。在完成了pre类型的过滤器处理之后,请求进入第二阶段routing,也就是之前说的路由请求转发阶段,请求将会被routing类型过滤器处理。这里的具体处理内容就是将外部请求转发到具体服务实例上去的过程,当服务实例将请求结果都返回之后,routing阶段完成,请求进入第三个阶段post。此时请求将会被post类型的过滤器处理,这些过滤器在处理的时候不仅可以获取到请求信息,还能获取到服务实例的返回信息,所以在post类型的过滤器中,我们可以对处理结果进行一些加工或转换等内容。另外,还有一个特殊的阶段error,该阶段只有在上述三个阶段中发生异常的时候才会触发,但是它的最后流向还是post类型的过滤器,因为它需要通过post过滤器将最终结果返回给请求客户端(对于error过滤器的处理,在Spring Cloud Zuul的过滤链中实际上有一些不同,后续我们在介绍核心过滤器时会做详细分析)。
核心过滤器
在Spring Cloud Zuul中,为了让API网关组件可以被更方便地使用,它在HTTP请求生命周期的各个阶段默认实现了一批核心过滤器,它们会在API网关服务启动的时候被自动加载和启用。我们可以在源码中查看和了解它们,它们定义了spring-cloud-netflix-core模块的org.springframework.cloud.netflix.zuul.filters包下。
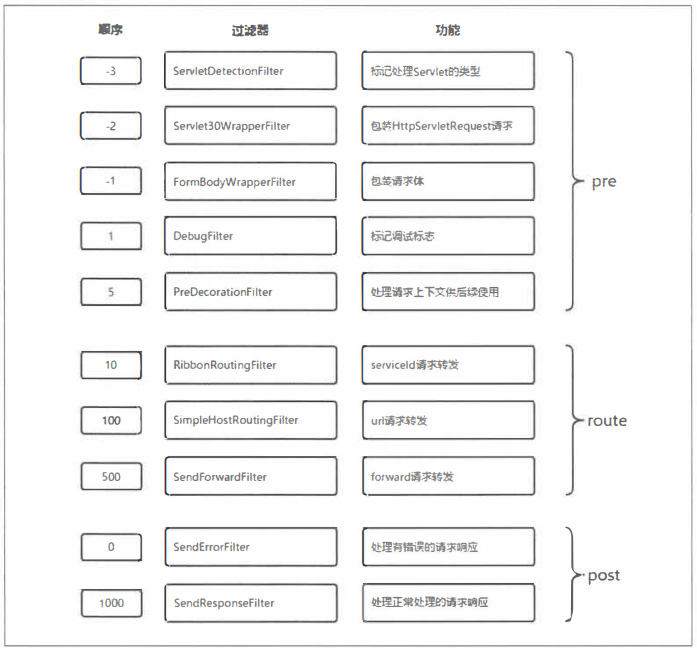
如下图所示,在默认启动的过滤器中包含三种不同生命周期的过滤器,这些过滤器都非常重要,可以帮助我们理解Zuul对外部请求处理的过程,以及帮助我们在此基础上扩展过滤器去完成自身系统需要的功能。下面,我们将逐个对这些过滤器做详细的介绍。

pre过滤器
1、ServletDetectionFilter(Servlet侦查过滤器):它的执行顺序为-3,是最先被执行的过滤器。该过滤器总是会被执行,主要用来检测当前请求是通过spring的DispatcherServlet处理运行的,还是通过ZuulServlet来处理运行的。它的检测结果会以布尔类型保存在当前请求上下文的isDispatcherServletRequest参数中,这样在后续的过滤器中,我们就可以通过RequestUtils.isDispatcherServletRequest()和RequestUtils.isZuulServletRequest()方法来判断请求处理的源头,以实现后续不同的处理机制。一般情况下,发送到API网关的外部请求都会被Spring的DispatcherServlet处理,除了通过/zuul/*路径访问的请求会绕过DispatcherServlet,被zuulServlet处理,主要用来应对处理大文件上传的情况。另外,对于ZuulServlet的访问路径/zuul/*,我们可以通过zuul.servletPath参数来进行修改。
2、Servlet30WrapperFilter(Servlet包装过滤器):它的执行顺序为-2,是第二个执行的过滤器。目前的实现会对所有请求生效,主要为了将原始的HttpServletRequest包装成Servlet30RequestWrapper对象。
3、FormBodyWrapperFilter(FormBody包装过滤器):它的执行顺序为-1,是第三执行的过滤器。该过滤器仅对两类请求生效,第一类是Content-Type为application/x-www-form-urlencoded的请求,第二类是Content-Type为multipart/form-data并且是由Spring的DispatherServlet处理的请求(用到了ServletDetectionFilter的处理结果)。而该过滤器的主要目的是将符合要求的请求体包装成FormBodyRequestWrapper对象。
4、DebugFilter(调试过滤器):它的执行顺序为1,是第四个执行的过滤器。该过滤器会根据配置参数zuul.debug.request和请求中的debug参数来决定是否执行过滤器中的操作。而它的具体操作内容则是将当前请求上下文中的debugRouting和debugRequest参数设置为true。由于在同一个请求的不同生命周期中都可以访问到这两个值,所以我们在后续的各个过滤器中可以利用这两个值来定义一些debug信息,这样当线上环境出现问题的时候,可以通过请求参数的方式来激活这些debug信息以帮助分析问题。另外,对于请求参数中的debug参数,我们也可以通过zuul.debug.paramter来进行自定义。
5、PreDecorationFilter(预装饰过滤器):它的执行顺序为5,是pre阶段最后被执行的过滤器。该过滤器会判断当前请求上下文中是否存在forward.to和serviceId参数,如果都不存在,那么它就会执行具体过滤器的操作(如果有一个存在的话,说明当前请求已经被处理过了,因为这两个信息就是根据当前请求的路由信息加载进来的)。而它的具体操作内容就是为当前请求做一些预处理,比如,进行路由规则的匹配、在上下文中设置该请求的基本信息以及将路由匹配结果等一些设置信息等,这些信息将是后续过滤器进行处理的重要依据,我们可以通过RequestContext.getCurrentContext()来访问这些信息。另外,我们还可以在该实现中找到一些对HTTP头请求进行处理的逻辑,其中包含了一些耳熟能详的头域,比如X-Forwarded-Host、X-Forwarded-Port(已转发主机、已转发端口)。另外,对于这些头域的记录是通过zuul.addProxyHeaders参数进行控制的,而这个参数的默认值为true,所以Zuul在请求跳转时默认会为请求增加X-Forwarded-*头域,包括X-Forwarded-Host、X-Forwarded-Port、X-Forwarded-For、X-Forwarded-Prefix、X-Forwarded-Proto。也可以通过设置zuul.addProxyHeaders=false关闭这些头域的添加动作。
route过滤器
1、RibbonRoutingFilter:它的执行顺序为10,是route阶段第一个执行的过滤器。该过滤器只对请求上下文中存在serviceId参数的请求进行处理,即只对通过serviceId配置路由规则的请求生效。而该过滤器的执行逻辑就是面向服务路由的核心,它通过使用Ribbon和Hystrix来向服务实例发起请求,并将服务实例的请求结果返回。
2、SimpleHostRoutingFilter:它的执行顺序为100,是route阶段第二个执行的过滤器。该过滤器只对请求上下文中存在routeHost参数的请求进行处理,即只对通过url配置路由规则的请求生效。而该过滤器的执行逻辑就是直接向routeHost参数的物理地址发起请求,从源码中我们可以知道该请求是直接通过httpclient包实现的,而没有使用Hystrix命令进行包装,所以这类请求并没有线程隔离和断路器的保护。
