1. python中常用的内置模块
内置模块安装的路径:python36Lib
什么是模块?
py文件 写好了的 对程序员直接提供某方面功能的文件
1.1 hashlib 摘要算法模块
可用于:
-
密文验证
-
校验文件的一致性
1.将指定的“字符串”加密 ----md5加密
import hashlib obj = hashlib.md5() obj.update('要加密的字符串') # 这里是明文 result = obj.hexdigist() # result这里是密文。 这一步py2可以执行,但py3不行,会报错,需要加encode转换编码,默认的是Unicode编码,需要转换成gbk或utf-8压缩版
md5加密永远不会被解密
import hashlib def get_md5(data): obj = hashlib.md5() obj.update(data.encode('utf-8')) result = obj.hexdigest() return result val = get_md5('123') print(val)
加盐
import hashlib def get_md5(data): obj = hashlib.md5("sidrsicxwersdfsaersdfsdfresdy54436jgfdsjdxff123ad".encode('utf-8')) # 这里加了一点盐,表示让'123'与这里一起加密,加密后才得到密文。 obj.update(data.encode('utf-8')) result = obj.hexdigest() return result val = get_md5('123') print(val)
应用:


1 import hashlib 2 USER_LIST = [] 3 def get_md5(data): 4 obj = hashlib.md5("12:;idrsicxwersdfsaersdfsdfresdy54436jgfdsjdxff123ad".encode('utf-8')) 5 obj.update(data.encode('utf-8')) 6 result = obj.hexdigest() 7 return result 8 9 10 def register(): 11 print('**************用户注册**************') 12 while True: 13 user = input('请输入用户名:') 14 if user == 'N': 15 return 16 pwd = input('请输入密码:') 17 temp = {'username':user,'password':get_md5(pwd)} 18 USER_LIST.append(temp) 19 20 def login(): 21 print('**************用户登陆**************') 22 user = input('请输入用户名:') 23 pwd = input('请输入密码:') 24 25 for item in USER_LIST: 26 if item['username'] == user and item['password'] == get_md5(pwd): 27 return True 28 29 30 register() 31 result = login() 32 if result: 33 print('登陆成功') 34 else: 35 print('登陆失败')
2.sha
sha是一个系列,一般常用sha1
import hashlib md5 = hashlib.sha1('盐'.encode()) md5.update(b'str') print(md5.hexdigest()) # 863c5545d295eef3dffe556a141a48b30565c763
1.2 getpass
(输入密码时显示*)密码不显示(只能在终端运行)(黑框里输入时才会执行该功能)
import getpass pwd = getpass.getpass('请输入密码:') if pwd == '123': print('输入正确')
1.3 random 随机
-
random.randint
import random v = random.randint(65,90) print(v) # 随机获得65~90之间的数字 import random data = [] for i in range(6) v = random.randint(65,90) data.append(chr(v)) print(''.join(data)) # 6位随机字符串验证码 import random def get_random_code(length=6): data = [] for i in range(length): v = random.randint(65,90) data.append(chr(v)) return ''.join(data) code = get_random_code() print(code) # 6位随机字符串验证码
import random # 导入一个模块 v = random.randint(起始,终止) # 得到一个随机数
-
random.uniform(1,5) # 随机小数
-
random.choice([1,2,3,4,5]) # 验证码,抽奖 (抽取一个)
-
random.sample([1,2,3,4],3) # 一个奖项抽取多个人(抽取多个,不会重复)
-
random.shuffle # 洗牌(棋牌游戏),算法
1.4 time
-
time.time 时间戳 (获取当前时间 ,是从1970年1月1日 00:00 到现在所经历的秒数)
