一、报告目的
电子商务在发展过程中越来越注意消费者的用户体验,淘宝是深受中国消费者喜欢的电子商务平台,本文试图通过研究淘宝商城消费者的用户行为和潜在的需求,帮助企业制定个性化的营销方案,提高平台的运行效率。
二、数据概况
2.1 数据来源
本文的数据来自天池数据集https://tianchi.aliyun.com/dataset/dataDetail?dataId=46
2.2 数据的基本情况
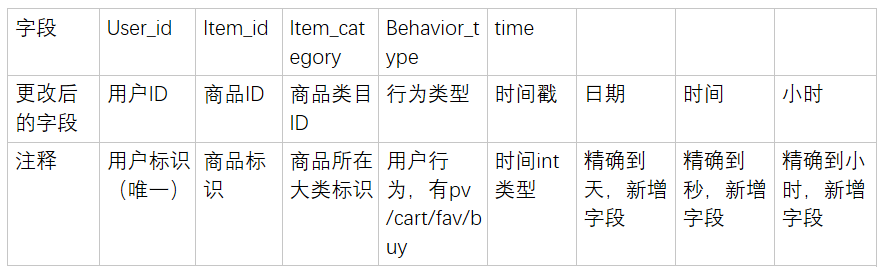
(1) 数据共有1200万条,选取其中的20万条作为报告内容。
(2) 数据清洗:清洗异常值、重复值、日期格式转换、构造新特征
(3) 数据概览
三、分析思路
3.1 流量分析
pv uv 跳失率 平均访问量,结合时间维度进行分析
3.2 用户分析
用户点击、收藏、加购、新增用户情况、用户复购率分析用户情况,用户价值模型分类
3.3 产品分析
主要产品结构、爆款产品分析
3.4 转化分析
四、分析过程
4.1 数据清洗
# 数据清洗
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('UserBehavior.csv',nrows=200000, header=None,
names= ['用户ID','商品ID','商品类目ID','行为类型','时间戳'])
data.head()
data.describe()
data.isnull().sum().sort_values(ascending=False) # 缺失值为0
data.duplicated().sum() # 重复值为0
start_time = datetime.datetime(2017,11,25)
end_time = datetime.datetime(2017,12,4)
start_ts = time.mktime(start_time.timetuple())
end_ts = time.mktime(end_time.timetuple())
data = data[(int(start_ts) <= data['时间戳']) & (data['时间戳'] <= int(end_ts))]
data['时间戳'] = data.时间戳.apply(lambda x: datetime.datetime.fromtimestamp(x))
data['日期'] = data.时间戳.dt.date
data['时间'] = data.时间戳.dt.time
data['小时'] = data.时间戳.dt.hour
4.2 流量分析
pv_date = data[data['行为类型'] == 'pv'].groupby('日期')['行为类型'].count()
uv_date = data[data['行为类型']== 'pv'].drop_duplicates(['日期','用户ID']).groupby('日期')['用户ID'].count()
print(pv_date)
print(uv_date)
# 日流量
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = pv_date.index
y1 = pv_date.values
y2 = uv_date.values
