spring data jpa
JPA(Java Persistence API)是Sun官方提出的Java持久化规范。它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据。他的出现主要是为了简化现有的持久化开发工作和整合ORM技术,结束现在Hibernate,TopLink,JDO等ORM框架各自为营的局面。值得注意的是,JPA是在充分吸收了现有Hibernate,TopLink,JDO等ORM框架的基础上发展而来的,具有易于使用,伸缩性强等优点。从目前的开发社区的反应上看,JPA受到了极大的支持和赞扬,其中就包括了Spring与EJB3.0的开发团队。
注意:JPA是一套规范,不是一套产品,那么像Hibernate,TopLink,JDO他们是一套产品,如果说这些产品实现了这个JPA规范,那么我们就可以叫他们为JPA的实现产品。
spring data jpa
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
spring data jpa让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现
关于spring data jpa查询
基本查询
基本查询也分为两种,一种是spring data默认已经实现,一种是根据查询的方法来自动解析成SQL。
预先生成方法
spring data jpa 默认预先生成了一些基本的CURD的方法,例如:增、删、改等等
1 继承JpaRepository
public interface UserRepository extends JpaRepository<User, Long> { }
2 使用默认方法
@Test public void testBaseQuery() throws Exception { User user=new User(); userRepository.findAll(); userRepository.findOne(1l); userRepository.save(user); userRepository.delete(user); userRepository.count(); userRepository.exists(1l); // ... }
就不解释了根据方法名就看出意思来
自定义简单查询
自定义的简单查询就是根据方法名来自动生成SQL,主要的语法是findXXBy,readAXXBy,queryXXBy,countXXBy, getXXBy后面跟属性名称:
User findByUserName(String userName);
也使用一些加一些关键字And、 Or
User findByUserNameOrEmail(String username, String email);
修改、删除、统计也是类似语法
Long deleteById(Long id);
Long countByUserName(String userName);
基本上SQL体系中的关键词都可以使用,例如:LIKE、 IgnoreCase、 OrderBy。
List<User> findByEmailLike(String email);
User findByUserNameIgnoreCase(String userName);
List<User> findByUserNameOrderByEmailDesc(String email);
具体的关键字,使用方法和生产成SQL如下表所示
|
Keyword |
Sample |
JPQL snippet |
|
And |
findByLastnameAndFirstname |
… where x.lastname = ?1 and x.firstname = ?2 |
|
Or |
findByLastnameOrFirstname |
… where x.lastname = ?1 or x.firstname = ?2 |
|
Is,Equals |
findByFirstnameIs,findByFirstnameEquals |
… where x.firstname = ?1 |
|
Between |
findByStartDateBetween |
… where x.startDate between ?1 and ?2 |
|
LessThan |
findByAgeLessThan |
… where x.age < ?1 |
|
LessThanEqual |
findByAgeLessThanEqual |
… where x.age ⇐ ?1 |
|
GreaterThan |
findByAgeGreaterThan |
… where x.age > ?1 |
|
GreaterThanEqual |
findByAgeGreaterThanEqual |
… where x.age >= ?1 |
|
After |
findByStartDateAfter |
… where x.startDate > ?1 |
|
Before |
findByStartDateBefore |
… where x.startDate < ?1 |
|
IsNull |
findByAgeIsNull |
… where x.age is null |
|
IsNotNull,NotNull |
findByAge(Is)NotNull |
… where x.age not null |
|
Like |
findByFirstnameLike |
… where x.firstname like ?1 |
|
NotLike |
findByFirstnameNotLike |
… where x.firstname not like ?1 |
|
StartingWith |
findByFirstnameStartingWith |
… where x.firstname like ?1 (parameter bound with appended %) |
|
EndingWith |
findByFirstnameEndingWith |
… where x.firstname like ?1 (parameter bound with prepended %) |
|
Containing |
findByFirstnameContaining |
