初识pyhton的模块:
什么是模块:
我的理解就是实现一个功能的函数,把它封装起来,在你需要使用的时候直接调用即可,我的印象里类似于shell 的单独函数脚本。
python 的模块分为标准的和第三方的,标准的直接使用即可,第三方需要安装,可以使用pip 来安装模块,这个我们以后再讲。
模块都在哪里呢?
其实模块也是一个文件,我们通过搜索发现自带的模块都在python安装目录的base/lib下,第三方的模块则是在base/lib/site-packages
如何使用模块:
我们在使用模块的某个功能时要先导入模块,类似于shell 的 source 一个函数脚本,我们使用import 来导入模块。
注意,我们在编写python 程序时的名字一定要注意不要和模块名称相同,因为python 会首先查找当前目录下的模块名称并使用,如果没有才会去找python变量路径里的模块。
几个标准模块的简单使用:
sys 模块:
1 import sys 2 print("This is ",sys.path)

当我们需要查看文件的相对路径时,可使用下面的命令:
1 import sys 2 print("This is ",sys.argv)

那当我们需要获取运行脚本时传入的参数时,使用下面的命令:
1 import sys 2 print("This is ",sys.argv[1])

os 模块:
os 模块可以执行系统命令,在windows 下执行cmd 命令 在linux 下执行shell 命令,
1 import os 2 cmd_res = os.system("ls -l") 3 print("This is >",cmd_res)

我们可以打印结果的内存地址:

即执行命令又保存结果,我们使用os.popen("ls -l").read()
1 import os 2 cmd_res = os.popen("ls -l").read() 3 print("This is >",cmd_res)

使用os 模块来创建目录:
1 import os 2 os.mkdir("new_dir")

当然我们也可以自己写模块,使用自己写的模块:
另外说一个题外话,大家都说python 是解释型语言,其实python 是先编译后解释型语言。。
不信的话你会发现py执行目录下会有一个pyc 文件,他就是一个编译后的文件,当然他完成的工作也就只有差不多10%吧,嗯,有总比没有好 哈哈。
python在执行的时候会先判断pyc文件是否存在,然后判断pyc文件时间和源代码时间的变化,对比下如果代码没变就使用pyc,如果变化了就会重新编译。
python 3 中改变了一点,不再有pyc文件但是有一个目录是存放这个的。
模块就暂时说到这里,下面我们说下python 的数据类型:
1 数字 分为
2 字符串
这个并没有什么可说的。。
3 布尔值
两种结果 True False 1 就是True 0 就是False
下面说下python 的运算:
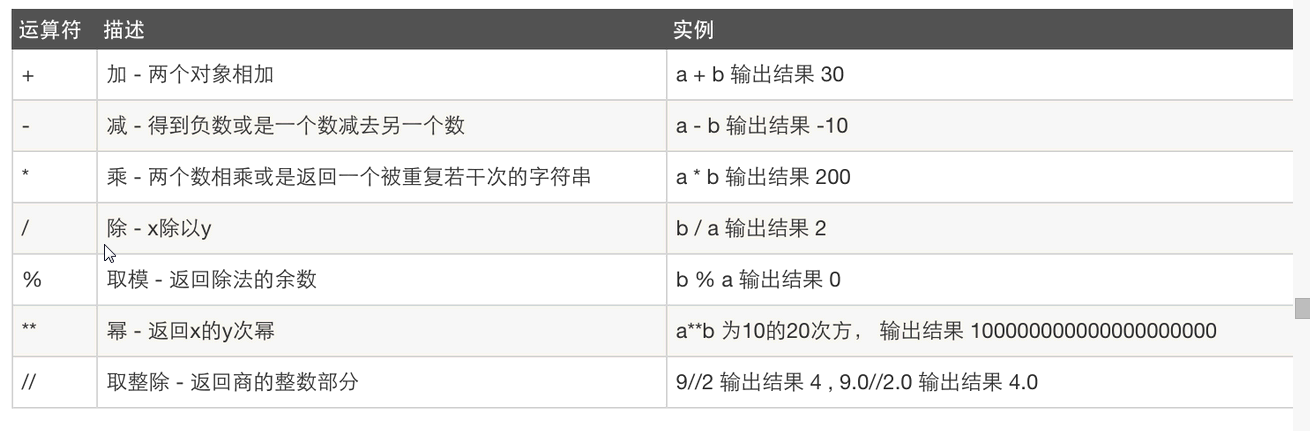
+ - * / 是我们最常用的,下面两个我们也会用到,所有不要忘记哦



