TensorFlow扩展功能
自动求导、子图的执行、计算图控制流、队列/容器
1.TensorFlow自动求导
在深度学习乃至机器学习中,计算损失函数的梯度是最基本的需求,因此TensorFlow也原生支持自动求导。
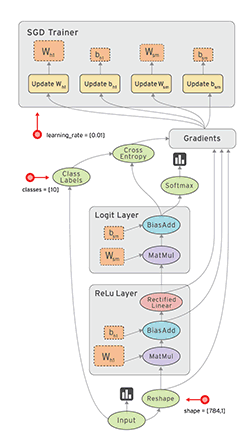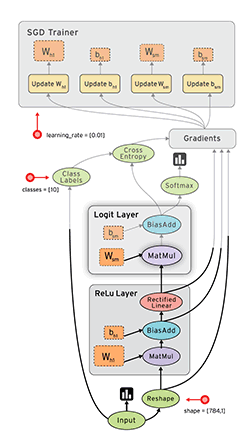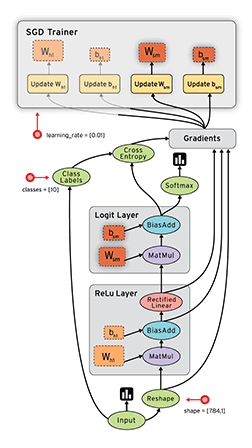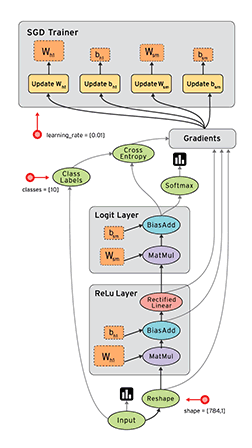
比如,一个tensor C,在计算图中有一组依赖的tensor{Xk},那么在TensorFlow中可以自动求出(dC/dXk)。这个求解梯度的过程也是通过在计算图中拓展节点的方式实现的,只不过求梯度的节点对用户是透明的(用户看不见)。
如下图,当TensorFlow计算一个tensor C关于tensor W的梯度时,会先寻找从W到C的正向路径,然后从C回溯到W,对这条回溯路径上的每一个节点增加一个对应的求解梯度的节点,并根据链式法则计算总的梯度。这就是著名的反向传播算法。这些新增的节点会计算梯度函数,比如[db, dw, dx] =tf. gradients(C,[b,w,x])
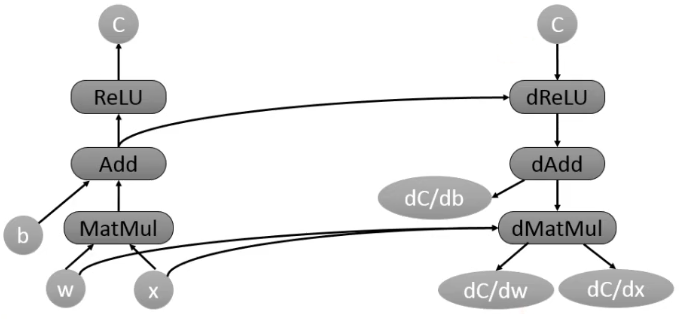
自动求导虽然对用户很方便,但伴随而来的是TensorFlow对计算的优化(比如为节点分配设备的策略)变得很麻烦,尤其是内存使用问题。
在正向计算执行图(也就是进行推断inference)时,因为确定了执行顺序,使用经验的规则是比较容易取得好效果的,tensor在产牛后会迅速的被后续节点使用掉,不会持续占有内存。
然而,进行反向传播计算梯度时,经常需要用到计算图开头的tensor,这些tensor可能会占用大量的GPU显存,也限制了模型的规模。
目前,TensorFlow仍在持续改进这些问题,包括使用更好的优化方法,重新计算tensor,而不是保存tensor; tensor从GPU显存移到CPU控制的主内存。
2.TensorFlow子图的执行
TensorFlow支持单独执行子图,用户可以选择计算图的任意子图,并沿着某些边输入数据,同时从另一些边获取输出结果。
TensorFlow用节点名加port的形式指定数据。例如,bar:0表示名为bar的节点的第一个输出。在调用Session的run方法执行子图时,用户可以选择一组输入数据的映射,比如name:port→tensor;同时,用户必须指定一组输出数据,比如name[:port],来选择执行哪些节点, 如果port也被选择,那么这些port输出的数据将会作为Run函数调用的结果返回。
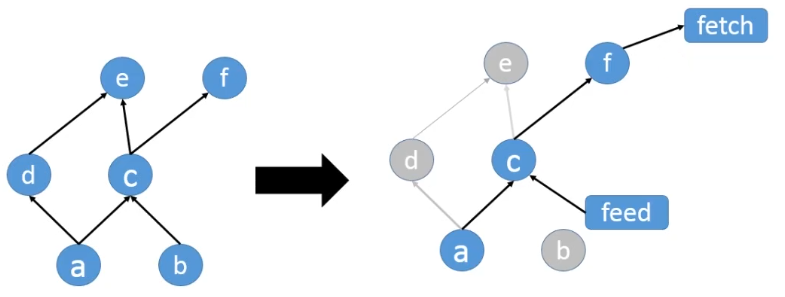
当你指定好一个输入输出的子图时,整个计算图就会根据新指定的输入输出进行调整,输入数据的节点会连接一个feed node,输出数据的节点会连接一个fetch node。 TensorFlow会根据输出数据自动推导出哪些节点需要被执行。
如图所示,我们选择用一些数据替换掉b节点,那么feed节点会替代b节点连接到c节点。同时,我们只想获取f:0的输出结果,所以一个fetch节点便会连接到f节点。这样节点d和节点e就不会被执行,所以最终需要执行的节点便只有a,c和f。
3.TensorFlow计算图控制流
大部分的机器学习算法需要大量的逻辑判断和反复迭代,所以计算图的执行控制方式显得非常重要。
