基础篇3
1、集合
2、文件的操作
3、字符编码转换
4、函数
5、局部变量与全局变量
6、递归
7、高阶函数
一、集合
集合是一个无序的、不重复元素集合,其中的元素是不可变的。
基本的功能:
去重:列表和元组中有相同的元素可以转换为集合去重
关系测试:集合的交集、并集、差集等相关关系的测试
集合的创建及一些基本操作:
集合的创建


1 >>> s = set('school') #创建集合 2 >>> print(s) 3 {'l', 'o', 'c', 'h', 's'} 4 >>> s2 = {'s', 'c', 'h', 'o', 'o', 'l'} #等同于 set({'s', 'c', 'h', 'o', 'o', 'l'}) 5 >>> print(s2) 6 {'l', 'o', 'c', 'h', 's'} 7 >>> s3 = set(['s', 'c', 'h', 'o', 'o', 'l']) 8 >>> print(s3) 9 {'l', 'o', 'c', 'h', 's'} 10 #上面都是使用集合的工厂方法se()来创建集合
在上面注意了创建一个空的集合时只能使用s=set()创建,不能使用s={}创建。
查看集合中的成员及判断是否为集合中成员
1 >>> s = set(['s', 'c', 'h', 'o', 'o', 'l']) 2 >>> 's' in s #判断元素‘s’ 是集合s的成员,是返回True、否则返回False 3 True 4 >>> 's' not in s #判断元素‘s’ 不是集合s的成员,不是返回True,否则反之 5 False 6 >>> for i in s: 7 ... print(i) 8 ... 9 l 10 o 11 c 12 h 13 s 14 #上面使用遍历的方法查看集合中的成员
集合的增删操作
1 >>> s = set(['s', 'c', 'h', 'o', 'o', 'l']) 2 >>> s.add('l') 3 >>> print(s) 4 {'s', 'h', 'o', 'l', 'c'} 5 >>> s.add('w') 6 >>> print(s) 7 {'l', 'w', 'c', 's', 'h', 'o'} 8 #当添加的元素集合中有的时候,由于集合的去重特性所以集合没有变化 9 #只有添加的元素在集合中不存在时,集合才会发生变化 10 >>> s = set(['s', 'c', 'h', 'o', 'o', 'l']) 11 >>> s.remove('w') #删除的集合不存在会报错 12 Traceback (most recent call last): 13 File "<input>", line 1, in <module> 14 KeyError: 'w' 15 >>> s.remove('l') 16 >>> print(s) 17 {'s', 'h', 'o', 'c'} 18 >>> s.pop() #随机在集合中删除元素 19 's' 20 >>> s.discard('w') #删除的元素不在集合中,不会报错一般使用该方法 21 #删除元素 22 >>> print(s) 23 {'h', 'o', 'c'} 24 >>> s.discard('c') 25 >>> print(s) 26 {'h', 'o'}
集合的并集、交集、合集、对称差集及其他操作
1 >>> s = set(['q', 2, 'w', 888, 666]) 2 >>> s2 = set(['e', 1, 'r', 888, 999 ]) 3 >>> s.union(s2) 4 {1, 2, 999, 'w', 'r', 888, 666, 'e', 'q'} 5 >>> s | s2 6 {'q', 2, 'w', 1, 999, 'r', 'e', 888, 666} 7 #取并集,返回的是集合s和s2中所有的去掉重复的元素的集合 8 #s和s2本身没变化 9 >>> s.intersection(s2) 10 {888} 11 >>> s & s2 12 {888} 13 #取交集,返回的是集合s和s2中相同元素的集合 14 #s和s2本身没变化 15 >>> s.intersection_update(s2) 16 >>> print(s) 17 {888} 18 >>> print(s2) 19 {888, 1, 'e', 'r', 999} 20 #更新集合s,保留2个集合相同的元素 21 22 23 24 25 >>> s = set(['q', 2, 'w', 888, 666]) 26 >>> s2 = set(['e', 1, 'r', 888, 999 ]) 27 >>> s.difference(s2) 28 {'w', 2, 'q', 666} 29 >>> s - s2 30 {'q', 2, 'w', 666} 31 #取差集,返回的是集合s中有的元素,s2中没有的元素的集合 32 #s和s2本身没变化 33 >>> s.difference_update(s2) 34 >>> print(s) 35 {'w', 2, 'q', 666} 