1 name ="yang" 2 type(name) is str
说一个比较叼的判断方法,叫做三元运算:
1 a,b,c = 1,3,5 2 d = a if a > b else c
结果是d = 5
一个python3 比较大的变化是在python3 中 bytes 和字符串是两个类型

字符串和二进制数据转换的方法:
1 encode
把字符串转换为二进制
2 decode
把二进制还原为字符串

下面开始我们最常用的数据类型:
1 #定义一个列表 2 names = ["Shenyang","Wanglu","Shenjiangming"] 3 #取出Wanglu 4 print(names[1]) 5 #取出两个 6 print(names[1],names[2]) 7 #取多个 顾头不顾尾 #这个动作就叫切片 8 print(names[1:3]) 9 #取最后一个值,只需使用 -1 即可 10 print(names[-1])
: 左边的值是开始 右边的是结尾, 顺序是从左往右取
1 #取倒数两位 2 print(names[-2:]) 3 #前面如果是0也可以省略掉 4 print(names[:3]
增:
1 #列表里添加值: 2 #往列表里追加 3 names.append("Shenjiarui") 4 #往特定位置插入数据 5 names.insert(1,"Shenhuigang")
改:
1 #列表里替换某值: 2 names[2]="Shenjiarui"
删:
1 #列表里删除某值: 2 1 3 names.remove("Shenyang") 4 2 5 del names[0] 6 效果和 7 names.pop(0) 8 一样 9 #删掉最后一个: 10 names.pop()
其他操作:
1 #查找某个值得位置: 2 print(names.index("Shenjiangming")) 3 #查找并且打印出此值: 4 print(names[names.index("Shenjiangming")]) 5 #统计列表中重复值得个数: 6 print(names.count("Wanglu")) 7 #清空整个列表 8 names.clear() 9 #反转整个列表: 10 names.reverse() 11 #排序: 顺序 特殊字符,数字,大写字母,小写字母 12 names.sort() 13 #扩展别的列表到本列表: 14 name2 = [1,2,3] 15 names.extend(name2) 16 #删除变量: 17 del name2
1 #列表里可以包含列表 这里显示这个小列表,实际上是列表里包含的一个内存地址,这个小列表变,这个列表里的也会跟着变 2 names = ["Shenyang","Wanglu",["This","at"],"Shenjiangming"] 3 print(names)
从这里引申出一个深拷贝和浅拷贝,例如:
1 #列表copy 浅copy,只copy第一层,如果还有第二层, copy的列表里的列表的是内存地址,小列表变这里也变 2 names = ["Shenyang","Wanglu",["This","at"],"Shenjiangming"] 3 name2 = names.copy() 4 names[2][0] = "He" 5 names[1] = "Shenjiarui" 6 print(names) 7 print(name2)

1 #如果想完整的copy 一份列表,真的完全的copy一份 2 import copy 3 names = ["Shenyang","Wanglu",["This","at"],"Shenjiangming"] 4 name2 = copy.deepcopy(names) # 这种需求不多,因为会多占用一份内存 5 names[2][0] = "He" 6 names[1] = "Shenjiarui" 7 print(names) 8 print(name2)

列表的变量 指向的是内存地址,第一个变第二个也会跟着变,这里要和字符串,数字变量不同

1 #循环列表: 2 for i in names: 3 print(i) 4 5 #步长切片,跳着切 6 print(names[0:-1:2]) 7 #即 8 print(names[::2]) 9 names = ["Shenyang","Wanglu",["This","at"],"Shenjiangming"] 10 print(names[0:-1:2]) 11 print(names[::2])

1 #打印每一个: 2 print(names[:])
列表基本说完,下面说元组:
1 #元组 == 只读列表 ,只可以查,不可以改变。 2 #只有两个方法 3 1 count 4 2 index 5 names = ('Wanglu','Shenyang','Shenjiarui') 6 names.index("Wanglu") 7 8 #用途: 9 #用于不想被改的数据,例如数据库连接信息等
说了这么多我们是不是应该练练手了,大家燥起来!