# 计算函数执行时间 def wrapper(func): def inner(): start_time = time.time() v = func() end_time = time.time() print(end_time-start_time) return v return inner @wrapper def func1(): time.sleep(2) print(123) @wrapper def func2(): time.sleep(1) print(123) def func3(): time.sleep(1.5) print(123) func1() func2() func3()
-
time.sleep 等待秒数
-
time.timezone
# https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid=4ZwIFHM6iw==&tip=1&r=-781028520&_=1555559189206
1.5 sys
python解释器相关的数据
-
sys.getrefcount() 获取一个值的应用计数
import sys a = [11,22,33] b = a print(sys.getrefcount(a)) # 3(表示a被引用了几次:a本身/b/print,共3次)
-
sys.getrecursionlimit() 获取python默认支持的递归数量
-
sys.stdout.write() == print() 可以用于写入进度条
sys.stdout.write('你好') sys.stdout.write('呀')
换行符
制表符
回到当前行的起始位置
print('123 ',end = '') # 打印完成后回到本行的起始位置 print('你好') # '你好'把'123'给覆盖掉了(因为在起始位置打印任何内容都会把以前的内容全部覆盖掉)
import time for i in range(1,101): msg = "%s%% " %i print(msg,end='') time.sleep(0.05)
import os # 1. 读取文件大小(字节) file_size = os.stat('20190409_192149.mp4').st_size # 2.一点一点的读取文件 read_size = 0 with open('20190409_192149.mp4',mode='rb') as f1,open('a.mp4',mode='wb') as f2: while read_size < file_size: chunk = f1.read(1024) # 每次最多去读取1024字节 f2.write(chunk) read_size += len(chunk) val = int(read_size / file_size * 100) print('%s%% ' %val ,end='')
-
sys.argv()
View Code#!/usr/bin/env python # -*- coding:utf-8 -*- """ 让用户执行脚本传入要删除的文件路径,在内部帮助用将目录删除。 C:Python36python36.exe D:/code/s21day14/7.模块传参.py D:/test C:Python36python36.exe D:/code/s21day14/7.模块传参.py """ import sys # 获取用户执行脚本时,传入的参数。 # C:Python36python36.exe D:/code/s21day14/7.模块传参.py D:/test # sys.argv = [D:/code/s21day14/7.模块传参.py, D:/test] path = sys.argv[1] # 删除目录 import shutil shutil.rmtree(path)
-
sys.exit(0) 程序终止
sys.exit(0) 其中的0表示正常终止,程序只要运行到这一步,立刻跳出程序,它下面所有的代码都不再运行
-
sys.path
默认Python去导入模块时,会按照sys.path中的路径挨个查找。
# import sys # sys.path.append('D:\') # import oldboy
注意: sys.path的作用是什么?

-
练习题
-
sys.modules
存储了当前程序中用到的所有模块,反射本文件中的内容
1.6 os
和操作系统相关的数据
-
os.path.exists(path) , 如果path存在,返回True;如果path不存在,返回False
-
os.stat('20190409_192149.mp4').st_size , 获取文件大小
-
os.path.abspath() , 获取一个文件的绝对路径
path = '20190409_192149.mp4' # D:codes21day1420190409_192149.mp4 import os v1 = os.path.abspath(path) print(v1)
-
os.path.dirname ,获取路径的上级目录
import os v = r"D:codes21day1420190409_192149.mp4" print(os.path.dirname(v))
补充:
-
转义
# r 是将路径中所有关于‘c、s……’转换成‘\c、\s……’(防止python将 1当成换行符) v1 = r"D:codes21day14 1.mp4" (推荐) print(v1) v2 = "D:\code\s21day14\n1.mp4" (不建议使用) print(v2)
-
-
os.path.join ,路径的拼接
import os path = "D:codes21day14" # user/index/inx/fasd/ v = 'n.txt' result = os.path.join(path,v) print(result) result = os.path.join(path,'n1','n2','n3') print(result)
-
os.listdir , 查看一个目录下所有的文件【第一层】
import os result = os.listdir(r'D:codes21day14') for path in result: print(path)