36 >>> print(s2) 37 {888, 1, 'e', 'r', 999} 38 #更新集合s,在集合s中去掉2个集合相同的元素 39 40 41 >>> s = set(['q', 2, 'w', 888, 666]) 42 >>> s2 = set(['e', 1, 'r', 888, 999 ]) 43 >>> s.symmetric_difference(s2) 44 {1, 2, 999, 'w', 'r', 666, 'e', 'q'} 45 >>> s ^ s2 46 {1, 'q', 2, 'w', 999, 'r', 'e', 666} 47 #对称差集,返回的集合中的元素在s和s2中,但不同时在这2个集合中 48 #s和s2本身没变化 49 >>> s.symmetric_difference_update(s2) 50 >>> print(s) 51 {1, 2, 999, 'w', 'r', 666, 'e', 'q'} 52 >>> print(s2) 53 {888, 1, 'e', 'r', 999} 54 #这个就是更新集合s是里面的元素在s和s2中,但不同时在这2个集合中 55 #没有返回值,s集合发生变化,s2集合没有发生变化 56 57 58 59 >>> s = set([2, 3, 4, 99]) 60 >>> s2 = set([2, 3, 4]) 61 >>> s3 = set([888,999]) 62 >>> s.issuperset(s2) 63 True 64 #检查s是不是s2的父集,是返回True,否则返回Falsh 65 >>> s2.issubset(s) 66 True 67 #检查s2是不是s的子集,是返回True,否则返回Falsh 68 >>> s2.isdisjoint(s) 69 False 70 #检查集合s2和集合s有没有相交的没有则返回True,否则返回Falsh 71 >>> s.isdisjoint(s3) 72 True 73 #检查集合s和集合s有没有相交的没有则返回True,否则返回Falsh 74 #上面主要检测2个集合有没有一样的元素有则返回True,否则返回Falsh 75 76 >>>s = set(['q', 2, 'w', 888, 666]) 77 >>>s3 = s.copy() 78 >>> print(s3) 79 {'w', 2, 'q', 666} 80 >>> s3.add('d') 81 >>> print(s) 82 {'w', 2, 'q', 666} 83 >>> print(s3) 84 {'w', 2, 'q', 'd', 666} 85 #这个属于浅copy 86 >>> s.clear() 87 >>> s 88 set() 89 #清空集合,使之变为一个空集合
上面只介绍了交集、并集、合集和对称集介绍了使用运算符的使用方法。其他的也可以使用运算符的方法,但是个人觉的记得比较繁琐,只记住这几个比较好点。要是想知道其他的使用符号怎么表示可以去自己在网上查查。
二、文件的操作
文件的打开有两种方式:
1、f = open(file_name,[mode])
2、with open(file_name,[mode]) as f:
第二种方式相对于第一种方式比较好点。第二种方式形成上下文在执行完这段代码时会自动关闭文件,不像第一种需要主动用f.close()来关闭文件。同时再打开不存在的文件时报错,使用第一种方法在使用try...finally解决报错问题代码变得复杂,而是用第二种方法是会使代码变的更简洁。
打开文件的方式
这个方式指的是打开文件的模式也就是上面的mode
r : 只读模式打开文件,我们只能进行读操作不能进行其他的操作。如果文件不存在会报错
w: 以写的方式打开文件,文件若存在,首先要清空文件,然后重新创建。若文件不错在则创建该文件
a: 以追加的方式打开,文件不支持读的操作,只能在文件末尾追加。文件不存在就创建该文件。
r+: 以读写的方式打开该文件,该方式使用的时候如果使用open()方式后没有进行任何的读的操作那么我们写入信息的时候,会从文件的顶部写入,写入一个字节就会覆盖一个字节。如果进行了读的操作的时候,那么我们写入信息的时候,写入的信息就会追加到文件的末尾。
下面这个代码表示再打开文件和关闭文件的这个过程中,对文件不进行任何读操作时,向文件写入字符串时写入的方式。
下面的操作是对文件打开了2次第一次是为了看里面的内容
with open('zhetian.txt', 'r+') as f:
print(f.read())
print('----------------')
with open('zhetian.txt', 'r+') as f:
f.write('ok')
f.seek(0)
print(f.read())
上面的运行结果如下,可以看出在不进行读的操作是,向里面写一个字符就覆盖源文件的一个字符。
hello world hello world ---------------- okllo world hello world
下面验证了在一次打开和关闭的情况下我们先对文件进行了读操作,我们向文件中写入相应的字符的操作。