会用到没学的东西,但不要紧,下面就开始学了,我们先放代码:
1 #!/usr/bin/env python3 2 # Auth: Shen Yang 3 4 shop_list = [ 5 ["Mac",5888], 6 ["Iphone",5666], 7 ["S7 Edge",6888], 8 ["Bike",800], 9 ["Ticke",60], 10 ["Mike",50], 11 ] 12 13 shop_card = [] 14 get_money = input("Please input your money: ") 15 if get_money.isdigit(): 16 get_money = int(get_money) 17 while True: 18 print("ID\tProduct\t\tMoney") 19 for index,item in enumerate(shop_list): 20 print(index,"\t",item[0],"\t\t",item[1]) 21 print("press q to exit") 22 get_want_buy = input("Input the number you want to buy: ") 23 if get_want_buy == "q": 24 print("-------------shopping list----------------") 25 for i in shop_card: 26 print(i) 27 print("your money have",get_money) 28 break 29 if get_want_buy.isdigit(): 30 get_want_buy = int(get_want_buy) 31 if get_want_buy < len(shop_list) and get_want_buy >= 0: 32 p_item = shop_list[get_want_buy] 33 if p_item[1] <= get_money: 34 print("Ok,you buy ",p_item[0]) 35 shop_card.append(p_item[0]) 36 get_money -= p_item[1] 37 else: 38 print("your money is not enough,please chose other product!") 39 continue 40 else: 41 print("Warng number,please retry!") 42 continue 43 else: 44 print("Warng number,please retry!") 45 continue 46 else: 47 print("Invaid input") 48 exit()
上面用到了 isdigit enumerate len 这三个我们没接触过的,其实他俩很简单
isdigit 判断是不是数字
enumerate 找出list 的下标(即index)
len 是计算list 中key的总数
好了,下面开始 正式说下这些奇怪的东东,
这些奇怪的东东其实就是变量的操作方法,都是内置的哦:

你会发现有好多的操作,下面请看我一一道来。。。
1 使变量首字母大写
1 name = "yang" 2 print(name.capitalize())

2 统计变量中指定项的重复次数:
1 name = "my name is yang" 2 #print(name.capitalize()) 3 print(name.count("m"))

3 如果变量不够指定的字符串数,就用指定的字符串来添加,并把变量置于中间:
1 name = "my name is yang" 2 #print(name.capitalize()) 3 #print(name.count("m")) 4 print(name.center(50,"+"))

4 判断变量是否以指定的结尾:
1 name = "my name is yang" 2 print(name.endswith("g"))

5 指定Tab的空格数:
1 name = "my name is\tyang" 2 print(name.expandtabs(tabsize=50))

6 找出指定字符串在变量中的index,可以用来字符串切片,默认从左往右找第一个,也可以指定从右开始:
1 name = "Hi,Yang is a boy" 2 print(name.rfind("a")) 3 print("------------") 4 print(name.find("a"))

7 格式化,这个我们比较常用了:
1 name = "my name is {_name}" 2 print(name.format(_name="yang"))

8 判断变量名字是否合法:
1 print("1A".isidentifier())

9 判断变量是不是小写:
1 name = "yang" 2 print(name.islower())

10 是不是大写:
1 name = "yang" 2 print(name.isupper())

11 变量是不是只有数字
1 name = "yang" 2 print(name.isdigit())

12 变量是不是空格:
1 name = " " 2 print(name.isspace())

13 判断变量是不是首字母大写:
1 name = "Ynag" 2 print(name.istitle())

14 判断变量是不是可以打印: 类似 tty drive 文件不可以打印 基本用不到
1 name = "Ynag" 2 print(name.isprintable())

15 把列表变为字符串,并指定分隔符:
1 print(" + ".join(['a','b','c','d','e']))

16 还是和center 一样 只不过这两个是不够指定的字数添加到左边或者右边:
1 name = "Yang" 2 print(name.rjust(20,"+")) 3 print(name.ljust(10,"+"))

17 把变量中所有的大写变小写,小写变大写,还有直接所有的小写变大写,大写变小写。
1 name = "Hi,Yang is a boy" 2 print(name.lower()) 3 print("-----------") 4 print(name.upper()) 5 print("-----------") 6 print(name.swapcase())

18 以指定字符串来截取变量,也可以只截取左边或者右边,如果不指定,默认会去掉空格和换行符
1 name = "88888888Yang888888" 2 print(name.strip("8")) 3 print("-----------") 4 print(name.lstrip("8")) 5 print("-----------") 6 print(name.rstrip("8"))

19 指定对应关系来加密变量:
1 p = str.maketrans("abcdefghi","123456789") 2 name = "Yang" 3 print(name.translate(p))

20 替换变量中指定的字符串:
1 name = "Yang" 2 print(name.replace("Y","H",1))

21 把字符串变量按照指定分隔符生成列表:
1 name = "Hi,Yang is a boy" 2 print(name.split(" ")) 3 print("--------------") 4 print(name.split(","))

