起因:
学习Spark Sql时,在官方文档看到两个有意思的选项pathGlobFilter 和recursiveFileLookup 。
简单地说,两个都是只对基础文件格式生效,eg: parquet,orc,avro,json.csv,text;
pathGlobFilter 是根据正则筛选要读取的文件;而recursiveFileLookup 设置为true,就会递归的读取文件,
即读取指定目录下及其子目录下的文件。
但是文档中各有一句描述这两个选项
pathGlobFilter
It does not change the behavior of partition discovery.
我翻译过来就是:它不会改变分区发现的行为。
recursiveFileLookup
recursiveFileLookupis used to recursively load files and it disables partition inferring. If data source explicitly specifies thepartitionSpecwhenrecursiveFileLookupis true, exception will be thrown.
而这句就是:recursiveFileLookup 被用于递归加载文件并禁止分区推断。如果recursiveFileLookup 设置为true并且数据源明确指定了分区字段,那么将会抛出异常。
猜想:
理解起来很奇怪,一是直译过来很拗口,二是两个参数都是用于从文件中获取数据,关分区有什么关系呐?
后来一想,从文件中读取数据后被封装到DataFrame中,DataFrame中可以使用saveAsTable保存到表中,并且可以通过partitionBy方法指定分区字段,是否和这个有关系呐?
验证:
首先在resource下准备一个目录,目录结构如下:
name/
├── name=1234/
└── name.json
name.json内容:
{"_c0":"张三1","_c1":"24"}
{"_c0":"张三2","_c1":"25"}
{"_c0":"张三3","_c1":"26"}
{"_c0":"张三4","_c1":"27"}
{"_c0":"张三5","_c1":"28"}
代码如下:
val spark = SparkSessionUtils.getLocalSparkSession()
val recursiveFileLookupDF = spark.read
.option("recursiveFileLookup", "true")
.json(this.getClass.getResource("/name").getPath)
val pathGlobFilterDF = spark.read
.option("pathGlobFilter", "*.json")
.format("json")
.load(this.getClass.getResource("/name").getPath)
// 1
pathGlobFilterDF.write
.saveAsTable("pathGlobFilter1")
// 2
pathGlobFilterDF.write
.partitionBy("name")
.saveAsTable("pathGlobFilter2")
// 3
recursiveFileLookupDF.write
.saveAsTable("recursiveFileLookup1")
// 4
recursiveFileLookupDF.write
.partitionBy("_c0")
.saveAsTable("recursiveFileLookup2")
spark.sql("select * from pathGlobFilter1").show()
spark.sql("select * from pathGlobFilter2").show()
spark.sql("select * from recursiveFileLookup1").show()
spark.sql("select * from recursiveFileLookup2").show()
SparkSessionUtils类的代码如下:
object SparkSessionUtils {
def getLocalSparkSession(): SparkSession = {
SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.testing.memory", "471859200")
.master("local[*]")
.getOrCreate()
}
}
输出结果:
// 1
+-----+---+----+
| _c0|_c1|name|
+-----+---+----+
|张三1| 24|1234|
|张三2| 25|1234|
|张三3| 26|1234|
|张三4| 27|1234|
|张三5| 28|1234|
+-----+---+----+// 2
+-----+---+----+
| _c0|_c1|name|
+-----+---+----+
|张三1| 24|1234|
|张三2| 25|1234|
|张三3| 26|1234|
|张三4| 27|1234|
|张三5| 28|1234|
+-----+---+----+// 3
+-----+---+
| _c0|_c1|
+-----+---+
|张三1| 24|
|张三2| 25|
|张三3| 26|
|张三4| 27|
|张三5| 28|
+-----+---+// 4
+---+-----+
|_c1| _c0|
+---+-----+
| 26|张三3|
| 27|张三4|
| 25|张三2|
| 28|张三5|
| 24|张三1|
+---+-----+
显著体现就是在pathGlobFilter会把目录name=1234解析成一个字段,名称为name,值为1234;而recursiveFileLookup只会把它当成一个普通的目录,递归加载其下的文件。如果了解分区表,那么就会知道分区表在路径上的体现就是分区字段=xxx。
然后在看一下表的目录结构:
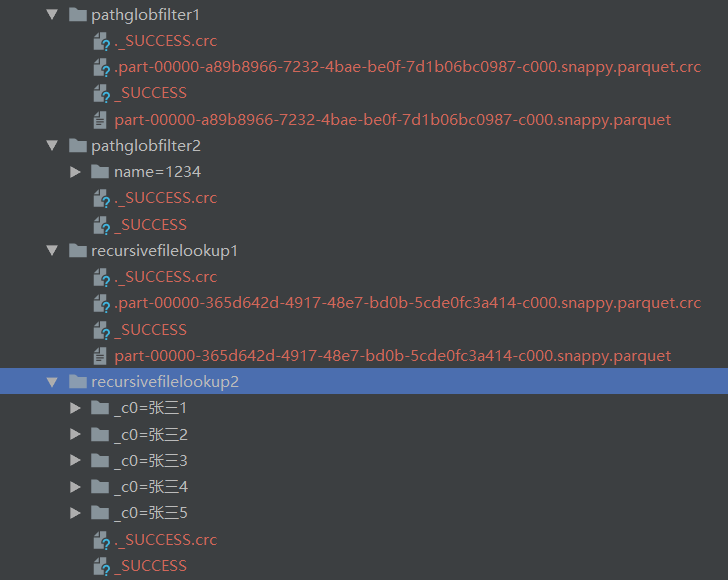
总结起来就是在load数据时,对于目录类似a=b的形式,pathGlobFilter会将其a解析成一个字段,字段值为b;而recursiveFileLookup会忽略这个特点,只会把它当成一个普通的目录,正符合官方文档描述的: it disables partition inferring。