3、SendForwardFilter:它的执行顺序为500,是route阶段第三个执行的过滤器。该过滤器只对请求上下文中存在forward.to参数的请求进行处理,即用来处理路由规则中的forward本地跳转配置。
post过滤器
1、SendErrorFilter:它的执行顺序为0,是post阶段第一个执行的过滤器。该过滤器仅在请求上下文中包含error.status_code参数(由之前执行的过滤器设置的错误编码)并且还没有被该过滤器处理过的时候执行。而该过滤器的具体逻辑就是利用请求上下文中的错误信息来组成一个forward到API网关/error错误端点的请求来产生错误响应。
2、SendPesponseFilter:它的执行顺序为1000,是post阶段最后执行的过滤器。该过滤器会检查请求上下文中是否包含请求响应相关的头信息、响应数据流或是响应体,只有在包含它们其中一个的时候执行处理逻辑。而该过滤器的处理逻辑就是利用请求上下文的响应信息来组织需要发送回客户端的响应内容。
下图对上述过滤器根据顺序、名称、功能、类型做了综合整理,可以帮助我们在自定义过滤器或是扩展过滤器的时候用来参考并全面地考虑整个请求生命周期的处理过程。
异常处理
通过上面请求生命周期和核心过滤器的介绍,我们会发现在核心过滤器中没有实现error阶段的过滤器。那么当过滤器出现异常的时候需要如何处理呢?我们不妨在快速入门示例中做一个简单的试验,来看看过滤器中的异常需要被如何处理。
首先,我们尝试创建一个pre类型的过滤器,并在该过滤器的run方法实现中抛出一个异常。比如下面的实现,在run方法中调用的doSomething方法将抛出RuntimeException异常。
@Component public class ThrowExceptionFilter extends ZuulFilter { private static Logger log= LoggerFactory.getLogger(ThrowExceptionFilter.class); @Override public String filterType(){ return "pre"; } @Override public int filterOrder(){ return 0; } @Override public boolean shouldFilter(){ return true; } @Override public Object run(){ log.info("This is a pre filter,it will throw a RuntimeException"); doSomething(); return true; } private void doSomething(){ throw new RuntimeException("Exist some errors..."); } }
注意:在该类的定义上添加@Component注解,让Spring能够创建该过滤器实例,或者也可以像快速入门的例子中那样使用@Bean注解在应用主类中为其创建实例。
在添加了上面的过滤器之后,我们可以将该应用以及之前的相关应用运行起来,并根据网关配置的路由规则访问服务接口,比如http://localhost:5555/api-a/hello。此时我们会发现,在API网关服务的控制台中输出了ThrowExceptionFilter的过滤逻辑中的日志信息,但是并没有输出任何异常信息,同时发起的请求也没有获得任何响应结果。为什么会出现这样的情况呢?我们又该如何在过滤器中处理异常呢?翻遍Spring Cloud Zuul的文档以及Netflix Zuul的Wiki都没有找到相关的内容,但是这个问题却又是开发过程中普遍存在的。所以在本节中,我们将详细分析核心过滤器的异常处理机制以及如何在自定义过滤器中处理异常等内容。
try-catch处理
回想一下,我们在上一节中介绍的所有核心过滤器,是否记得有一个post过滤器SendErrorFilter是用来处理异常信息的呢?根据正常的处理流程,该过滤器会处理异常信息,那么这里没有任何异常信息说明很可能就是这个过滤器没有被执行。所以,不妨来详细看看SendErrorFilter的shouldFilter函数:
public boolean shouldFilter(){ RequestContext ctx = RequestContext.getCurrentContext();
return ctx.containKey("error.status_code")&&!ctx.getBoolean(SEND_ERROR_FILTER_RAN,false);
}
可以看到,该方法的返回值中有一个重要的判断依据ctx.containsKey("error.status_code"),也就是说请求上下文中必须要error.status_code参数,我们实现的ThrowExceptionFilter中并没有设置这个参数,所以自然不会进入SendErrorFilter过滤器的处理逻辑。那么如何使用这个参数呢?可以看一下route类型的几个过滤器,由于这些过滤器会对外发起请求,所以肯定会有异常需要处理,比如RibbonRoutingFilter的run方法实现如下:
public Object run(){ RequestContext context = RequestContext.getCurrentContext(); this.helper.addIgnoreHeaders(); try{ RibbonCommadnContext commandContext = buildCommandContext(context); ClientHttpResponse response = forward(commandContext); setRequest(response); } catch(ZuulException ex){ context.set(ERROR_STATUS_CODE,ex.nStatusCode); context.set("error.message",ex.errorCause); context.set("error.exception",ex); } catch(Exception ex){ context.set("error.status_code",HttpServerResponse.SC_INTERNAL_SERVER_ERROR); context.set("error.exception",ex); } return null; }
可以看到,整个发起请求的逻辑都采用了try-catch快处理。在catch异常的处理逻辑中并没有做任何输出操作,而是向请求上下文中添加了一些error相关的参数,主要有下面三个参数。