plt.plot(x,y1,label='PV',linewidth=4, color='blue', marker='o', markerfacecolor='red', markersize=4)
plt.xticks(rotation=30)
plt.xlabel('日期',size=18)
plt.ylabel('数量',size=20)
plt.title('日流量情况',size=18)
plt.legend(loc='upper left')
plt.savefig('1周流量情况')
# 日访客数
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = pv_date.index
y1 = pv_date.values
y2 = uv_date.values
plt.plot(x,y2,label='UV',linewidth=4, color='red', marker='o', markerfacecolor='black', markersize=4)
plt.xticks(rotation=30)
plt.xlabel('日期',size=18)
plt.ylabel('数量',size=20)
plt.title('访客情况',size=18)
plt.legend(loc='upper left')
plt.savefig('2一周访客情况')
# 日人均流量折线图
y3 = y1/y2
plt.plot(x,y3,label='日均浏览量',linewidth=4, color='green', marker='o', markerfacecolor='black', markersize=4)
plt.xticks(rotation=30)
plt.xlabel('日期',size=18)
plt.ylabel('数量',size=20)
plt.title('日人均浏览量',size=18)
plt.legend(loc='upper left')
plt.savefig('3日均浏览量情况')
# 时流量
# 时访客
hour_date = data[data['行为类型'] == 'pv'].groupby('小时')['行为类型'].count()
hour_uv = data[data['行为类型'] == 'pv'].drop_duplicates(['小时','用户ID']).groupby('小时')['行为类型'].count()
x = hour_date.index
y1 = hour_date.values
y2 = hour_uv.values
y2
plt.plot(x,y1,label='PV',linewidth=4, color='blue', marker='o', markerfacecolor='red', markersize=4)
plt.xticks(rotation=30)
plt.xlabel('日期',size=18)
plt.ylabel('数量',size=20)
plt.title('时流量情况',size=18)
plt.legend(loc='upper left')
plt.savefig('4时流量情况')
plt.plot(x,y2,label='PV',linewidth=4, color='red', marker='o', markerfacecolor='black', markersize=4)
