本文章来源于: https://www.cnblogs.com/insane-Mr-Li/p/9092619.html
那我就一下面积个问题对xlrd模块进行学习一下:
1.什么是xlrd模块?
2.为什么使用xlrd模块?
3.怎样使用xlrd模块?
1.什么是xlrd模块?
♦python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。
今天就先来说一下xlrd模块:
一、安装xlrd模块
♦ 到python官网下载http://pypi.python.org/pypi/xlrd模块安装,前提是已经安装了python 环境。
♦或者在cmd窗口 pip install xlrd
二、使用介绍
♦ 0. empty(空的),1 string(text), 2 number, 3 date, 4 boolean, 5 error, 6 blank(空白表格)
import xlrd
data = xlrd.open_workbook(filename)#文件名以及路径,如果路径或者文件名有中文给前面加一个r拜师原生字符。
4、常用的函数
♦ excel中最重要的方法就是book和sheet的操作

table = data.sheets()[0] #通过索引顺序获取 table = data.sheet_by_index(sheet_indx)) #通过索引顺序获取 table = data.sheet_by_name(sheet_name)#通过名称获取 以上三个函数都会返回一个xlrd.sheet.Sheet()对象 names = data.sheet_names() #返回book中所有工作表的名字 data.sheet_loaded(sheet_name or indx) # 检查某个sheet是否导入完毕
如:

nrows = table.nrows #获取该sheet中的有效行数 table.row(rowx) #返回由该行中所有的单元格对象组成的列表 table.row_slice(rowx) #返回由该列中所有的单元格对象组成的列表 table.row_types(rowx, start_colx=0, end_colx=None) #返回由该行中所有单元格的数据类型组成的列表 table.row_values(rowx, start_colx=0, end_colx=None) #返回由该行中所有单元格的数据组成的列表 table.row_len(rowx) #返回该列的有效单元格长度

ncols = table.ncols #获取列表的有效列数 table.col(colx, start_rowx=0, end_rowx=None) #返回由该列中所有的单元格对象组成的列表 table.col_slice(colx, start_rowx=0, end_rowx=None) #返回由该列中所有的单元格对象组成的列表 table.col_types(colx, start_rowx=0, end_rowx=None) #返回由该列中所有单元格的数据类型组成的列表 table.col_values(colx, start_rowx=0, end_rowx=None) #返回由该列中所有单元格的数据组成的列表
如:

table.cell(rowx,colx) #返回单元格对象 table.cell_type(rowx,colx) #返回单元格中的数据类型 table.cell_value(rowx,colx) #返回单元格中的数据 table.cell_xf_index(rowx, colx) # 暂时还没有搞懂
♦单元格:单元格是表格中行与列的交叉部分,它是组成表格的最小单位,可拆分或者合并。单个数据的输入和修改都是在单元格中进行的
如:

注意:注意作用域问题,之前获取的sheet之后,都在获取到这个sheet值后,在进行,行和列以及单元格的操作。
♦ python解决open()函数、xlrd.open_workbook()函数文件名包含中文,sheet名包含中文报错的问题
问题现象:
♦1、使用open()函数、xlrd.open_workbook()函数打开文件,文件名若包含中文,会报错找不到这个文件或目录。
♦2、获取sheet时若包含中文,也会报错。
#打开文件 file = open(filename,'rb') #打开excel文件 workbook = xlrd.open_workbook(filename) #获取sheet sheet = workbook.sheet_by_name(sheetname)
解决方案:
♦对参数进行转码即可。如:
filename = filename.decode('utf-8')
♦也试过unicode函数,不过,在ride中运行时出现了报错,所以不赞成使用。
filename = unicode(filename,'utf-8')
2.为什么使用xlrd模块?
♦在UI自动化或者接口自动化中数据维护是一个核心,所以此模块非常实用。
3.怎样使用xlrd模块?
我们来举一个从Excel中读取账号和密码的例子并调用:
♦1.制作Excel我们要对以上输入的用户名和密码进行参数化,使得这些数据读取自Excel文件。我们将Excel文件命名为data.xlsx,其中有两列数据,第一列为username,第二列为password。
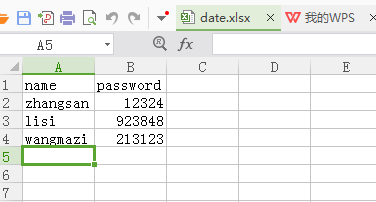
♦2.读取Excel代码如下
#-*- coding:utf-8 -*-
import xlrd,time,sys,unittest #导入xlrd等相关模块
class Data_Excel(unittest.TestCase):# 封装在Data_Excel类里面方便后面使用
file_addrec = r'C:Usersliqiang22230Desktopdate.xlsx' #定义date.xlsx数据维护Excel的路径文件
def open_excel(self,file = file_addrec):#file = file_addrec #注意在class中def中一定要带self
try:#检验文件有没有被获取到
self.data =xlrd.open_workbook(file)
return self.data
except Exception :
print(file)
print('eero')
def excel_table_byindex(self,file = file_addrec,colnameindex=0,by_index='用户表'):
#把这个读取Excel中封装在excel_table_byindex函数中,这时需要三个参数1.文件2.sheet名称,列所在的行数
self.data = xlrd.open_workbook(file)#获取Excel数据
self.table = self.data.sheet_by_name(by_index)#使用sheet_by_name获取sheet页名叫用户表的sheet对象数据
self.colnames = self.table.row_values(colnameindex)#获取行数下标为0也就是第一行Excel中第一行的所有的数据值
self.nrows = self.table.nrows #获得所有的有效行数
list = []#总体思路是把Excel中数据以字典的形式存在字符串中一个字典当成一个列表元素
for rownum in range(1,self.nrows):
row = self.table.row_values(rownum)#获取所有行数每一行的数据值
if row:
app = {}#主要以{'name': 'zhangsan', 'password': 12324.0},至于字典中有多少元素主要看有多少列
for i in range(len(self.colnames)):
#在这个Excel中,列所在的行有两个数据,所以没循环一行就以这两个数据为键,行数的值为键的值,保存在一个字典里
app[self.colnames[i]] = row[i]
list.append(app)
print(list)
return list
a = Data_Excel()
a.excel_table_byindex()
if __name__=="__main__":
unittest.main()
执行结果如下:
Testing started at 15:47 ...
[{'name': 'zhangsan', 'password': 12324.0}, {'name': 'zhangsan', 'password': 12324.0}, {'name': 'lisi', 'password': 923848.0}, {'name': 'lisi', 'password': 923848.0}, {'name': 'wangmazi', 'password': 213123.0}, {'name': 'wangmazi', 'password': 213123.0}]
Process finished with exit code 0
Empty test suite.
♦3.调用Excel代码如下:
def Login(self):
listdata = excel_table_byindex("E:\data.xlsx",0)#传入两个参数1.文件路径2.第一行所在下标
if (len(listdata) <= 0 ):#判断list列表中是否有数据
assert 0 , u"Excel数据异常"
for i in range(0 , len(listdata) ):#循环出list中所有的字典
self.driver = webdriver.Chrome()
self.driver.get("http://www.effevo.com")
assert "effevo" in self.driver.title
#点击登录按钮
self.driver.find_element_by_xpath(".//*[@id='home']/div/div[2]/header/nav/div[3]/ul/li[2]/a").click()
time.sleep(1)
self.driver.find_element_by_id('passname').send_keys(listdata[i]['username'])#切出list下标下标为i的字典键为username的值