… where x.firstname like ?1 (parameter bound wrapped in %) |
|
OrderBy |
findByAgeOrderByLastnameDesc |
… where x.age = ?1 order by x.lastname desc |
|
Not |
findByLastnameNot |
… where x.lastname <> ?1 |
|
In |
findByAgeIn(Collection ages) |
… where x.age in ?1 |
|
NotIn |
findByAgeNotIn(Collectionage) |
… where x.age not in ?1 |
|
TRUE |
findByActiveTrue() |
… where x.active = true |
|
FALSE |
findByActiveFalse() |
… where x.active = false |
|
IgnoreCase |
findByFirstnameIgnoreCase |
… where UPPER(x.firstame) = UPPER(?1) |
解析方法名--规则说明
1、规则描述
按照Spring data 定义的规则,查询方法以find|read|get开头(比如 find、findBy、read、readBy、get、getBy),涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
如果方法的最后一个参数是 Sort 或者 Pageable 类型,也会提取相关的信息,以便按规则进行排序或者分页查询。
2、举例说明
比如 findByUserAddressZip()。框架在解析该方法时,首先剔除 findBy,然后对剩下的属性进行解析,详细规则如下(此处假设该方法针对的域对象为 AccountInfo 类型):
先判断 userAddressZip (根据 POJO 规范,首字母变为小写,下同)是否为 AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步;
从右往左截取第一个大写字母开头的字符串(此处为 Zip),然后检查剩下的字符串是否为 AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复第二步,继续从右往左截取;最后假设 user 为 AccountInfo 的一个属性;
接着处理剩下部分( AddressZip ),先判断 user 所对应的类型是否有 addressZip 属性,如果有,则表示该方法最终是根据 "AccountInfo.user.addressZip" 的取值进行查询;否则继续按照步骤 2 的规则从右往左截取,最终表示根据 "AccountInfo.user.address.zip" 的值进行查询。
可能会存在一种特殊情况,比如 AccountInfo 包含一个 user 的属性,也有一个 userAddress 属性,此时会存在混淆。读者可以明确在属性之间加上 "_" 以显式表达意图,比如 "findByUser_AddressZip()" 或者 "findByUserAddress_Zip()"。(强烈建议:无论是否存在混淆,都要在不同类层级之间加上"_" ,增加代码可读性)
分页查询
分页查询在实际使用中非常普遍了,spring data jpa已经帮我们实现了分页的功能,在查询的方法中,需要传入参数Pageable
,当查询中有多个参数的时候Pageable建议做为最后一个参数传入
Page<User> findALL(Pageable pageable);
Page<User> findByUserName(String userName,Pageable pageable);
Pageable 是spring封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则
@Test public void testPageQuery() throws Exception { int page=1,size=10; Sort sort = new Sort(Direction.DESC, "id"); Pageable pageable = new PageRequest(page, size, sort); userRepository.findALL(pageable); userRepository.findByUserName("testName", pageable); }
自定义SQL查询
其实Spring data 觉大部分的SQL都可以根据方法名定义的方式来实现,但是由于某些原因我们想使用自定义的SQL来查询,spring data也是完美支持的;在SQL的查询方法上面使用@Query注解,如涉及到删除和修改在需要加上@Modifying.也可以根据需要添加 @Transactional 对事物的支持,查询超时的设置等
@Modifying @Query("update User u set u.userName = ?1 where c.id = ?2") int modifyByIdAndUserId(String userName, Long id); @Transactional @Modifying @Query("delete from User where id = ?1") void deleteByUserId(Long id); @Transactional(timeout = 10) @Query("select u from User u where u.emailAddress = ?1") User findByEmailAddress(String emailAddress);
多表查询
多表查询在spring data jpa中有两种实现方式,第一种是利用hibernate的级联查询来实现,第二种是创建一个结果集的接口来接收连表查询后的结果,这里主要第二种方式。
首先需要定义一个结果集的接口类。
public interface HotelSummary { City getCity(); String getName(); Double getAverageRating(); default Integer getAverageRatingRounded() { return getAverageRating() == null ? null : (int) Math.round(getAverageRating()); } }