with open('zhetian.txt', 'r+') as f:
print(f.read())
f.write('ok')
f.seek(0)
print(f.read())
我们从结果可以看见我们写入的字符会默认添加在文件的末端
hello world hello world hello world hello worldok
只要我们对文件进行了读这个操作那么,不管读到那个位置我们添加字符的位置都会在文件的末端,与光标所在的位置没什么影响。
当我们写完时,读的时候会从写完的位置开始读(注:当我们向文件中写入字符时我们的光标就会在写入字符的位置)
光标:当我们打开文件的时候我们的光标一般会默认会在文件的顶部,当我们进行读的操作时,我们读到那里我们的光标一般会移到某个位置,同样我们写到那个位置我们的光标也会在相应的位置。如果是追加模式的话光标在文件的末端。
w+: 以写读的方式打开文件,如果文件不存在,则创建。若存在,则清空里面内容。
a+: 该追加方式可以读,里面的光标位于文件的末端,所以要想读取里面的内容则使用seek()方法移动光标。
同时打开文件也有rb、wb、ab、rb+、wb+、ab+,这个与上面的一样的方式一样不过只是一二进制的方式打开文件。
文件的一些方法和属性
1 file.close() 2 #关闭文件,这个方法只在 f = open()的方式下才使用, 3 #而with open() as f:该方式自带关闭文件 4 5 file.flush() 6 #刷新文件内部缓冲,直接把内部缓冲区的数据立即写入文件 7 #而不是别动等待缓冲区写入 8 9 file.seek(offset,whence) 10 #移动文件中光标的位置 11 #offcset指的是光标移动多少个字节,记住这个是字节不是字符,如中文utf-8表示的是3个字节 12 #whence可以有多个选项,0:从文件头 。1:从当前位置 。2:从文件尾部不过默认的为0 13 #file.seek(0)这个0代表的是whence所以offset默认为0 14 15 file.fileno() 16 #方法返回一个整型的文件描述符(file descriptor FD 整型) 17 #可用于底层操作系统的 I/O 操作。 18 19 file.read(size) 20 #在文件中读取指定字符数,如果没有或者是负数默认为读取全部 21 #读取完成后光标在你读取的位置 22 23 file.readline(size) 24 #读取整行,包过' '字符。光标移动.取出来的是字符串, 25 #size不为零或者负数,就取该行指定字节 26 #光标位于行尾 27 28 file.readlines(size) 29 #读取所有行并返回列表。其中包过' '字符 30 31 file.isatty() 32 #如果文件连接到一个终端设备返回 True,否则返回 False。 33 34 file.tell() 35 #报告当前文件中光标的位置 36 37 file.name 38 #这是属性不是方法 39 #显示当前文件的文件名 40 41 file.truncate(size) 42 #用于从文件的首行首字符开始截断, 43 #size表示的是字节,也就是说截取size字节。后面的删掉这个包过换行符 44 45 file.write(str) 46 #将字符串写入文件,没有返回值 47 48 file.writelines(sequence) 49 #向文件中写入一序列的字符串。 50 #这一序列字符串可以是由迭代对象产生的,如一个字符串列表。 51 #换行需要制定换行符 。 52 53 file.closed 54 #这是属性用来判断文件是否关闭 55 56 file.mode 57 #这是属性,文件打开的模式
文件的内容查找和替换
1 data = '' 2 3 with open('test.txt', 'r') as f: 4 for line in f.readlines(): 5 if(line.find('Server') == 0): 6 line = 'Server=%s' % ('192.168.1.1') + ' ' 7 8 data += line 9 10 with open('test.txt', 'w') as f: 11 f.writelines(data) 12 #这是修改某一行的信息 13 #上面的方法是查找文件中的某行在修改改行的数据不过如果大概的文件里#面的内存容量过大可能导致卡顿现象,所以建议在小容量的文件使用。 