plt.xticks(rotation=30)
plt.xlabel('日期',size=18)
plt.ylabel('数量',size=20)
plt.title('时访客数情况',size=18)
plt.legend(loc='upper left')
plt.savefig('4时访客数情况')
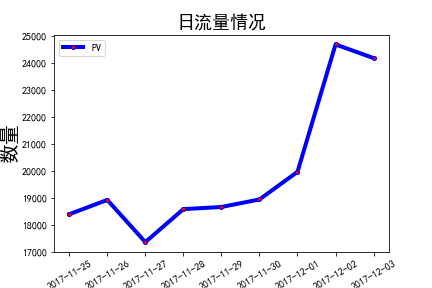
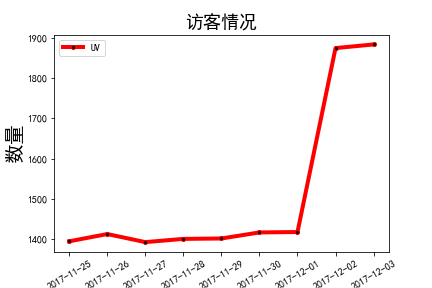
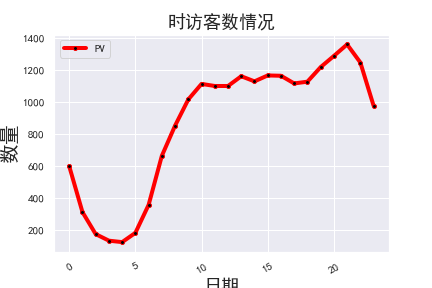
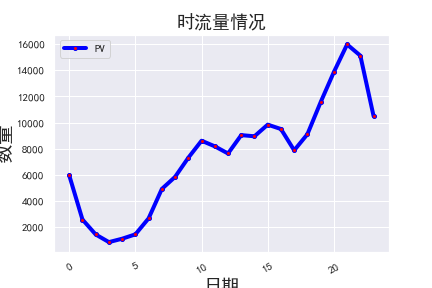
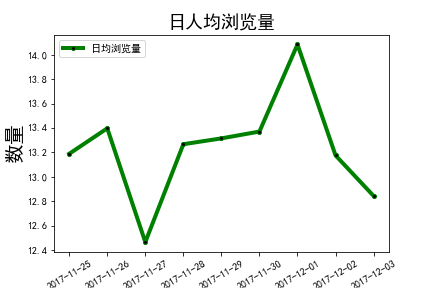
- 日PV和日UV呈上升趋势,且在11月1日至11月2日期间有大幅度提高,初步推测该平台流量有增长的态势,并在12月1日开启促销宣传活动。
- 时PV和时UV在10时以后较为平稳,并在16时至20时呈现持续增长的态势,建议在下午和晚上加强宣传引导,提高转化率
- 人均浏览量在27日下降到最低,应该分析该天的运营情况,商品宣传页面是否出现问题等。
4.3 用户分析
# 新增用户分析
from copy import deepcopy
import datetime
df_pv = df[df.行为类型 == 'pv']
s = set()
days = []
nums = []
add_pv = []
for date in df_pv['日期'].unique():
num1 = len(s)
s1 = deepcopy(s)
ids = df_pv[df_pv.日期 == date]['用户ID'].values.tolist()
for i in ids:
s.add(i)
add_users = s - s1
num2 = len(s)
days.append(date)
nums.append(num2-num1)
df_new_uv = pd.DataFrame({'日期': days, '新增访客数': nums})
df_new_uv
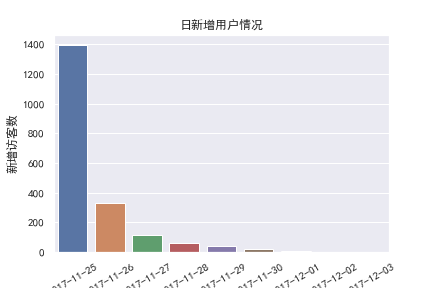
hour_behavior = data.groupby(['行为类型','小时'])['行为类型'].count()
plt.figure(figsize=(12,8))
hour_behavior['pv'].plot(color='r',label='点击')
plt.legend(fontsize=16, loc='upper right')
plt.xticks(hour_behavior['pv'].index, ['0时','1时','2时','3时','4时','5时','6时','7时','8时','9时','10时','11时','12时','13时','14时','15时','16时','17时','18时','19时','20时','21时','22时','23时'], fontsize=12)
plt.xlabel('')
plt.grid(b='False')
plt.twinx()
hour_behavior['fav'].plot(color='b', label='收藏')