-
os.walk , 查看一个目录下所有的文件【所有层】
import os result = os.walk(r'D:codes21day14') for a,b,c in result: # a,正在查看的目录 b,此目录下的文件夹 c,此目录下的文件 for item in c: path = os.path.join(a,item) print(path)
-
os.mkdir 创建目录(只能创建一级目录)(基本上不用)
-
os.makedirs 创建目录和子目录
import os file_path = r'dbxxxoxxxxx.txt' file_folder = os.path.dirname(file_path) if not os.path.exists(file_folder): os.makedirs(file_folder) with open(file_path,mode='w',encoding='utf-8') as f: f.write('asdf')
-
os.rename 重命名
import os os.rename('db','sb')
-
os.path.getsize 获取文件大小
-
1.7 shutil
shutil.rmtree 删除目录
import shutil shutil.rmtree(path) # 删除目录 ret = shutil.rmtree(path) print(ret) # None # 删除后没有返回值
注意:只能删除文件夹
shutil.move 重命名、移动文件
import shutil shutil.move('test','ttt')
shutil.make_archive 压缩文件
import shutil shutil.make_archive('zzh','zip','D:codes21day16lizhong')
shutil.unpack_archive 解压文件
import shutil shutil.unpack_archive('zzh.zip',format='zip') # 解压到当前文件 shutil.unpack_archive('zzh.zip',extract_dir=r'D:codexxxxxxxxxx',format='zip') # 解压到指定路径(文件的路径中没有的文件夹会自动新建)
示例
import os import shutil from datetime import datetime ctime = datetime.now() # 当前时间 ctime = datetime.now().strftime('%Y-%m-%d-%H-%M-%S') # .strftime() 用于指定当前时间的显示格式 # 1.压缩lizhongwei文件夹 zip # 2.放到到 code 目录(默认不存在) # 3.将文件解压到D:x1目录中。 if not os.path.exists('code'): os.makedirs('code') shutil.make_archive(os.path.join('code',ctime),'zip','D:codes21day16lizhongwei') file_path = os.path.join('code',ctime) + '.zip' shutil.unpack_archive(file_path,r'D:x1','zip')
1.8 json
-
json是一个特殊的字符串。 【长的像列表/字典/字符串/数字/真假】
把一个int/str/list/bool/dict/tuple转换成json格式的字符串叫做序列化。
把json格式的字符串转换成列表/字典……叫做反序列化。
json的格式:
-
1.里面只包含:int/str/list/bool/dict(不能有元组、集合)
-
2.最外层必须是 list / dict
-
3.内部str必须使用双引号“”
-
4.存在字典,字典的key只能是str
-
5.不能连续load多次
json.dumps 序列化 (被序列化后得到的是字符串类型)
json.loads 反序列化
import json # 序列化,将python的值转换为json格式的字符串。 v = [12,3,4,{'k1':'v1'},True,'asdf'] v1 = json.dumps(v) print(v1) # 反序列化,将json格式的字符串转换成python的数据类型 v2 = '["alex",123]' print(type(v2)) v3 = json.loads(v2) print(v3,type(v3))
json只支持int / str / list / dict / False / True / float / None
注意:
-
字典或列表中如有中文,序列化时想要保留中文显示:
v = {'k1':'alex','k2':'李杰'} import json val = json.dumps(v,ensure_ascii=False) print(val) -
dump
import json v = {'k1':'alex','k2':'李杰'} f = open('x.txt',mode='w',encoding='utf-8') val = json.dump(v,f) print(val) f.close()
-
load
import json v = {'k1':'alex','k2':'李杰'} f = open('x.txt',mode='r',encoding='utf-8') data = json.load(f) f.close() print(data,type(data))
-
-
jso的优点:所有语言通用;
缺点:只能序列化基本的数据类型 list/dict/int...
-
1.9 pickle
优点:1.python中几乎所有的东西都能被他序列化(socket对象);
2.支持连续load多次
缺点:序列化的内容只有python认识。
pickle.dumps 序列化 (被序列化后得到的是字节类型)
pickle.loads 反序列化