TensorFlow提供Switch和Merge两种operator,可以根据某个布尔值跳过某段子图,然后把两段子图的结果合并,实现if-else的功能。
TensorFlow还提供了Enter, Leave以及Nextlteration来实现循环和迭代。在使用高阶语言如Python, Java的if-else,while,for循环设计计算图的执行流程时,这些控制流会被自动编译为上述那些operator 。Loop的每一次循环,会有唯一的tag,它的执行结果会输出成frame,这样用户可以方便的查询结果日志。
TensorFlow的控制流支持分布式,每一轮循环中的节点可能不同机器的不同设备上。分布式控制流的实现方式也是通过对计算图进行重构改写,循环内的节点会被划分到不同的小的子图上。每个子图连接控制节点,实现自己的循环。循环完成之后,循环终止信号会被发送到其他子图。
4.TensorFlow队列和容器
队列是TensorFlow任务调度的一个重要特性。这个特性可以让计算图的不同节点异步的执行。
使用队列的目的是当一个batch的数据运算时,提前从磁盘读取下一个数据,减少磁盘I/O的阻塞时间。同时还可以异步的计算许多梯度,再组合成一个更复杂的整体梯度。
除了传统的先进先出(FIFO)队列,TensorFlow还实现了洗牌队列(shuffling quene),用来满足某些机器学习算法对随机性的要求,对损失函数优化以及模型收敛会有帮助。
容器是TensorFlow中一种特殊的管理长期变量的机制,例如Variable变量对象就存放在容器中。每一个进程会有一个默认的容器一直存在,直到进程结束。使用容器还能够在不同的计算图的不同的session之间共享一些状态变量。
TensorFlow性能优化
运算操作调度、异步计算支持、第三方计算库、三种并行计算模式
1.TensorFlow运算操作节点重组与调度
TensorFlow中有很多高度抽象的运算操作。这些运算操作可能由很多复杂的计算组合而成。当有多个高阶运算操作同时存在时,他们的前几层可能是完全一致的重复计算(输入与运算内容均一致)。TensorFlow会自动识别这些重复计算,同时改写计算图,只执行一次重复的计算,然后把这些高阶运算的后续计算全部连接到这些共有的计算上,避免冗余计算。
同时,巧妙的安排运算的顺序也可以极大的改善数据传输与内存占用的问题。比如,适当调整顺序以错开某些大块头数据同时在内存中的时间,对于显存容量比较小的GPU来说,至关重要。
TensorFlow也会精细的安排接受节点的执行时间,如果接受节点过早的接收数据,那么数据会过早的堆积在设备内存中。所以,TensorFlow设计了接受策略,在刚好需要数据时才会接收数据。
2.TensorFlow异步计算
TensorFlow提供异步计算支持。这样线程执行时就无需一直等待某个计算节点完成。有一些节点,比如receive, enqueue, dequeue就是异步的实现,这些节点不必因等待I/O而阻塞一个线程继续执行其他任务。
3.TensorFlow第三方计算库
线性代数计算库Eigen、矩阵乘法计算库BLAS/cudaBLAS、深度学习计算库Cuda Convnet/cuDNN
4.TensorFlow并行计算模式
数据并行模式、模型并行模式、流水线并行模式
1)TensorFlow数据并行计算模式
通过把一个mini-batch的数据放在不同设备上计算,实现梯度计算的并行化。例如把1000个样本的mini-batch拆分成10份,每份100个样本,进行并行计算。完成后,把这10份梯度数据合并得到最终梯度并更新到共享的参数服务器(Parameter Server)。这样的操作会产生许多完全一样的子图的副本,在client上可以用一个线程同步控制这些副本运算的循环。