hour_behavior['cart'].plot(color='k', label='加入购物车')
hour_behavior['buy'].plot(color='g', label='购买')
plt.xlabel('')
plt.xticks(hour_behavior['pv'].index, ['0时','1时','2时','3时','4时','5时','6时','7时','8时','9时','10时','11时','12时','13时','14时','15时','16时','17时','18时','19时','20时','21时','22时','23时'], fontsize=12)
plt.grid(b='False')
plt.legend()
plt.title('一天中用户行为分布折线图', fontsize=18)
plt.savefig('5一天内用户行为分析')
# 两周内用户行为分析
plt.figure(figsize=(12,8))
day_behavior = data.groupby(['行为类型','日期'])['行为类型'].count()
day_behavior['pv'].plot(color='r',label='点击')
plt.legend(fontsize=16, loc='upper right')
plt.xlabel('')
plt.xticks(rotation=30)
plt.twinx()
day_behavior['fav'].plot(color='b', label='收藏')
day_behavior['cart'].plot(color='k', label='加入购物车')
day_behavior['buy'].plot(color='g', label='购买')
plt.xlabel('')
plt.xticks(rotation=30)
plt.legend()
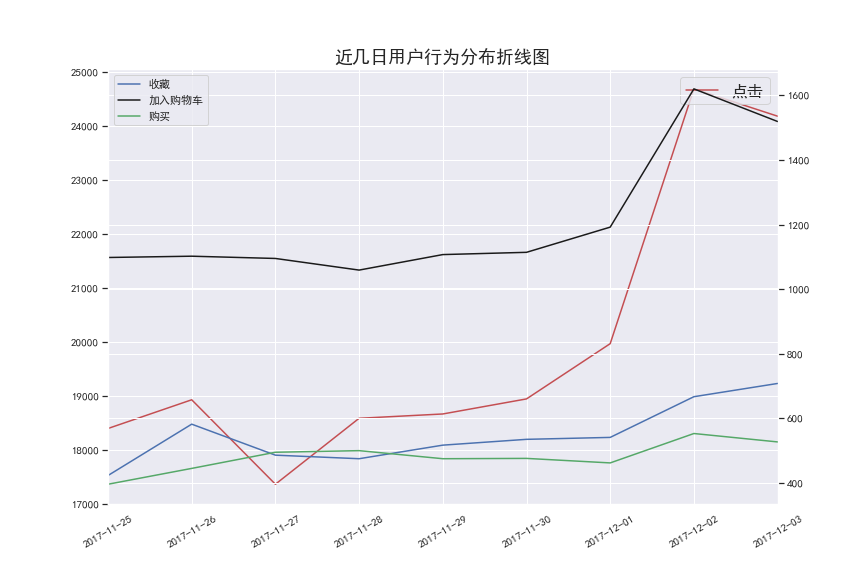
plt.title('近几日用户行为分布折线图', fontsize=18)
plt.savefig('6一周内用户行为分析')
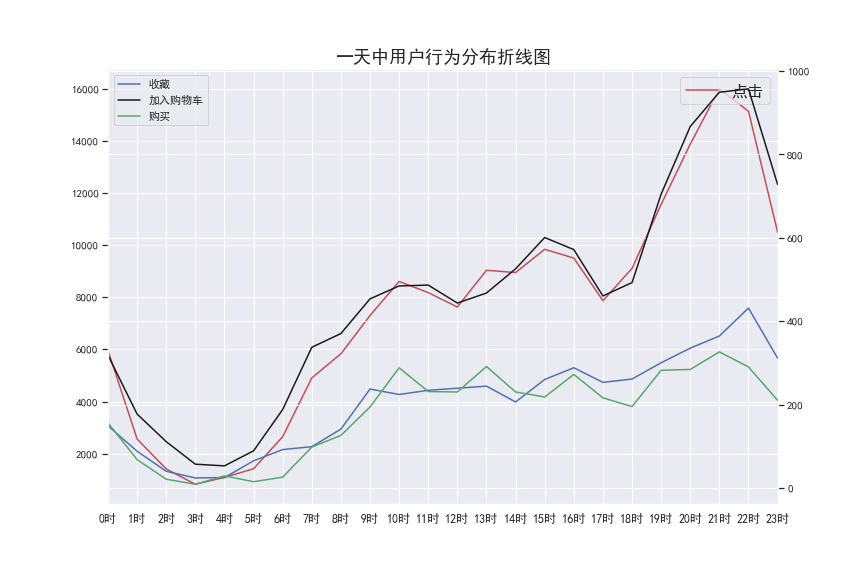
from datetime import date
nowdate = date(2017, 12, 5)
recent_buy_date = df[df.行为类型 == 'buy'].groupby('用户ID')['日期'].apply(lambda x: x.sort_values().iloc[-1])
recent_buy_time = (nowdate - recent_buy_date).map(lambda x: x.days)
fre_buy = df[df.行为类型 == 'buy'].drop_duplicates(['用户ID', '时间戳']).groupby('用户ID')['日期'].count()
rf_module = pd.DataFrame({'用户ID': recent_buy_time.index,
'recency': recent_buy_time.values,
'frequency': fre_buy.values})
