Word2Vec的主要目的适用于词的特征提取,然后我们就可以用LSTM等神经网络对这些特征进行训练。
由于机器学习无法直接对文本信息进行有效的处理,机器学习只对数字,向量,多维数组敏感,所以在进行文本训练之前还要做一些转化工作,Word2Vec就是担负此重任的有效工具,当然还有其他工具,就不再说明。本次只是简单介绍Word2Vec的工作原理,想要详细理解还请看一下文章最后分享的链接。
Word2Vec工作过程
1.建立字典,每个词生成 one-hot 向量
Word个数为 n ,产生 n 维向量,第i 个 word 的向量为(0, 0, 0,…. 1, 0, 0, 0, 0)其中1的位置在向量的第i个位置上。
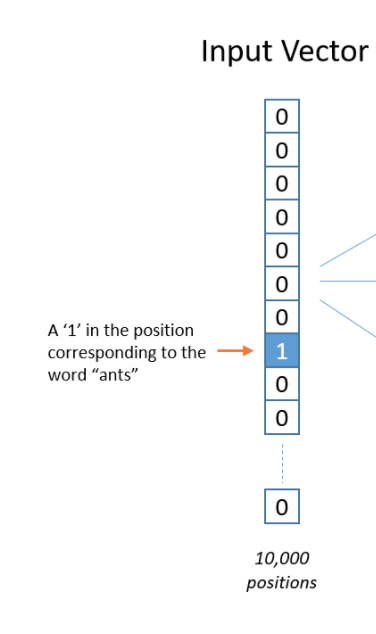
2.训练数据集构建
我门可以使用长度为4的滑动窗口进行取“词对”,如下图:

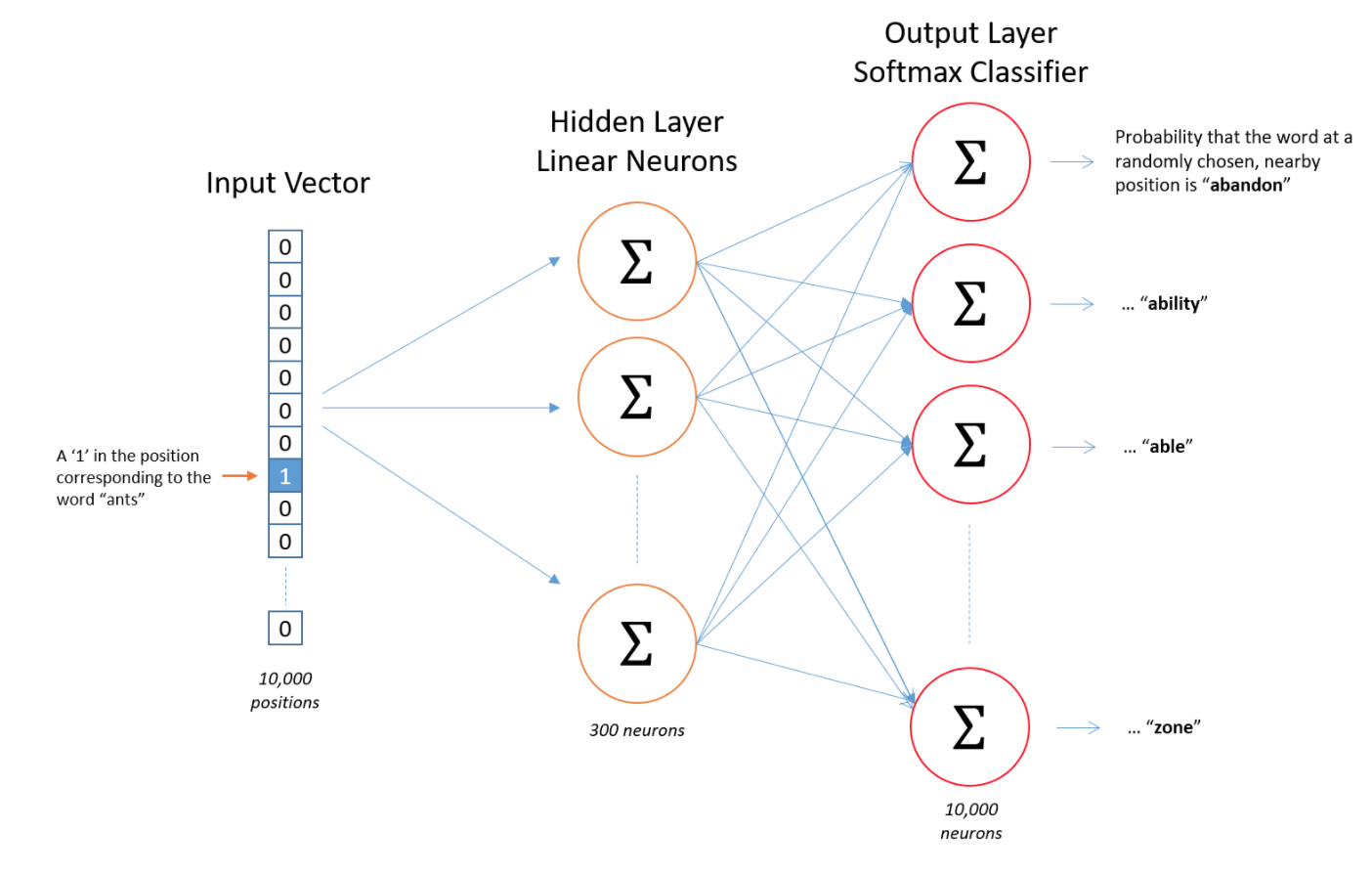
3.建立简单的神经网络
建立神经网络的真正意义在于要学到当前词是通过何种向量映射到其它词的。最后这个向量才是能够作为文本学习的特征向量。 Word2Vec本身不具有多大的学习作用,但它产生的词映射向量在当前的技术看来是作为机器学习语言的前提。如下图,我们所需要的就是中间的神经元模型:
4 . 生成最终 Vect
训练 model 特征提取,每个 one-hot 对应一个300d向量如下图

生成最终 look up word table
Word2Vec 特点
1.利用上下文 (context) 进行学习两个词上下文类似,生成的vector 会接近
2. 具有类比特性king-queen+female =male
3. 字符 -->数据,方便机器学习处理
本次笔记只是简单的介绍一下Word2Vec的工作过程,我们还可以通过其它的优秀博客来深度理解Word2Vec。
https://blog.csdn.net/mytestmy/article/details/26969149
还可以从这篇http://techblog.youdao.com/?p=915下载以下总结,讲的挺详细的。