22 把变量变为驼峰写法:
1 name = "Hi,Yang is a boy" 2 print(name.title())

23 判断变量是否足够指定的长度,如果不够使用指定的字符串补齐:
1 name = "Hi,Yang is a boy" 2 print(name.zfill(20))

特么方法这么多,写的我都手抽筋了,我先去尿个尿。。
说完方法,下面说一个很重要的变量类型: 字典
什么是字典:
字典就是一种Key Value 的变量,个人认为类似于Redis Memcached 这一类的内存型kv数据库,可以通过key 来查找对应的值(value)。
下面是一个简单的例子:
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : "girl" 6 } 7 print("Hi man ,your name is ",man_info["name"],"you like",man_info["like"])

下面讲下字典的增删改查:
查:
直接查,但是如果没有这个key 会报错:
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : "girl" 6 } 7 print(man_info["sex"]) 8 print("--------------") 9 print(man_info["job"])

报错返回提示找不到这个key,所有我建议大家用get 方法,如果没有这个key 也不会错误,只会返回None:
但是要注意哦,直接取值用[] 但是使用方法就要() 这里我犯错了。。。
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : "girl" 6 } 7 print(man_info["sex"]) 8 print("--------------") 9 print(man_info.get("job"))

改和增:
我们可以直接更改key 的值,如果这个key不存在,就会创建这个key并赋予值
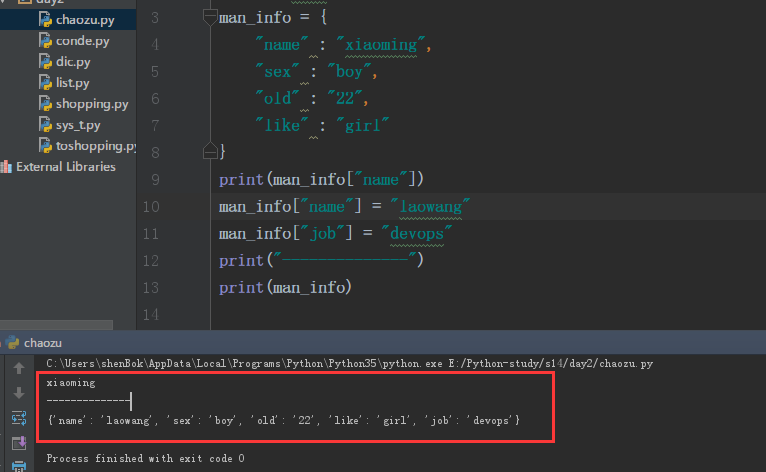
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : "girl" 6 } 7 print(man_info["name"]) 8 man_info["name"] = "laowang" 9 man_info["job"] = "devops" 10 print("--------------") 11 print(man_info)
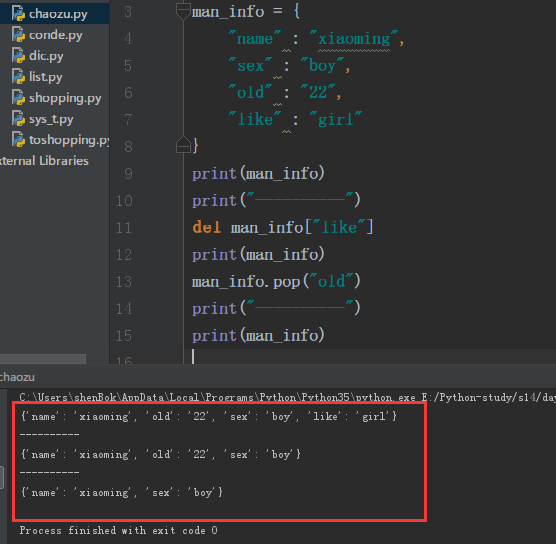
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : "girl" 6 } 7 print(man_info) 8 print("----------") 9 del man_info["like"] 10 print(man_info) 11 man_info.pop("old") 12 print("----------") 13 print(man_info)
字典的其他操作:
字典可以层层嵌套,可以嵌套不同的类型,例如嵌套 list
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : ["girl","boy","car","digital"] 6 } 7 print(man_info["like"][2])

我们可以只打印字典的值 或者只打印字典的key
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : ["girl","boy","car","digital"] 6 } 7 #打印字典全部信息 8 print(man_info) 9 #只打印字典的key 10 print(man_info.keys()) 11 #只打印字典的value 12 print(man_info.values())