rf_module.to_excel('rf.xlsx')

结论:
- 新增访客数在25日增加最多,在之后几日逐渐减少,需要增加拉新活动
- 用户收藏和购买趋势线基本拟合,可以增加活动提高收藏率,从而增加购买转化
- 18时-22时是用户活跃购买 高峰期,需要加强运营
- rfm用户价值分析:
重要价值客户:该类用户消费频次较高,最近一次消费近,应当保持当前策略维持
重要发展客户:该类用户消费频次较高,最近一次消费较远,应该通过发放优惠券、短信及时唤回
潜力客户:该类客户消费频次低,最近一次消费较近,应该通过关联商品、打折等提高消费频率
一般维持客户:该类客户消费频次低,最近一次消费低,应当通过折扣、优惠券将其挽回
4.4 转化分析
pv = data[data['行为类型'] == 'pv']['用户ID'].count()
cart = data[data['行为类型'] == 'cart']['用户ID'].count()
fav = data[data['行为类型'] == 'fav']['用户ID'].count()
buy = data[data['行为类型'] == 'buy']['用户ID'].count()
attr = ["购买:%.2f%%" % (buy / pv * 100), "收藏或加入购物车: %.2f%%" % ((fav+cart) / pv * 100),"点击量:100%"]
value = [18, 36, 54]
funnel = Funnel("转化率", width=600, height=400, title_pos='center')
funnel.add(
"商品",
attr,
value,
is_label_show=True,
label_pos="inside",
label_text_color="#fff",
is_legend_show = False
)
funnel
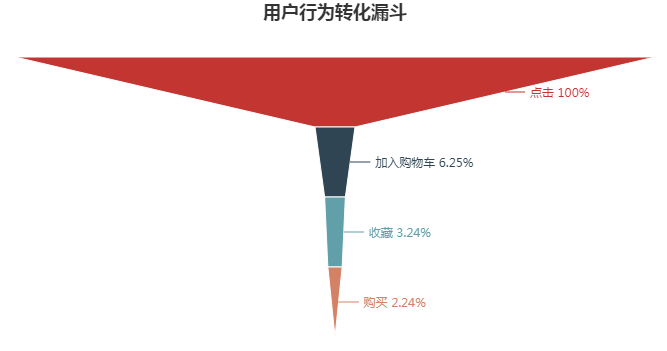
- 总的点击量中,有6.25%加入购物车,有3.24%收藏,而到最后只有2.24%购买,整体来看,购买的转化率最低,有很大的增长空间
- “点击-加入购物车“这一环节的转化率最低,按照“点击-加入购物车-收藏-购买”这一用户行为路径,我们可通过优化“点击-加入购物车”这一环节进而提升购买的转化率。
# 产品分析
# 用户关注哪些产品
goods_buy = data[data['行为类型']=='buy'].groupby('商品类目ID')['用户ID'].count().sort_values(ascending=False)
goods_buy[:10]
goods_pv = data[data['行为类型']=='pv'].groupby('商品类目ID')['用户ID'].count().sort_values(ascending=False)
goods_pv[:10]
goods_buy[:10].to_excel('goods_buy.xlsx')
goods_pv[:10].to_excel('goods_pv.xlsx')
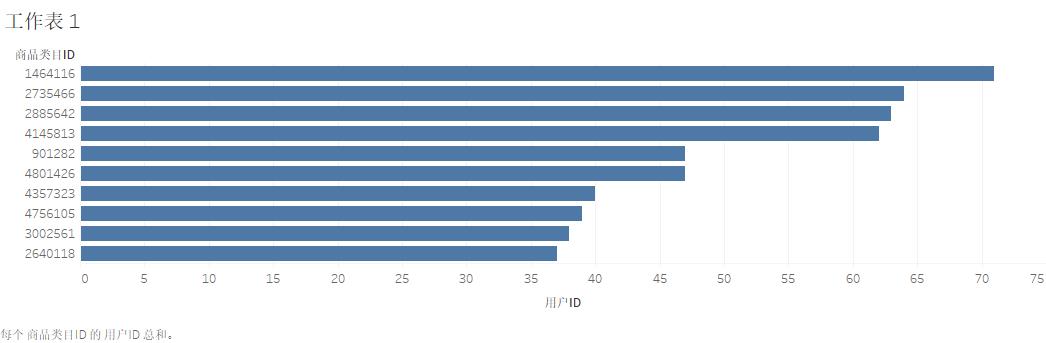
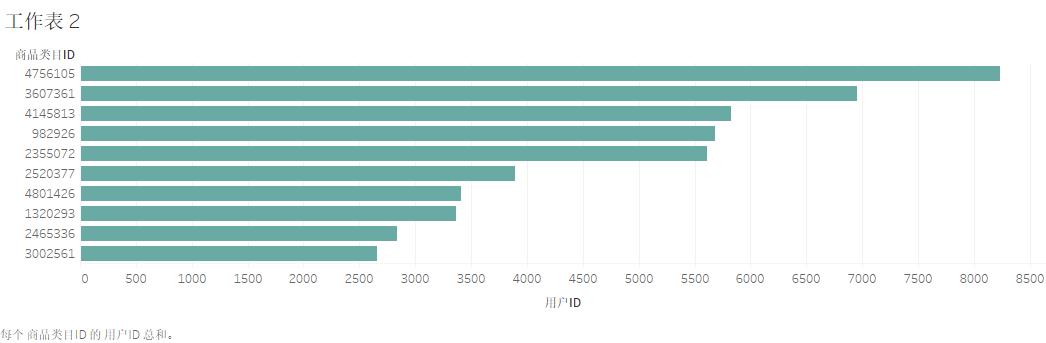
结论:通过分析找出前10位的主要产品,可以对主要产品进行精准宣传,打造爆款产品