数据并行模式还可以用异步方式实现,使用多个线程控制梯度计算,每一个线程计算完成后,异步地更新模型参数。同步的方式相当于用了一个较大的mini-batch,优点是没有梯度干扰,缺点是容错性差。一台机器出问题后,就需要重头再来。异步的方式优点是容错性好,但是因为梯度干扰的问题,每一组的梯度利用效率下降。
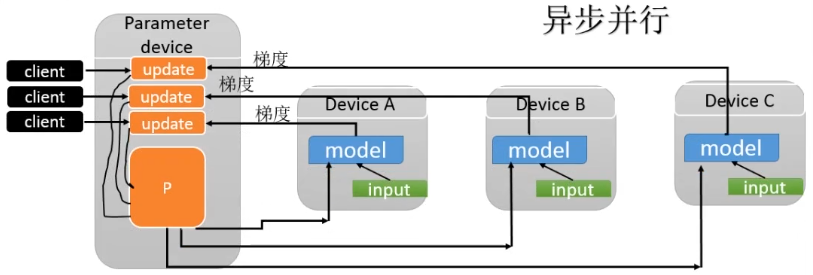
2)TensorFlow模型并行模式
模型并行就是将计算图的不同部分放在不同的设备上运算,可以实现简单的模型并行,其目标在于减少每一轮训练迭代的时间,不同于数据并行同时进行多份数据的训练。模型并行需要模型自身有大量的互不依赖或者依赖程度不高的子图。在不同硬件环境上性能损耗不同。在单核CPU上使用SIMD是没有额外开销的,在多核CPU上使用多线程基本上也没有额外开销。多GPU上的限制主要在于PCle的带宽,在多机之间的开销则在于网络通信。
3)TensorFlow流水线并行模式
和异步数据并行比较像。只不过是在同一个硬件设备上实现并行。大致思路是将计算做成流水线,在一个设备上连续的并行执行,提高设备利用率。
4)TensorFlow并行计算模式
相比于模型并行,数据并行的计算性能损耗非常小,尤其对于比较稀疏的模型。因为不同的mini-batch之间干扰的概率很小,所以经常可以进行很多份数据并行。甚至可以高达上千份。下面是Google的各个项目中使用数据并行的份数和GPU数目。
RankBrain 500份数据并行
ImageNet Inception Model 50块GPU,40倍提速
SmartReply 16份数据并行,每一份包含多块GPU
Language Model on "One Billion World" 32块GPU
TensorFlow性能优化总结
未来,TensorFlow会支持把任意子图独立出来,封装成一个函数,并让不同的前端语言( C++,Python,Java)来调用。这样,将设计好的子图发布在开源社区中,大家的工作就可以被方便地共享了。TensorFlow还计划推出优化计算图执行的Just-in-Time编译器(目前在1.x版本中已经有了XLA组件,可提供JIT以及AOT编译优化)。期望可以自动推断出tensor的类型,大小,并自动产生一条高度优化过的流水线。运算节点的硬件设备分配策略以及节点执行排序策略都将被进一步提升。
TensorFlow的特点优势
目前在单GPU的条件下,绝大多数深度学习框架都依赖于cuDNN,因此只要硬件计算能力或者内存分配差异不大,最终训练速度不会相差太大。但是,对于大规模深度学习来说,巨大的数据量使得单机很难在有限的时间内完成训练。
这时需要分布式计算使得GPU集群或TPU,集群并行计算,共同训练出一个模型,所以框架的分布式性能是至关重要的。目前,原生支持分布式计算的深度学习框架不多,只有TensorFlow,CNTK,DeepLearning4J,MXNet等。
TensorFlow Serving组件可以将TensorFlow训练好的模型导出,部署成可以对外提供预测服务的RESTfull接口,如图所示:
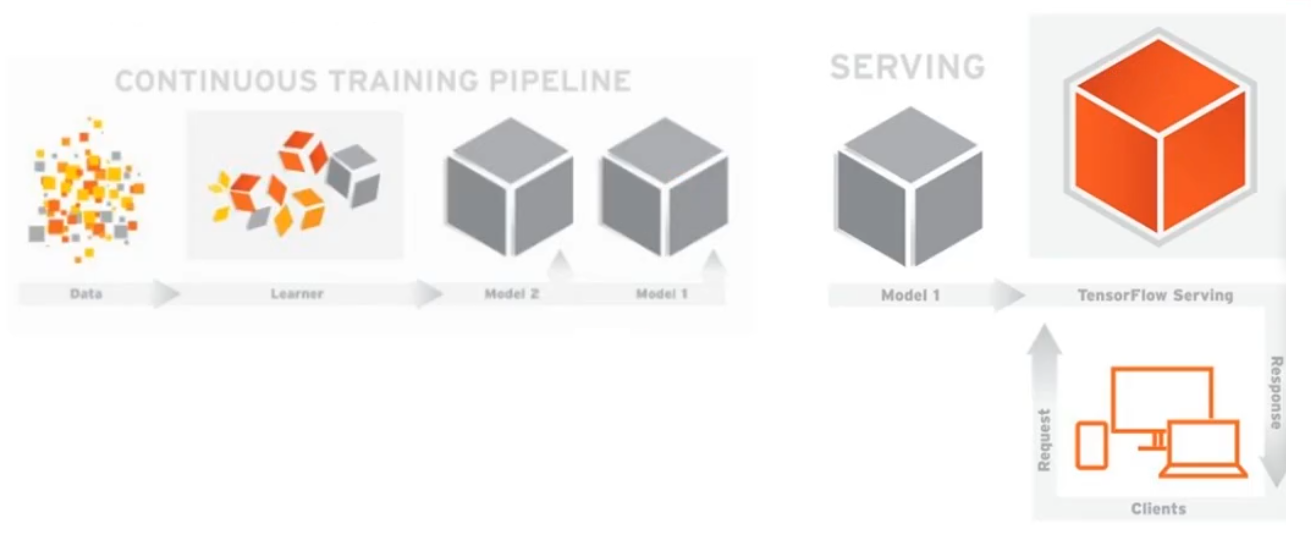
有了这个组件,TensorFlow就可以实现应用机器学习的全流程:从模型训练、参数调试,到打包模型,最后部署服务。成为从研究到生产整条流水线都齐备的框架。