import pickle v = {1,2,3,4} val = pickle.dumps(v) print(val) data = pickle.loads(val) print(data,type(data)) def f1(): print('f1') v1 = pickle.dumps(f1) print(v1) v2 = pickle.loads(v1) v2()
pickle.dump() / pickle.load()
v = {1,2,3,4}
f = open('x.txt',mode='wb')
val = pickle.dump(v,f)
f.close()
f = open('x.txt',mode='rb')
data = pickle.load(f)
f.close()
print(data)
1.10 datetime
UTC/GMT:世界时间
本地时间:本地时区的时间。
datetime.now 当前的本地时间
datetime.utcnow 当前UTC时间
import time from datetime import datetime,timezone,timedelta # 导入模块时,短的模块在上面,长的在下面。 # ######################## 获取datetime格式时间 ######################## """ v1 = datetime.now() # 当前本地时间 print(v1) tz = timezone(timedelta(hours=7)) # 当前东7区时间 v2 = datetime.now(tz) print(v2) v3 = datetime.utcnow() # 当前UTC时间 print(v3) """ # ######################## 把datetime格式转换成字符串 #################### v1 = datetime.now() print(v1,type(v1)) val = v1.strftime("%Y-%m-%d %H:%M:%S") print(val) # ######################## 字符串转成datetime ############################ v1 = datetime.strptime('2011-11-11','%Y-%m-%d') print(v1,type(v1)) # ######################## datetime时间的加减 ############################ v1 = datetime.strptime('2011-11-11','%Y-%m-%d') v2 = v1 - timedelta(days=140) # 减140天后的时间 date = v2.strftime('%Y-%m-%d') # 把v2转换成字符串 print(date) # 用datetime时间的加减时,会用到字符串与datetime格式的转换 # ######################## 时间戳和datetime关系 ########################## ctime = time.time() print(ctime) v1 = datetime.fromtimestamp(ctime) # 把时间戳转换成datetime格式 print(v1) v1 = datetime.now() val = v1.timestamp() # 把datetime格式转换成时间戳 print(val)
1.11 (特殊)模块:importlib
根据字符串的形式导入模块
# 模块 = importlib.import_module('utils.redis') import importlib # 用字符串的形式导入模块。 redis = importlib.import_module('utils.redis') # 用字符串的形式去对象(模块)找到他的成员。 getattr(redis,'func')()
# from utils import redis import importlib middleware_classes = [ 'utils.redis.Redis', 'utils.mysql.MySQL', 'utils.mongo.Mongo' ] for path in middleware_classes: module_path,class_name = path.rsplit('.',maxsplit=1) module_object = importlib.import_module(module_path)# from utils import redis cls = getattr(module_object,class_name) obj = cls() obj.connect()
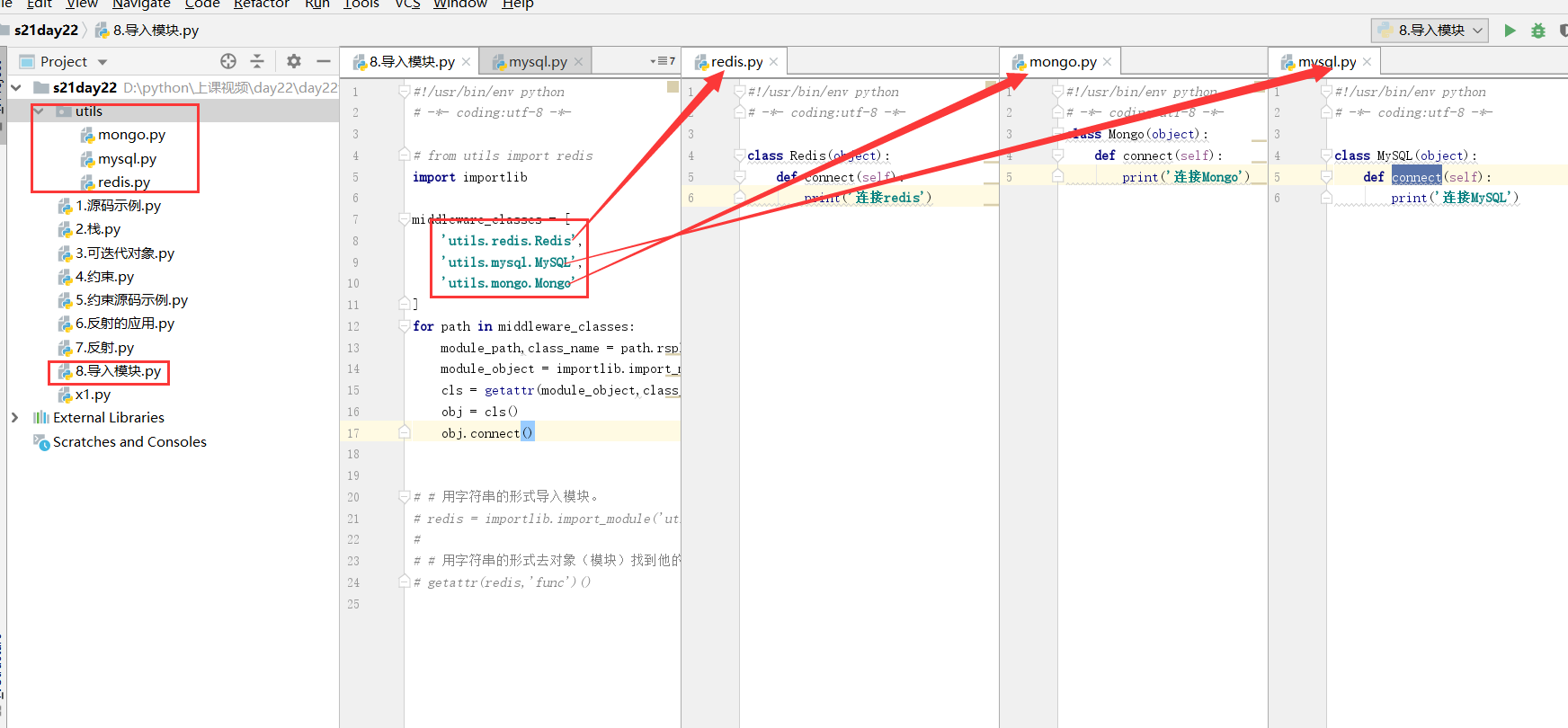
以后只用改配置文件(middleware_classes)中的内容
1.12 logging(记录日志 )
# 异常级别:由高到低 CRITICAL = 50 # 崩溃 FATAL = CRITICAL ERROR = 40 # 错误 一般常用ERROR级别 WARNING = 30 WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 # 没有设置(毫无意义) # 异常级别等于or高于设置的级别时,才会写入日志文件
注意:日志默认只接受第一次的配置,后面的配置都无效
日志一般给两种人使用:
-
用户的,如:银行流水
-
程序员的:
1. 统计用的 2. 用来做故障排除的 debug 3. 用来记录错误,完成代码的优化的
-
-
基本应用
有两种配置方式:
-
1.logging.basicconfig
优点:使用方便
缺点:不能实现编码问题;不能同时向文件和屏幕上输出
用logging.debug / logging.warning等来操作
-
2.logger对象
优点:能实现编码问题;也能同时向文件和屏幕上输出
