首先声明,本人所有博客均为原创,谢绝转载!
今天接到一个需求,如下
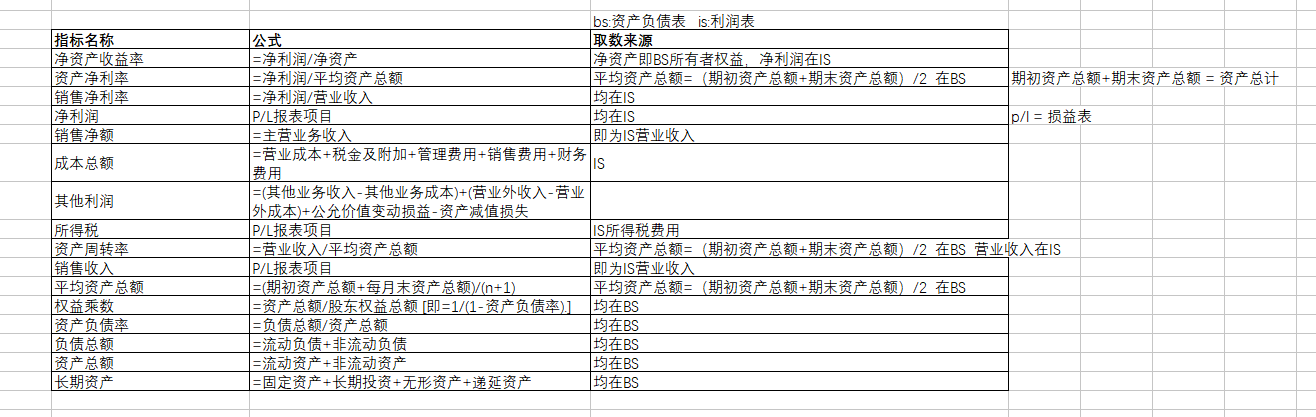
这里解释一下,为什么是几十条,因为这里面每个公式的每个条件都是一个单独的数据如净利润就是一条sql语句,而且分散在不同的表,如果此方法按照常规方法来做,为了与指标名称对应的话,那么我们就必须要一个条件一个条件的去查,然后再进行计算.
但是这样就出现了一个问题,大家都知道,在程序里,在不出现死锁的情况下,本地运行的代码其实并不耗多少时间,真正耗时间的是那些需要远程通信的,因为有一个通信时间,而我们查数据库就是一个远程通信的过程.所以,如果按照常规方案来做的话,那我们这个时间消耗
就是无法接受的,当然,按照普通方法做也不是没有解决方案的,那么就是在用户刚刚进入我们这个系统的时候,就单独开个线程去加载数据,然后存到缓存里,然后每隔一分钟就定时去刷一次数据.不过,用这种方案显然不是我的风格,所以,我就试图寻找这些条件的规律
首先,我发现这些条件是有唯一性字段的,也就是说我需要拿到这个唯一性字段然后将其跟我们现在的中文字面条件来对照下,这样的话,我就只需要根据唯一性字段把数据一次性全部查出来,然后根据唯一性字段存到缓存里即可,但是!!!这些唯一性字段是根据表来得,也就是说,不同的表可能有相同的唯一性字段,但这却是两个条件,所以,在其之上,还要加个表的区分,这个往后看自然就懂了,首先,我打开了数据库