TensorBoard是一组web应用,用来监控TensorFlow运行过程,或者可视化计算图。TensorBoard目前支持5种可视化:标量(Scalars),图片(lmages),音频(Audios),直方图(Histograms),计算图(Computation Graph)。
Envents DashBoard可以用来持续的监控运行时的关键指标,比如loss,学习率,验证集上的准确率。Image Dashboard则可以展示训练过程中用户保存的图片(比如用matplotlib绘制的中间结果)。 Graph Explore则可以完全展示一个TensorFlow的计算图,并且支持缩放拖曳和查看节点属性。
TensorFlow之HelloWorld基本操作
1 import tensorflow as tf 2 3 # 使用变量(variable)作为计算图的输入 4 # 构造函数返回的值代表了Variable op的输出(session运行的时候,为session提供输入) 5 # tf Graph input 6 7 a = tf.placeholder(tf.int32) 8 b = tf.placeholder(tf.int32) 9 10 # 定义一些操作 11 add = tf.add(a, b) 12 mul = tf.multiply(a, b) 13 14 # 启动默认会话 15 with tf.Session() as sess: 16 # 把运行每一个操作,把变量输入进去 17 print(sess.run(add, feed_dict={a: 2, b: 3})) 18 print(sess.run(mul, feed_dict={a: 2, b: 3}))
1 import tensorflow as tf 2 # 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点 3 # 加到默认图中. 4 # 5 # 构造器的返回值代表该常量 op 的返回值. 6 matrix1 = tf.constant([[3.,3.]]) 7 # 创建另外一个常量 op, 产生一个 2x1 矩阵. 8 matrix2 = tf.constant([[2.],[2.]]) 9 10 # 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入. 11 # 返回值 'product' 代表矩阵乘法的结果. 12 product = tf.matmul(matrix1,matrix2) 13 14 # 启动默认图. 15 #sess = tf.Session() 16 # 调用 sess 的 'run()' 方法来执行矩阵乘法 op, 传入 'product' 作为该方法的参数. 17 # 上面提到, 'product' 代表了矩阵乘法 op 的输出, 传入它是向方法表明, 我们希望取回 18 # 矩阵乘法 op 的输出. 19 # 20 # 整个执行过程是自动化的, 会话负责传递 op 所需的全部输入. op 通常是并发执行的. 21 # 22 # 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行. 23 #print(sess.run(product)) 24 # ==> [[ 12.]] 25 26 # 任务完成, 关闭会话. 27 #sess.close() 28 with tf.Session() as sess: 29 print(sess.run(product))
TensorFlow实现最近邻分类器