缺点:复杂
用logger对象来操作
import logging # 创建一个logger对象 logger = logging.getLogger() # 创建一个文件操作符 fh = logging.FileHandler('log.log') # 创建一个屏幕操作符 sh = logging.StreamHandler() # 给logger对象绑定 文件操作符 logger.addHandler(fh) # 给logger对象绑定 屏幕操作符 logger.addHandler(sh) # 创建一个格式 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 给文件操作符 设定格式 fh.setFormatter(formatter) # 给屏幕操作符 设定格式 sh.setFormatter(formatter) # 用logger对象来操作 logger.warning('message')
-
-
日志处理本质:Logger/FileHandler/Formatter
import logging file_handler1 = logging.FileHandler('x2.log', 'a', encoding='utf-8') fmt1 = logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s") file_handler1.setFormatter(fmt1) logger = logging.Logger('xxxxxx', level=logging.ERROR) logger.addHandler(file_handler1) logger.error('你好')
-
推荐处理日志方式
import logging file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',) logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[file_handler,], level=logging.ERROR ) logging.error('你好')
-
推荐处理日志方式 + 日志分割 (一般按d/h来分割)
import time import logging from logging import handlers # file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',) file_handler = handlers.TimedRotatingFileHandler(filename='x3.log', when='s', interval=5, encoding='utf-8') logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[file_handler,], level=logging.ERROR ) for i in range(1,100000): time.sleep(1) logging.error(str(i))
注意事项:
# 在应用日志时,如果想要保留异常的堆栈信息。 import logging import requests logging.basicConfig( filename='wf.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=logging.ERROR ) try: requests.get('http://www.xxx.com') except Exception as e: msg = str(e) # 调用e.__str__方法 logging.error(msg,exc_info=True)
应用场景:对于异常处理捕获到的内容,使用日志模块将其保留到日志文件。
1.13 collections
-
OrderedDict 有序字典
from collections import OrderedDict info = OrderedDict() info['k1'] = 123 info['k2'] = 456 print(info.keys()) print(info.values()) print(info.items()) from collections import OrderedDict odic = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(odic) for k in odic: print(k,odic[k])
-
defaultdict 默认字典,可以给字典的value设置一个默认值
-
deque 双端队列
-
namedtuple 可命名元组
创建一个类,这个类没有方法,所有属性的值都不能修改
from collections import namedtuple Course = namedtuple('Course',['name','price','teacher']) python = Course('python',19800,'alex') print(python) print(python.name) print(python.price)
-
1.14 copy
copy.copy 浅拷贝
copy.deepcopy 深拷贝
1.15 socket(套接字)
socket 是一个工作在应用层和传输层之间的抽象层。
-
帮助我们完成了所有信息的组织和拼接
-
sokcet对于程序员来说 已经是网络操作的底层了
socket历史:
-
(初期)基于文件通信 -------- 完成同一台机器上的两个服务之间的通信的
-
(现在)基于网路通信 -------- 完成了多台机器之间的多个服务通信
方法:(详见)
-
socket用于TCP协议
-
socket用于UDP协议
1.16 struct
可用于解决TCP中粘包现象
struct.pack('i',len(内容)) # 这4个字节里只包含了一个数字,该数字是内容的长度