1、error.status_code:错误编码。
2、error.exception:Exception异常对象。
3、error.message:错误信息。
其中,error.status_code参数就是SendErrorFilter过滤器用来判断是否需要执行的重要参数。分析到这里,实现异常处理的大致思路就开始明朗了,我们可以参考RibbonRoutingFilter的实现对ThrowExceptionFilter的run方法做一些异常处理的改造。具体如下:
public Object run(){ log.info("This is a pre filter, it will throw a RuntimeException"); RequestContext ctx = RequestContext.getCurrentContext(); try{ doSomething(); }catch (Exception e){ ctx.set("error.status_code",HttpServletResponse.SC_INTERNAL_SERVER_ERROR); ctx.set("error.exception",e); } return null; }
通过上面的改造之后,我们在尝试访问之前的接口,这个时候我们可以得到如下响应内容:
{ "timestamp":, "status":500, "error","Internal Server Error", "exception":"java.lang.RuntimeException", "message":"Exist some errors..." }
此时,异常信息已经被SendErrorFilter过滤器正常处理并返回给客户端了,同时在网关的控制台中也输出了异常信息。从返回的响应信息中,可以看到几个之前我们在请求上下文中设置的内容,它们的对应关系如下所示。
1、status:对应error.status_code参数的值。
2、exception:对应error。exception参数中的Exception的类型。
3、message:对应error.exception参数中Exception的message信息。对于message的信息,我们在过滤器中还可以通过ctx.set("error.message","自定义异常消息");来定义更友好的错误信息。SendErrorFilter会优先取error.message作为返回的message内容,如果没有的话才会使用Exception中的message信息。
ErrorFilter处理
通过上面的分析与实验,我们已经知道如何在过滤器中正确处理异常,让错误信息能够顺利流转到后续的SendErorFilter过滤器来组织和输出。但是,即使我们不断强调要在过滤器中使用try-catch来处理业务逻辑并向请求上下文中添加异常信息,但是不可控的人为因素、意料之外的程序因素等,依然会使得一些异常从过滤器中抛出,对于意外抛出的异常又会导致没有控制台输出也没有任何响应信息的情况出现,那么是否有什么好的方法为这些异常做一个统一的处理呢?
这个时候,我们可以用到error类型的过滤器了。由于在请求生命周期的pre、route、post三个阶段中有异常抛出的时候都会进入error阶段的处理,所以可以通过创建一个error类型的过滤器来捕获这些异常信息,并根据这些异常信息在请求上下文中注入需要返回给客户端的错误描述。这里我们可以直接沿用在try-catch处理异常信息时用的那些error参数,这样就可以让这些信息被SendErrorFilter捕获并组织成响应消息返回给客户端。比如,下面的代码就实现了这里所描述的一个过滤器:
public class ErrorFilter extends ZuulFilter{ Logger log = LoggerFactory.getLogger(ErrorFilter.class); @Override public String filterType(){ return "error"; } @Override public int filterOrder () { return 10; } @Override public boolean shouldFilter () { return true; } @Override public Objevt run(){ RequestContext ctx = RequestContext. getCurrentContext () ; Throwable throwable = ctx. getThrowable () ; log. error ("this is a Error Filter : {) ", throwable.getCause().getMessage()); ctx.set("error.status_code", HttpServletResponse.SC_INTERNAL_SERVER—ERROR); ctx.set("error.exception", throwable.getCause()); return null; } }
在将该过滤器加入API网关服务之后,我们可以尝试使用之前介绍try-catch处理时实现的ThrowExceptionFilter(不包含异常处理机制的代码),让该过滤器能够抛出异常。这个时候我们再通过API网关来访问服务接口。此时,我们就可以在控制台中看到ThrowExceptionFilter过滤器抛出的异常信息,并且请求响应中也能获得如下的错误信息内容,而不是什么信息都没有的情况了。
{ "timestamp":, "status":500, "error","Internal Server Error", "exception":"java.lang.RuntimeException", "message":"Exist some errors..." }
不足与优化
到这里,我们已经基本掌握了在核心过滤器处理逻辑之下,对自定义过滤器中处理异常的两种基本解决方法:一种是通过在各个阶段的过滤器中增加try-catch块,实现过滤器内部的异常处理。另一种是利用error类型过滤器的生命周期特性,集中处理pre、route、post阶段抛出的异常信息。通常情况下,我们可以将这两种手段同时使用,其中第一种是对开发人员的基本要求;而第二种是对第一种处理方式的补充,以防止意外情况的发生。
这样的异常处理截止看似已经完美,但是如果在多一些应用实践或源码分析之后,我们会发现依然存在一些不足。下面,我们不妨跟着源码来看看,到底上面的方案还有哪些不足之处需要注意和进一步优化。先来看看外部请求到达API网关服务之后,各个阶段的过滤器时如何进行调度的:
try{ preRoute(); }catch(ZuulException e){ error(e); postRoute(); return; }
try{ route(); }catch(ZuulException e){ error(e); postRoute(); return; }
try{ postRoute(); }catch(ZuulException e){ error(e); return; }
上面的代码源自com.netflix.zuul.http.ZullServlet的service方法实现,它定义了Zuul外部请求过程时,各个类型过滤器的执行逻辑。从代码中我们可以看到三个try-catch块,它们依次分别代表了pre、route、post三个阶段的过滤器调用。在catch的异常处理过程中我们可以看到它们都会被error类型的过滤器进行处理(之前使用error的过滤器来定义统一的异常处理也正是利用了这个特性):error类型的过滤器处理完毕之后,除了来自post阶段的异常之外,都会再被post过滤器进行处理。所以,上面代码中各个处理阶段的逻辑如下图所示:
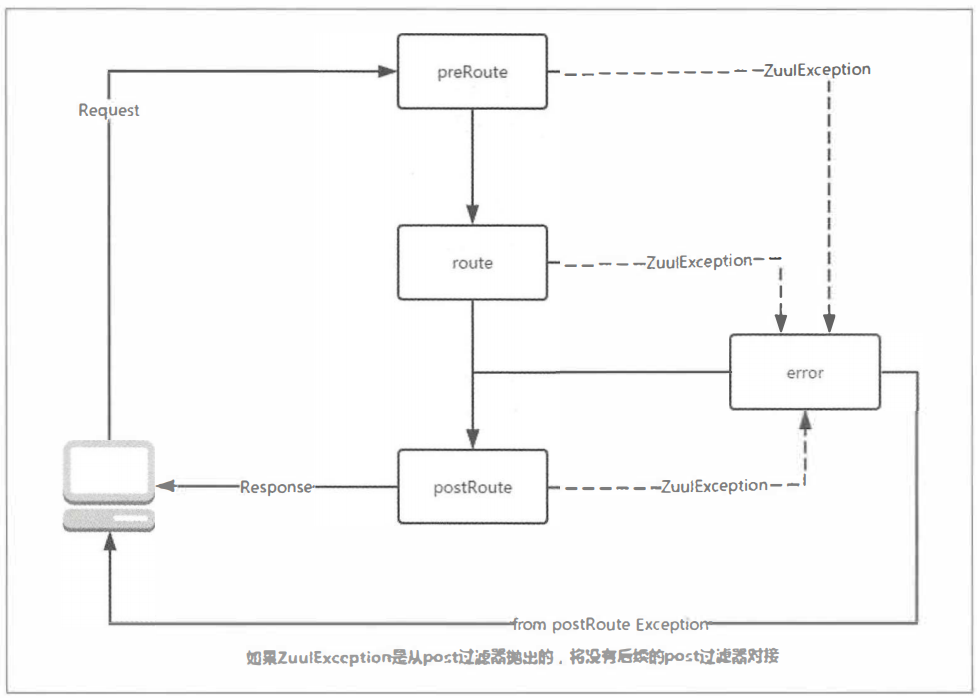
通过图中的分析,我们可以看到,对于从post过滤器中抛出异常的情况,在经过error过滤器处理之后,就没有其他类型的过滤器来接手了,这就是使用之前所述方案存在不足之处的根源。回想之前实现的两种异常处理方式,其中非常核心的一点是,这两种处理方法都在异常处理时向请求上下文中添加了一系列的error.*参数,而这些参数真正起作用的地方是在post阶段的SendErrorFilter,在该过滤器中会使用这些参数来组织内容返回给客户端。而对于post阶段抛出异常的情况下,由error过滤器处理之后并不会再调用post阶段的请求,自然这些error.*参数也就不会被SendErrorFilter消费输出。所以,如果我们在自定义post过滤器的时候,没有正确处理异常,就依然有可能出现日志中没有异常但请求响应内容为空的问题。我们可以通过将之前ThrowExceptionFilter的filterType修改为post来验证这个问题的存在,注意去掉try-catch块的处理,让它能够抛出异常。
解决上述问题的方法有很多种,最直接的是我们可以在实现error过滤器的时候,直接组织结果返回就能实现效果。但是这样做的缺点也很明显,对于错误信息组织和返回代码实现会存在多份,这样非常不利于日后的代码维护工作。所以为了保持对异常返回处理逻辑的一致性,我们还是希望将post过滤器抛出的异常交给SendErrorFilter来处理。
在前文中,我们已经实现了一个ErrorFilter来捕获pre、route、post过滤器抛出的异常,并组织error.*参数保存到请求的上下文中。由于我们的目标是沿用SendErrorFilter,这些error.*参数依然对我们有用,所以可以继续沿用该过滤器,让它在post过滤器抛出异常的时候,继续组织error.*参数,只是这里我们已经无法将这些error.*参数再传递给SendErrorFilter过滤器来处理了。所以我们需要在ErrorFilter过滤器之后再定义一个error类型的过滤器,让它来实现SendErrorFilter的功能,但是这个error过滤器并不需要处理所有出现异常的情况,它仅对post过滤器抛出的异常有效。根据上面的思路,我们完全可以创建一个继承自SendErrorFilter的过滤器,复用它的run方法,然后重写它的类型、顺序以及执行条件,实现对原有逻辑的复用,具体实现如下:
@Component public class ErrorFilter extends SendErrorFilter{ @Override public String filterType(){ return "error"; } @Override public int filterOrder(){ return 30;//大于ErrorFilter的值 } @Override public boolean shouldFilter(){ //TODO判断,仅处理来自post过滤器引起的异常 return ture; } }
到这里,我们在过滤器调度上的实现思路已经很清晰了,但是又有一个问题出现在我们面前:怎么判断引起异常的过滤器来自什么阶段呢?shouldFilter方法如何实现,对于这个问题,我们第一反应会寄希望于请求上下文RequestContext对象,可是在查阅文档和源码后发现其中并没有存储异常来源的内容,所以我们不得不扩展原来的过滤器处理逻辑。当有异常抛出的时候,记录下抛出异常的过滤器,这样我们就可以在ErrorExtFilter过滤器的shouldFilter方法中获取以此判断异常是否来自post阶段的过滤器了。
为了扩展过滤器的处理方式,为请求上下文增加一些自定义属性,我们需要深入了解Zuul过滤器的核心处理器:com.netflix.zuul.FilterProcessor。该类定义了下面列出的过滤器调用和处理相关的核心方法。
1、getInstance():该方法用来获取当前处理器的实例。
2、setProcessor(FilterProcessor proccessor):该方法用来设置处理实例,可以使用此方法来设置定义的处理器。
3、processZuulFilter(ZuulFilter filter):该方法定义了用来执行filter的具体逻辑,包括对请求上下文的设置,判断是否应该执行,执行时一些异常的处理等。
4、getFiltersByType(String filterType):该方法用来根据传入的filterType获取API网关中对应类型的过滤器,并根据这些过滤器的filterOrder从小到大排序,组织成一个列表返回。
5、runFilter(String sType):该方法会根据传入的filterType来调用getFiltersByType(String filterType)获取排序后的过滤器列表,然后轮询这些过滤器,并调用processZuulFilter(ZuulFilter filter)来依次执行它们。
6、preRoute():调用runFilters(“pre”)来执行所有pre类型的过滤器。
7、route():调用runFilters(“route”)来执行所有pre类型的过滤器。
8、postRoute():调用runFilters(“post”)来执行所有post类型的过滤器。
9、error():调用runFilters(“error”)来执行所有error类型的过滤器。
根据之前的设计,可以直接扩展processZuulFilter(ZuulFilter filter),当过滤器执行抛出异常的时候,我们捕获它,并向请求上下文中记录一些信息。比如下面的具体实现:
public class FilterProccessor extends FilterProcessor{ @Override public Object processZuulFilter(ZuulFilter filter) throws ZuulException{ try{ return super.processZuulFilter(filter); }catch(ZuulException e){ RequestContext ctx = RequestContext.getCurrentContext(); ctx.set("failed.filter",filter); throw e; } } }
在上面代码的实现中,我们创建了一个FilterProcessor的子类,并重写了processZuulFilter(ZuulFilter filter),虽然主要逻辑依然使用了父类的实现,但是在最外层,我们为其增加了异常捕获,并在异常处理中为请求上下文添加了failed.filter属性,以存储抛出异常的过滤器实例。在实现了这个扩展之后,我们也就可以完善之前ErrorExtFilter中的shouldFilter()方法了,通过从请求上下文中获取该信息作出正确的判断,具体实现如下:
@Component public class ErrorExtFilter extends SendErrorFilter{ @Override public String filterType(){ return "error"; } @Override public int filterOrder(){ return 30;//大于ErrorFilter的值 } @Override public boolean shouldFilter(){ //判断:仅处理来自post过滤器引起的异常 RequestContext ctx = RequestContext.getCurrentContext(); ZuulFilter failedFilter = (ZuulFilter) ctx.get("failed.filter"); if(failedFilter !=null &&failedFilter.filterType().equals("post")){ return true; } return false; } }
到这里,我们的优化任务还没有完成,因为扩展的过滤器处理类并还没有生效。最后,需要在应用主类中,通过调用FilterProcessor.setProcessor(new Filter-Processor());方法来启用定义的核心处理器以完成我们的优化目标。
自定义异常信息
在实现了对自定义过滤器中的异常处理之后,实际应用到业务系统中,往往默认的错误信息并不符合系统设计的响应格式,那么我们就需要对返回的异常信息进行定制。对于如何定制这个错误信息又很多种方法可以实现。最直接的是,可以编写一个自定义的post过滤器来组织错误结果,该方法实现起来简单粗暴,完全可以考虑SendErrorFilter的实现,然后直接组织请求响应结果而不是forward到/error端点,只是使用该方法时需要注意:为了替代SendErrorFilter,还需要禁用SendErrorFilter过滤器,禁用的配置方法在后文中会详细介绍。
那么如果不采用重写过滤器的方式,依然想要使用SendErrorFilter来处理异常返回的话,我们要如何定义返回的响应结果呢?这个时候,我们的关注点就不能放在Zuul的过滤器上了,因为错误信息的生成实际上并不是由Spring Cloud Zuul完成的。我们在介绍SendErrorFilter的时候提到过,它会根据请求上下中保存的错误信息来组织一个forward到/error端点的请求来获取错误响应,所以我们的扩展目标转移到了对/error端点的实现。
/error端点的实现来源于Spring Boot的org.springframework.boot.autoconfigure.web.BasicErrorController,它的具体定义如下:
@RequestMapping @ResponseBody public ResponseEntity<Map<String,Object>> error(HttpServletRequest request){ Map<String,Object> body = getErrorAttributes(request,isIncludeStackTrace(request,MediaType.ALL)); HttpStatus status = getStatus(request); return new ResponseEntity<Map<String,Object>>(body,status); }
从源码中可以看到,它的实现非常简单,通过调用getErrorAttributes方法来根据请求参数组织错误信息的返回结果,而这里的getErrorAttributes方法会将具体组织逻辑委托给org.springframework.boot.autoconfigure.web.ErrorAttributes接口提供的getErrorAttributes来实现。在Spring Boot的自动化配置机制中,默认会采用org.springframework.boot.autoconfigure.web.DefaultErrorAttributes作为该接口的实现。如下代码所示,在定义Error处理的自动化配置中,该接口的默认实现采用@ConditionalOnMissingBean修饰,说明DefaultErrorAttributes对象实例仅在没有ErrorAttributes接口的实例才会被创建来使用,所以我们只需要自己编写一个自定义的ErrorAttributes接口实现类,并创建它的实例就能替代这个默认的实现,从而达到自定义错误信息的效果。
@ConditionalOnClass({Servlet.calss,DispatcherServlet.class})
@ConditionalOnWebApplication
@AutoConfigureBefore(WebMvcAutoConfiguration.class)
@Configuration
public class ErrorMvcAutoConfiguration{
@Autowired
private ServerProperties properties;
@Bean
@ConditionalOnMissingBean(value=ErrorAttributes.class,search=SearchStrategy.CURRENT){
public DefaultErrorAttributes errorAttributes(){
return new DefaultErrorAttributes();
}
...