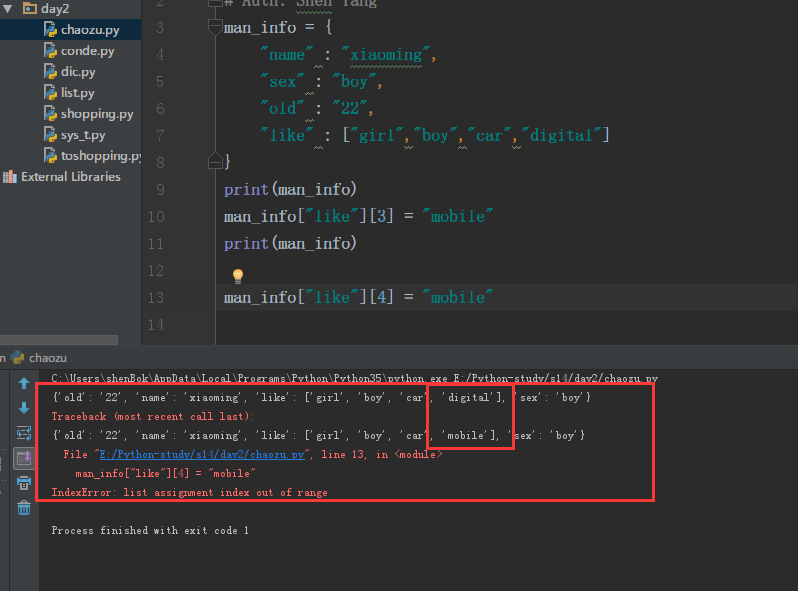
改变字典里的列表的值,如果列表中没有这个index 会报错:
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : ["girl","boy","car","digital"] 6 } 7 print(man_info) 8 man_info["like"][3] = "mobile" 9 print(man_info) 10 11 man_info["like"][4] = "mobile"
使用setdefault 来获取值,setdefault会先取这个值,如果有就取出来,如果没有,就创建一个:
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : ["girl","boy","car","digital"] 6 } 7 print(man_info.setdefault("sex","girl")) 8 print("-------------------") 9 print(man_info.setdefault("job",{"What":["fuck","off"]})) 10 print(man_info)

合并另一个字典到一个字典中:
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : ["girl","boy","car","digital"] 6 } 7 print(man_info) 8 print("--------------------") 9 other_inof = {"job" : "devops"} 10 man_info.update(other_inof) 11 print(man_info)

把一个字典转换为列表:
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : ["girl","boy","car","digital"] 6 } 7 print(man_info) 8 print("--------------------") 9 print(man_info.items())

使用dict.fromkeys来初始化一个新的字典,在用fromkeys 创建的时候,创建多层会有一个内存指向,修改一个就修改全部:
1 new_dic = dict.fromkeys([1,2,3],"yang") 2 print(new_dic) 3 print("-------------------") 4 new_dic = dict.fromkeys([1,2,3],[1,{"name":"yang"},3]) 5 print(new_dic) 6 new_dic[2][1]["name"] = "Jack Chen" 7 print(new_dic)
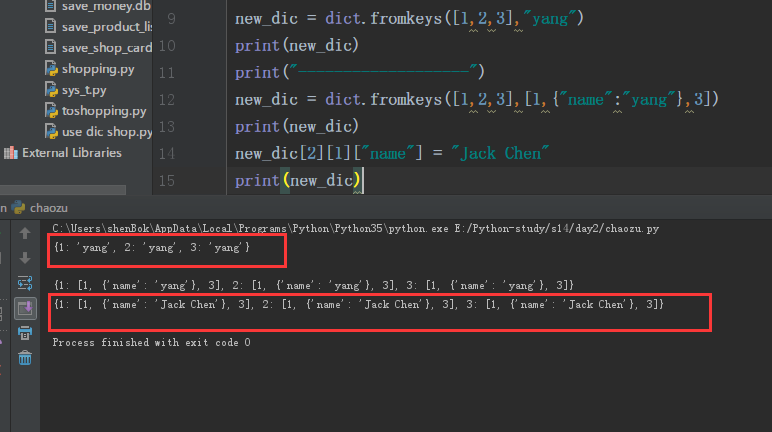
字典的循环:
1 man_info = { 2 "name" : "xiaoming", 3 "sex" : "boy", 4 "old" : "22", 5 "like" : ["girl","boy","car","digital"] 6 } 7 8 for i in man_info: 9 print("This is key :",i," And this is value:",man_info[i])

关于 dic 还没完,待续。。。