K近邻分类模型基本原理
K近邻分类模型的三个基本要素:
(a)距离度量;(b)k值的选择;(c)分类决策规则
有关KNN可以看一下https://www.cnblogs.com/pinard/p/6061661.html非常不错的一篇博文,阅读量41323
1 import numpy as np 2 import tensorflow as tf 3 4 from tensorflow.examples.tutorials.mnist import input_data 5 mnist = input_data.read_data_sets('mnist_data/', one_hot=True) 6 7 Xtrain, Ytrain = mnist.train.next_batch(5000) 8 Xtest, Ytest = mnist.test.next_batch(200) 9 print('Xtrain.shape: ',Xtrain.shape,',Xtest.shape: ',Xtest.shape) 10 print('Ytrain.shape: ',Ytrain.shape, ',Ytest.shape: ',Ytest.shape) 11 12 # 计算图输入占位符 13 xtrain = tf.placeholder("float", [None, 784]) 14 xtest = tf.placeholder('float', [784]) 15 16 # 使用L1距离进行最近邻计算 17 # 计算L1距离 18 distance = tf.reduce_sum(tf.abs(tf.add(xtrain, tf.negative(xtest))),axis=1) 19 # 预测:获得最小距离的索引(根据最近邻的雷标签进行判断) 20 pred = tf.arg_min(distance, 0) 21 # 评估:判断给定的一条测试样本是否预测正确 22 23 # 最近邻分类器的准确率 24 accuracy = 0. 25 26 # 初始化节点 27 init = tf.global_variables_initializer() 28 29 # 启动会话 30 with tf.Session() as sess: 31 sess.run(init) 32 Ntest = len(Xtest) # 测试样本的数量 33 # 在测试集上进行循环 34 for i in range(Ntest): 35 # 获取当前测试样本的最近邻 36 nn_index = sess.run(pred, feed_dict={xtrain:Xtrain, xtest:Xtest[i,:]}) 37 # 获得最近邻预测标签,然后与真实的类标签比较 38 pred_class_label = np.argmax(Ytrain[nn_index]) 39 true_class_label = np.argmax(Ytest[i]) 40 print("Test", i, "Predicted Class Label:", pred_class_label, 41 "True Class Label:", true_class_label) 42 # 计算准确率 43 if pred_class_label == true_class_label: 44 accuracy += 1 45 print("Done!") 46 accuracy /= Ntest 47 print("Accuracy:", accuracy)