}
举个简单的例子,比如我们不希望将exception属性返回给客户端,那么就可以编写一个自定义的实现,它可以基于DefaultErrorAttributes,然后重写getErrorAttributes方法,从原来的结果中将exception移除即可,具体实现如下:
public class ErrorAttributes extends DefaultErrorAttributes{ @Override public Map<String,Object> getErrorAttributes(RequestAttributes requestAttributes,boolean includeStackTrace){ Map<String,Object> result = super.getErrorAttributes(requestAttributes,includeStackTrace); result.remove("exception"); return result; } }
最后,为了自定义的错误信息生成逻辑生效,需要在应用主类中加入如下代码,为其创建实例来代替默认的实现:
@Bean public DefaultErrorAttributes errorAttributes(){ return new ErrorAttributes(); }
通过上面介绍的方法,我们就能基于Zuul的核心过滤器来灵活地自定义错误返回信息,以满足实际应用系统的响应格式了。
禁用过滤器
不论是核心过滤器还是自定义过滤器,只要在API网关应用中为它们创建了实例,那么默认情况下,它们都是启用状态的。那么如果有些过滤器我们不想使用了,如何禁用它们呢?大多数情况下初识Zuul的使用者第一反应就是通过重写shouldFilter逻辑,让它返回false,这样该过滤器对于任何请求都不会被执行,基本实现了对过滤器的禁用。但是,对于自定义过滤器来说似乎是实现了过滤器不生效的功能,但是这样的做法缺乏灵活性。由于直接要修改过滤器逻辑,我们不得不重新编译程序,并且如果该过滤器在未来一段时间还有可能被启用的时候,那么就又得修改代码并编译程序。同时,对于核心过滤器来说,就更为麻烦,我们不得不获取源码来进行修改和编译。
实际上,在Zuul中特别提供了一个参数来禁用指定的过滤器,该参数的配置格式如下:
zuul.<SimpleClassName>.<filterType>.disable=true
其中,<SimpleClassName>代表过滤器的类名,比如快速入门示例中的AccessFilter;<filterType>代表过滤器类型,比如快速入门示例中AccessFilter的过滤器类型pre。所以,如果我们想要禁用快速入门示例中的AccessFilter过滤器,只需要再application.properties配置文件中增加如下配置即可:
zuul.AccessFilter.pre.disable=true
该参数配置除了可以对自定义的过滤器进行禁用配置之外,很多时候可以用它来禁用Spring Cloud Zuul中默认定义的核心过滤器。这样我们就可以抛开Spring Cloud Zuul自带的那套核心过滤器,实现一套更符合我们实际需求的处理机制。
通过本节对异常处理的介绍,也许这些方法并一定完全适用读者所接触的实际系统,但是通过这些分析可以帮助我们进一步理解Zuul过滤器的运行机制,帮助我们基于Spring Cloud Zuul去实现更适合自身系统的API网关服务。
动态加载
在微服务架构中,由于API网关服务担负着外部访问统一入口的重任,它同其他应用不同,任何关闭应用和重启应用的操作都会使系统对外服务停止,对于很多7*24小时服务的系统来说,这样的情况是绝对不被允许的。所以,作为最外部的网关,它必须具备动态更新内部逻辑的能力,比如动态修改路由规则、动态添加/删除过滤器等。
通过Zuul实现的API网关服务当然也具备了动态路由和动态过滤器的能力。我们可以在不重启API网关服务的前提下,为其动态修改路由规则和添加或删除过滤器。下面我们分别来看看如何通过Zuul来实现动态API网关服务。
动态路由
通过之前对请求路由的详细介绍,我们可以发现对于路由规则的控制几乎都可以在配置文件application.properties或application.yaml中完成。既然这样,对于如何实现Zuul的动态路由,我们很自然地会将它与Spring Cloud Config的动态刷新机制联系到一起。只需将API网关服务的配置文件通过Spring Cloud Config连接的Git仓库存储和管理,我们就能轻松实现动态刷新路由规则的功能。
在介绍如何具体实现API网关服务的动态路由之前,我们首先需要一个连接到Git仓库的分布式配置中心config-server应用。如果还没有搭建过分布式配置中心的话,建议先阅读第8章的内容,对分布式配置中心的运作机制有一个基础的了解,并构建一个config-server应用,以配合完成下面的内容。
在具备了分布式配置中心之后,为了方便理解,我们重新构建给API网关服务,该服务的配置中心不再配置本地工程中,而是从config-server中获取,构建过程如下所示。
1、创建一个基础的Spring Boot工程,命名为api-gateway-dynamic-route.
2、在pom.xml中引入对zuul、eureka和config的依赖,具体内容如下:
<parent> <groupid>org.springframework.boot</groupid> <artifactid>spring - boot - starter - parent</artifactid> <version>l.3.7.RELEASE</version> <relativePath/> </parent> <dependencies> <dependency> <groupid>org.springframework.cloud</groupid> <artifactId>spring-cloud-starter-zuul</artifactid> </dependency> <dependency> <groupid>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactid> </dependency> <dependency> <groupid>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactid> </dependency> </dependencies>
<dependencyManagement> <dependencies> <dependency> <groupid>org.springframework.cloud</groupid> <artifactId>spring - cloud - dependencies</artifactid> <version>Brixton.SR5</version> <type>pom</type> <scope>import</scope> </dependency> <dependencies> <dependencyManagement>
3、/resource目录下创建配置文件bootstrap.properties,并在该文件中指定config-server和eureka-server的具体地址,以获取应用的配置文件和实现服务注册与发现。
spring.application.name=api-gateway server.port=5556 spring.cloud.config.uri=http://localhost:7001/ eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka/