哎呀妈呀,这要把头都看晕啊,既然这样,只好写个脚本把数据清洗一下了

nice,这才是我想要的效果,最后变成了这样

OK,这是满足了我拿数据的需求了,但我拿到数据后怎么封装呢?(在看下图之前首先,千万不要纠结我查数据的方式,这不属于任何框架的用法,是我根据自己的业务开发的一个封装条件(pinjiesql)和封装了jdbc的一个工具类(tableSQLUtiles)可能并不适合你的业务,看懂大概意思就行,我的命名还是
很规范的)
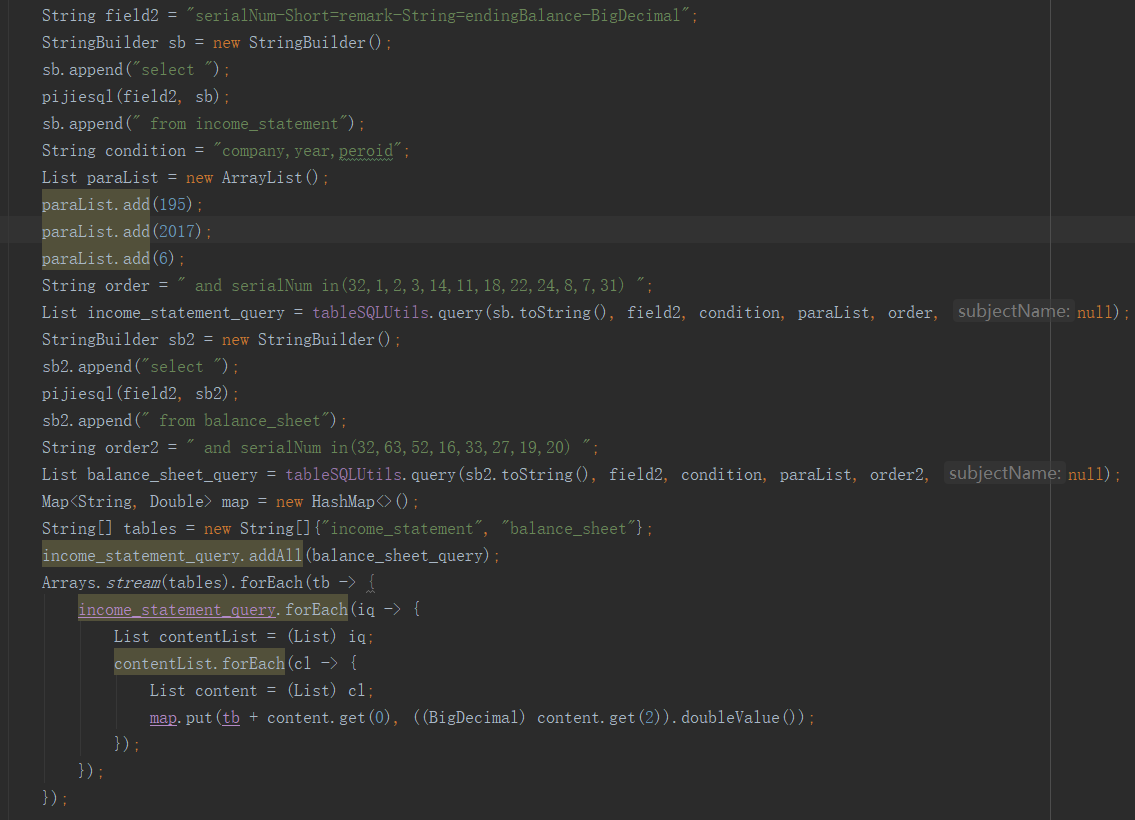
最后,再把条件按照我们之前定义的规则来计算
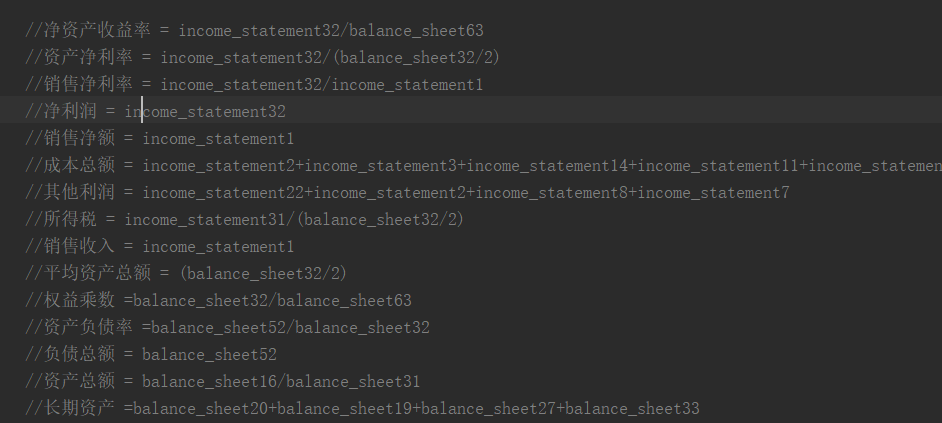
也就是这样