查询的方法返回类型设置为新创建的接口
@Query("select h.city as city, h.name as name, avg(r.rating) as averageRating "
- "from Hotel h left outer join h.reviews r where h.city = ?1 group by h")
Page<HotelSummary> findByCity(City city, Pageable pageable);
@Query("select h.name as name, avg(r.rating) as averageRating "
- "from Hotel h left outer join h.reviews r group by h")
Page<HotelSummary> findByCity(Pageable pageable);
使用
Page<HotelSummary> hotels = this.hotelRepository.findByCity(new PageRequest(0, 10, Direction.ASC, "name")); for(HotelSummary summay:hotels){ System.out.println("Name" +summay.getName()); }
在运行中Spring会给接口(HotelSummary)自动生产一个代理类来接收返回的结果,代码汇总使用getXX的形式来获取

使用流程
创建工程并添加相关依赖
在Spring Boot中使用JPA,我们在创建工程的时候需要选择JPA依赖,如下:
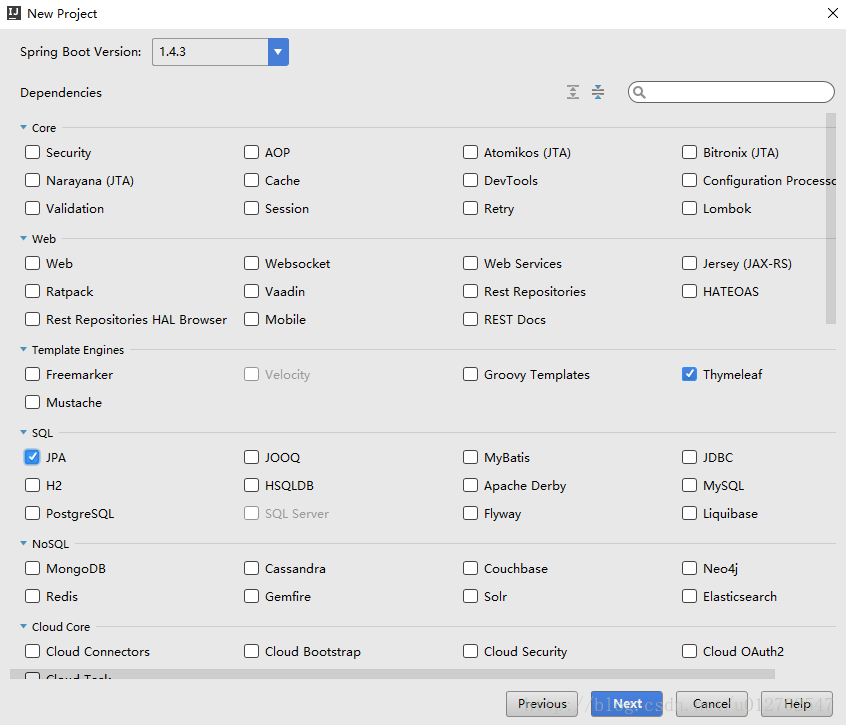
这里写图片描述
其他的步骤和我们创建一个普通的Spring Boot项目是一样的,如果小伙伴不了解如何创建一个Spring Boot项目可以参考这篇文章初识Spring Boot框架。
项目创建成功之后,我这里是使用MySql做演示,因此还需要添加MySql驱动,在pom.xml文件中添加如下依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.40</version>
</dependency>
配置基本属性
接下来需要我们在application.properties中配置数据源和jpa的基本的相关属性,如下:
spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/jpatest spring.datasource.username=root spring.datasource.password=123456 spring.jpa.hibernate.ddl-auto=update spring.jpa.show-sql=true spring.jackson.serialization.indent_output=true
关于这里的配置我说如下几点:
1.第一行表示驱动的名称,这个和具体的数据库驱动有关,视情况而定,我这里使用了MySql数据库,所以驱动名为com.mysql.jdbc.Driver
2.第二行表示数据库连接地址,当然也是视情况而定
3.第三四行表示数据库连接的用户名和密码
4.第五行则配置了实体类维护数据库表结构的具体行为,update表示当实体类的属性发生变化时,表结构跟着更新,这里我们也可以取值create,这个create表示启动的时候删除上一次生成的表,并根据实体类重新生成表,这个时候之前表中的数据就会被清空;还可以取值create-drop,这个表示启动时根据实体类生成表,但是当sessionFactory关闭的时候表会被删除;validate表示启动时验证实体类和数据表是否一致;none表示啥都不做。
5.第六行表示hibernate在操作的时候在控制台打印真实的sql语句
6.第七行表示格式化输出的json字符串
定义映射实体类
接下来,定义相应的实体类,在Project启动时,系统会根据实体类创建相应的数据表,我的实体类如下:
@Entity @NamedQuery(name = "Person.withNameAndAddressNamedQuery", query = "select p from Person p where p.name=?1 and p.address=?2") public class Person { @Id @GeneratedValue private Long id; private String name; private Integer age; private String address; public Person() { } public Person(Long id, String name, Integer age, String address) { this.id = id; this.name = name; this.age = age; this.address = address; } public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } }
首先在实体类上我们使用了@Entity注解,这个表示这是一个和数据库表映射的实体类,在属性id上我们添加了@Id注解,表示该字段是一个id,@GeneratedValue注解则表示该字段自增。@NamedQuery注解表示一个NamedQuery查询,这里一个名称代表一个查询语句,我们一会可以在控制器中直接调用@NamedQuery中的withNameAndAddressNamedQuery方法,该方法代表的查询语句是select p from Person p where p.name=?1 and p.address=?2。
定义数据访问接口
OK,做好上面几个步骤之后,接下来我们就可以定义数据访问接口了,我们的数据访问接口需要继承JpaRepository类,我在数据访问接口中一共定义了四个方法,如下:
public interface PersonRepository extends JpaRepository<Person, Long> { List<Person> findByAddress(String name); Person findByNameAndAddress(String name, String address); @Query("select p from Person p where p.name=:name and p.address=:address") Person withNameAndAddressQuery(@Param("name") String name, @Param("address") String address); Person withNameAndAddressNamedQuery(String name, String address); }
关于这个数据访问接口,我说如下几点:
1.当我们继承JpaRepository接口后,我们就自动具备了如下数据访问方法:
List<T> findAll(); List<T> findAll(Sort var1); List<T> findAll(Iterable<ID> var1); <S extends T> List<S> save(Iterable<S> var1); void flush(); <S extends T> S saveAndFlush(S var1); void deleteInBatch(Iterable<T> var1); void deleteAllInBatch(); T getOne(ID var1); <S extends T> List<S> findAll(Example<S> var1); <S extends T> List<S> findAll(Example<S> var1, Sort var2);
2.我们可以在接口中定义查询方法,可以按照属性名来查询,但是方法的命名方式是固定的,比如第一个方法和第二个方法,第一个方法表示根据一个属性查询,第二个方法表示根据多个属性查询,findBy、And等可以算作是这里的查询关键字了,如果写作其他名称则系统不能识别,类似的关键字还有Like、Or、Is、Equals、Between等,而这里的findBy关键字又可以被find、read、readBy、query、queryBy、get、getBy等来代替。
3.在查询的过程中我们也可以限制查询结果,这里使用的关键字是top、first等,比如查询前10条数据我们可以写作:
List<Person> findFirst10ByName(String name);
4.使用NamedQuery来查询,就是我们直接在实体类上使用@NamedQuery注解来定义查询方法和方法名,一个名称对应一个查询语句,具体可以参考我们上文的实体类
5.我们也可以向第三个方法那样添加@Query注解,当我调用这个方法的时候使用这个注解中的sql语句进行查询,方法的参数则是注解中的占位符的值。
编写测试Controller
数据访问接口都有了,接下来就是一个Controller了,我们写一个简单的Controller,用来测试一下上文中的数据访问接口是否正确,如下:
@RestController public class DataController { @Autowired PersonRepository personRepository; @RequestMapping("/save") public Person save(String name,String address,Integer age) { Person person = personRepository.save(new Person(null, name, age, address)); return person; } @RequestMapping("/q1") public List<Person> q1(String address) { List<Person> people = personRepository.findByAddress(address); return people; } @RequestMapping("/q2") public Person q2(String name, String address) { Person people = personRepository.findByNameAndAddress(name, address); return people; } @RequestMapping("/q3") public Person q3(String name, String address) { Person person = personRepository.withNameAndAddressQuery(name, address); return person; } @RequestMapping("/q4") public Person q4(String name, String address) { Person person = personRepository.withNameAndAddressNamedQuery(name, address); return person; } @RequestMapping("/sort") public List<Person> sort() { List<Person> people = personRepository.findAll(new Sort(Sort.Direction.ASC, "age")); return people; } @RequestMapping("/page") public Page<Person> page(int page,int size){ Page<Person> all = personRepository.findAll(new PageRequest(page, size)); return all; } @RequestMapping("/all") public List<Person> all(){ return personRepository.findAll(); } }
这里的代码都很简单,我就不再一一进行解释了,值得说的是第36行代码表示根据age对查询结果进行排序然后显示出来,第40行的方法表示一个分页查询,第一个参数表示页数,从0开始计,第二个参数表示每页的数据量。最后在浏览器中分别测试这几个接口就可以了。