4、创建用来启动API网关的应用主类。这里我们需要使用@RefreshScope注释来将Zuul的配置内容动态化,具体实现如下:
@EnableZuulProxy @SpringCloudApplication public class Application{ public static void main(String[] args){ new SpringApplicationBuilder(Application.class).web(true).run(args); } @Bean @RefreshScope @ConfigurationProperties("zuul") publc ZuulProperties zuulPreperties(){ return new ZuulPropertis(); } }
5、在完成了所有程序相关的编写之后,我们还需要在Git仓库中增加网关的配置文件,取名为api-gateway.properties。在配置文件中,我们为API网关服务预定义以下路由规则,比如:
zuul.routes.service-a.path=/service-a/** zuul.routes.service-a.serviceId=hello-service zuul.routes.service-b.path=/service-b/** zuul.routes.service-b.url=http://localhost:8001/
对于API网关服务在Git仓库中的配置文件名称完全取决于网关应用配置文件bootstrap.properties中spring.application.name属性的配置值。由于本章我们主要介绍API网关的使用,所以这里省略了关于label和profile的配置,默认会使用master分支和default配置文件,更细致的配置方式读者可查阅第8章介绍的内容。
测试与验证
在完成了上述内容之后,我们可以将config-server、eureka-server、api-gateway-dynamic-route以及配置文件中路由规则指向的具体服务,比如hello-service启动起来。此时,在API网关应用api-gateway-dynamic-route的控制台中,我们可以看到它输出了从config-server中获取配置文件过程的日志信息,根据这些信息,可以判断获取配置信息的路径等内容是否正确。具体输出内容如下所示:
c.c.c.ConfigServicePropertySourceLocator : Fetching config from server at: http://localhost:7001/ c. c. c. ConfigServicePropertySourceLocator : Located environment: name=api-gateway, profiles=[default), label=master, version=ldab6126ca2972c5409fcb089934b057cf2bf77d b.c.PropertySourceBootstrapConfiguration : Located property source: CompositePropertySource [name= 'configService', propertySources=[MapPropertySource [name= 'overrides'), MapPropertySource [name= 'http://git.oschina.net/didispace/SpringCloud-Learning/spring_cloud-in_action /config-repo/api-gateway.properties']]] com.space.Application :No active profile set,falling back to default profiles: default
在api-gateway-dynamic-route启动完成之后,可以通过对API网关服务调用/routes接口来获取当前网关上的路由规则,根据上述配置我们可以得到如下返回信息:
{ "/service-a/**":"hello-service", "/service-b/**":"http://localhost:8001" }
我们可以先尝试着通过上述路由规则访问一下对应路由服务提供的接口,验证当前的路由规则是否生效。接着,我们开始尝试动态修改这些路由规则,只需要以下两步。
1、修改Git仓库的api-gateway.properties配置文件,比如,将service-a路由规则的path修改/aaa/**,并把service-b的路由规则从url修改为serviceId方式。具体配置如下:
zuul.routes.service-a.path=/aaa/** zuul.routes.service-a.serviceId=hello-service zuul.routes.service-b.path=/service-b/ zuul.routes.service-b.url=hello-service
2、在修改完配置文件之后,将修改内容推送到远程仓库。然后,通过向api-gateway-dynamic-route的 /refresh 接口发送POST请求来刷新配置信息。当配置文件有修改的时候,该接口返回被修改的属性名称,根据上面的修改,我们得到如下返回信息:
[
"zuul.routes.service-b.serviceId",
"zuul.routes.service-b.url",
"zuul.routes.service-a.path"
]
由于修改了service-b路由的url方式为serviceId方式,相当于删除了url参数配置,增加了serviceId参数配置,所以这里会出现两条关于service-b路由的变更信息。
到这里,我们就已经完成了路由规则的动态刷新,可以继续通过API网关服务的 /routes 接口来查看当前的所有路由规则,该接口将返回如下信息:
{
"/aaa/**":"hello-service",
"/service-b/**":"hello-service"
}
从/routes接口的信息中我们看到,路由service-a的匹配表达式被修改成了/aaa/**,而路由service-b的映射目标从原来的物理地址http://localhost:8001/修改成了hello-service服务。
通过本节对动态路由加载内容的介绍,我们可以看到,通过Zuul构建的API网关服务对于动态路由的实现总体上来说还是非常简单的。美中不足的一点是,Spring Cloud Config并没有UI管理界面,我们不得不通过Git客户端来进行修改和配置,所以在使用的时候并不是特别方便,当然有条件的团队可以自己开发一套UI界面来帮助管理这些路由规则。
动态过滤器
既然通过Zuul构建的API网关服务能够轻松地实现动态路由的加载,那么对于API网关服务的另外一大重要功能---请求过滤器的动态加载自然也不能放过,只是对于请求过滤器的动态加载与请求路由的动态加载在实现机制上会有所不同。这个不难理解,通过之前介绍的请求路由和请求过滤的示例,我们可以看到请求路由通过配置文件就能实现,而请求过滤则都是通过编码实现。所以,对于实现请求过滤器的动态加载,我们需要借助基于JVM实现的动态语言的帮助,比如Groovy。
下面,我们将通过一个简单示例来演示如何构建一个具备动态加载Groovy过滤器能力的API网关服务的详细步骤。
1、创建一个基础的Spring Boot工程,命名为api-gateway-dynamic-filter.