self.driver.find_element_by_id('password').send_keys(listdata[i]['password'])#切出list下标下标为i的字典键为password的值
self.driver.find_element_by_xpath(".//*[@id='content']/div/div[6]/input").click()
time.sleep(2)
self.driver.close()
# 一段完整的代码,循环登录,取Excel中的用户名和密码去执行
import xlrd
import time
from selenium import webdriver
class Data_Excel(): #封装在Data_Excel类里面方便后面使用
file_addrec = r"E:data-excel.xlsx" #定义的数据文件
def open_excel(self,file = file_addrec):
#检查文件有没有被打开
try:
self.data = xlrd.open_workbook(file)
except:
print (file+"error")
def excel_table_byindex(self,file=file_addrec,colnameindex=0,by_index='用户表'):
# 把这个读取Excel中封装在excel_table_byindex函数中,这时需要三个参数1.文件2.sheet名称3,列所在的行数
self.data = xlrd.open_workbook(file) # 打开文件,获取Excel数据
self.table = self.data.sheet_by_name(by_index) # 获取sheet工作表,使用sheet_by_name获取sheet页名叫用户表的sheet对象数据
self.colnames = self.table.row_values(colnameindex) # 获取行数下标为0也就是第一行Excel中第一行的所有的数据值
self.nrows = self.table.nrows # 获得所有的有效行数
list = [] # 总体思路是把Excel中数据以字典的形式存在字符串中一个字典当成一个列表元素
for rownum in range(1, self.nrows): #去除定义的首行
row = self.table.row_values(rownum) # 获取所有行数每一行的数据值
# print(row)
# print(self.colnames)
if row:
app = {} # 主要以{'name': 'zhangsan', 'password': 12324.0},至于字典中有多少元素主要看有多少列
for i in range(len(self.colnames)):
# 在这个Excel中,列所在的行有两个数据,所以没循环第一行就以这两个数据为键,行数的值为键的值,保存在一个字典里
app[self.colnames[i]] = row[i]
list.append(app)
# print(list)
return list
def Login(self):
listdata = Data_Excel().excel_table_byindex(r"E:data-excel.xlsx", 0) # 传入两个参数1.文件路径2.第一行所在下标
if (len(listdata) <= 0): # 判断list列表中是否有数据
assert 0, u"Excel数据异常"
for i in range(0, len(listdata)): # 循环出list中所有的字典
self.driver = webdriver.Chrome()
self.driver.get("http://www.effevo.com")
assert "工作云 - WorkYun - 团队协作 项目-缺陷-文档 管理工具" in self.driver.title
# 点击登录按钮
self.driver.find_element_by_css_selector(".pull-left li:nth-child(1)>[class='login-in']").click()
time.sleep(1)
self.driver.find_element_by_id('passname').send_keys(listdata[i]['name']) # 切出list下标下标为i的字典键为username的值
self.driver.find_element_by_id('password').send_keys(str(listdata[i]['password'])) # 切出list下标下标为i的字典键为password的值
self.driver.find_element_by_xpath(".//*[@id='content']/div/div[6]/input").click()
time.sleep(2)
self.driver.close()
if __name__ == "__main__":
a = Data_Excel()
listdata = a.excel_table_byindex(r"E:data-excel.xlsx", 0) # 传入两个参数1.文件路径2.第一行所在下标
if (len(listdata) <= 0): # 判断list列表中是否有数据
assert 0, u"Excel数据异常"
for i in range(0, len(listdata)): # 循环出list中所有的字典
driver = webdriver.Chrome()
driver.get("http://www.effevo.com")
assert "工作云 - WorkYun - 团队协作 项目-缺陷-文档 管理工具" in driver.title
# 点击登录按钮
driver.find_element_by_css_selector(".pull-left li:nth-child(1)>[class='login-in']").click()
time.sleep(1)
driver.find_element_by_id('passname').send_keys(listdata[i]['name']) # 切出list下标下标为i的字典键为username的值
driver.find_element_by_id('password').send_keys(
str(listdata[i]['password'])) # 切出list下标下标为i的字典键为password的值
driver.find_element_by_xpath(".//*[@id='content']/div/div[6]/input").click()
time.sleep(2)
driver.close()