2、在pom.xml中引入对zuul、eureka和groovy的依赖,具体内容如下:
<parent> <groupid>org.springframework.boot</groupid> <artifactid>spring - boot - starter - parent</artifactid> <version>l.3.7.RELEASE</version> <relativePath/> </parent> <dependencies> <dependency> <groupid>org.springframework.cloud</groupid> <artifactid>spring-cloud-starter-zuul</artifactId> </dependency> <dependency> <groupid>org.springframework.cloud</groupid> <artifactid>spring-cloud-starter-eureka</artifactid> </dependency> <dependency> <groupid>org.codehaus.groovy</groupid> <artifactid>groovy-all</artifactid> </dependency> </dependencies>
<dependencyManagement> <dependencies> <dependency> <groupid>org.springframework.cloud</groupid> <artifactid>spring-cloud-dependencies</artifactid> <version>Brixton.SRS</version> <type>pom</type> <scopeimport</scope> </dependency> </dependencies> </dependencyManagement>
3、在/resource目录下创建配置文件application.properties,并在该文件中设置API网关服务的应用名和服务端口号,以及制定eureka-server的具体地址。同时,再配置一个用于测试的路由规则,我们可以用之前章节实现的hello-service为例。具体配置的内容如下:
spring.application.name=api-gateway/ server.port=5555 eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka zuul.routes.hello.path=/hello-service/** zuul.routes.hello.serviceId=hello-service
到这里一个基础的API网关服务已经构建完成,下面我们来为它们的配置值加入到application.properties中,比如:
zuul.filter.root=filter
zuul.filter.interval=5
其中,zuul.filter.root用来指定动态加载的过滤器存储路径;zuul.filter.interval用来配置动态加载的间隔时间,以秒为单位。
4、创建用来加载自定义配置属性的配置类,命名为FilterConfiguration,具体内容如下:
@ConfigurationProperties("zuul.filter")
public class FilterConfiguration{
private String root;
private Integer interval;
public String getRoot(){
return root;
}
public void setRoot(String root){
this.root=root;
}
public Integer getInterval(){
return interval;
}
public void setInterval(Integer interval){
this.interval=intercal;
}
}
5、创建应用启动主类,并在该类中引入上面定义的FilterConfiguration配置,并创建动态加载过滤器的示例。具体实例如下:
@EnableZuulProxy @EnableConfigurationProperties((FilterConfiguration.class}) @SpringCloudApplication public class Application { public static void main(String[] args) { new SpringApplicationBuilder(Application.class).web(true) .run(args);
}
@Bean public FilterLoader filterLoader(FilterConfiguration filterConfiguration) { FilterLoader filterLoader = FilterLoader.getInstance() ; filterLoader.setCompiler(new GroovyCompiler()); try { FilterFileManager.setFilenameFilter(new GroovyFileFilter()}; FilterFileManager.init( filterConfiguration.getinterval(), filterConfiguration.getRoot() + "/pre", filterConfiguration.getRoot() + "/post") ; } catch (Exception e) { throw new RuntirneException(e);
} return filterLoader;
}
}
至此,我们就已经完成了为基础的API网关服务增加动态加载过滤器的能力。根据上面的定义,API网关应用会每隔5秒,从API网关服务所在位置filter/pre和filter/post目录下获取Groovy定义的过滤器,并对其进行编译和动态加载使用。对于动态加载的时间间隔,可通过zuul.filter.interval参数来修改。而加载过滤器实现类的根目录可通过zuul.filter.root调整根目录的位置来修改,但是对于根目录的子目录,这里写死了读取/pre和/post目录,实际使用的时候读者可以进一步扩展。
在完成上述构建之后,我们可以将涉及的服务,比如eureka-server、hello-service以及上述实现的API网关服务都启动起来。在没有加入任何自定义过滤器的时候,根据路由规则定义,我们可以尝试向API网关服务发起请求:http://localhost:5555/hello-service/hello,如果配置正确,该请求会被API网关服务路由到hello-service上,并返回输出Hello World。
接下来,我们可以在filter/pre和filter/post目录下,用Groovy来创建一些过滤器来看看实际效果,举例如下。
1、在filter/pre目录下创建一个pre类型的过滤器,命名为PreFilter.groovy。由于pre类型的过滤器在请求路由前执行,通常用来做一些签名校验的功能,所以我们可以在过滤器中输出一些请求相关的信息,比如下面的实现:
class PreFilter extends ZuulFilter{ Logger log = LoggerFactory.getLogger(PreFilter.class); @Override String filterType(){ return "pre"; } @Override int filterOrder(){ return 1000; } @Override boolean shouldFilter(){ return ture; } @Override Object run(){ HttpServletRequest request = RequestContext.getCurrentContext().getRequest(); log.info("this is a pre filter:send {} request to {}", request.getMethod(),request.getRequestURL().toString()); return null; } }
在加入了该过滤器之后,不需要重启API网关服务,只需要稍等几秒就会生效。我们可以继续尝试向API网关服务发起请求:http://localhost:5555/hello-service/hello,此时在控制台中可看到PreFilter.groovy过滤器中定义的日志信息,具体如下:
com.didispace.filter.pre.PreFilter:this is a pre filter:Send GET request to http://loacalhost:5555/ddd/hello
2、在filter/post目录下创建一个post类型的过滤器,命名为PostFilter.groovy。由于post类型的过滤器在请求路由返回后执行,我们可以进一步对这个结果做一些处理,对微服务返回的信息做一些加工。比如下面的实现:
class PostFilter extends ZuulFilter{ Logger log= LoggerFactory.getLogger(PostFilter.class) ; @Override String filterType () { return "post" ; } @Override int filterOrder () { return 2000 ; } @Override boolean shouldFilter() { return true ; } @Override Object run() { log.info("this is a post filter: Receive response"); HttpServletResponse response = RequestContext.getCurrentContext ().getResponse (); response.getOutputstream(). print (", I am yjk") ; response.flushBuffer(); } }
在加入该过滤器之后,我们也不需要重启API网关服务,稍等几秒后就可以尝试向API网关服务发起请求:http://localhost:5555/hello-service/hello,此时不仅可以在控制台中看到PostFilter.groovy过滤器中定义的日志输出信息,也可以从请求返回的内容发现过滤器的效果,该接口返回的内容不再是Hello World,而是经过加工处理后的Hello World,I am yjk。
通过本节对动态过滤器加载的内容介绍,可以看到,API网关服务的动态过滤器功能可以帮助我们增强API网关的持续服务能力,对于网关中的处理逻辑也变得更为灵活,不仅可以动态地实现请求校验,还可以动态地实现对请求内容的干预。但是,目前版本下的动态过滤器还是一个半成品,从org.springframework.cloud.netflix.zuul.ZuulFilterInitializer的源码中我们也可以看到,对于动态过滤器的加载是被注释掉的,并且被标注了TODO状态。不过,目前在实际使用过程中,对于处理一些简单的常用过滤功能还是没有什么问题的,只是需要注意一些已知的问题并避开这些情况来使用即可。比如,在使用Groovy定义动态过滤器的时候,删除Groovy文件并不能从当前运行的API网关中移除这个过滤器,所以如果要移除的话可以通过修改Groovy过滤器的shouldFilter返回false。另外还需要注意一点,目前的动态过滤器是无法直接注入 API网关服务的spring容器中加载的实例来使用的,比如,我们是无法直接通过注入RestTemplate等实例,在动态过滤器中对各个微服务发起请求的。