14 #如果文件太大,这种方法使用内存使用量会很多浪得内存,使得运行很卡 15 16 with open('zhetian.txt', 'r') as f: 17 with open('zhetian1.txt', 'w') as f1: 18 for line in f: 19 if(line.find('Server') == 0): 20 line = 'Server=%s' % ('192.168.1.1') + ' ' 21 f1.write(line) 22 else: 23 f1.write(line) 24 with open('zhetian.txt', 'w') as f: 25 with open('zhetian1.txt', 'r') as f1: 26 for line1 in f1: 27 f.write(line1) 28 #这个方法是一行一行的往内存中读一行然后把这行写入到新的文件中, 29 #这样内存中始终只有一行,然后把新的文件一行一行写入原来文件中 30 #因为python3不支持原地修改然后存储所以要想高效就是用上面的方法 31 32 with open('test.txt','r') as fopen: 33 for line in fopen: 34 if re.search('world',line): 35 line=re.sub('world','hello',line) 36 w_str+=line 37 else: 38 w_str+=line 39 print(w_str) 40 with open('test.txt','w') as wopen: 41 wopen.write(w_str) 42 #这个是查找文件中的某个单词进行替换。 43 #这个同样如果文件过大也会出现上面情况 44 45 import re 46 with open('zhetian.txt','r') as fopen: 47 with open('zhetian1.txt', 'w') as f1: 48 for line in fopen: 49 if re.search('world',line): 50 line=re.sub('world','hello',line) 51 f1.write(line) 52 else: 53 f1.write(line) 54 with open('zhetian.txt','w') as wopen: 55 with open('zhetian1.txt', 'r') as f1: 56 for line1 in f1: 57 wopen.write(line1) 58 #这种方法和上面第二种方法一样这样会写一行到内存中然后就删除, 59 #内存中始终保持只有一行,节约内存空间这样在打开大的文件可以使用 60 #上面使用了正则表达式 61 #上面所有的文件使用的是相对位置里面可以放绝对位置,建议写绝对位置
从上面的列子我们可以知道当我们的文件太多的时候使用readlines()方法这样会占用大量内存。
所以在查找的时候我们可以使用for i in f:这种方式来读取里面的内容。
注意:我们上面可以使用os模块把旧文件删除,新文件重新命名如:
os.remove('old_file')
os.rename('new_file','old_file')
如果打开多个文件我们可以用以下方式:
with open('test1.txt', 'w') as f1 ,
open('test2.txt', 'w') as f2:
pass
with open('test1.txt', 'w') as f1:
with open('test2.txt', 'w') as f2:
pass
三、字符编码的转换
关于字符编码的转换的问题我个人推荐到网上看看各位大神写的见解,在这里我只给大家提供一个字符编码转换的图,这个图也是从大神们那里copy过来的
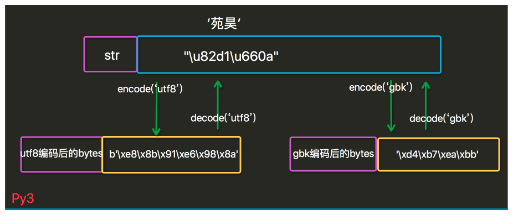
通过别大神们的见解和牢记住这幅图个人感觉关于编码的应该没问题了,这个还是要看自己多多得琢磨琢磨。
四、函数
函数是组织好的、可重复使用的、用来实现单一、或相关联功能的代码段。
函数能够提高应用的模块性,和代码的重复利用率。我们已知Python提供了许多内建函数,比如print()。
我们同样也开始自己创建函数,这种函数叫用户自定义函数。
1、函数的定义
函数代码块以def关键词开头,后接函数标识符和圆括号()。
任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
函数的第一行语句可以选择性的使用文档字符串用来存放函数说明。
函数的内容以冒号起始,并且缩进。
renturn[表达式]结束函数,选择性的返回一个值给调用。不带表达式的renturn相当于返回None。
2、函数的一些特性
1.减少代码的重复性
2.使程序变的可扩展
3.使程序变的易维护
函数的基本格式为
def func_name(arg_list):
"""文档字符串"""
函数体
return [expression]
注:上面的arg_list、文档字符串和return是可选的。
func_name:函数名
return:返回值
下面是一个简单的函数:
def func():
print('Hello function')
func() #表示函数的调用
#上面运行的输出的结果:
Hello function
函数中带有参数
关键字参数和位置参数
def func(x,y):
print('Your height is %s cm'% x)
print('Your weight is %s kg'% y)
func(170,55) #调用的时候,实参和上面的形参是一一对应的。这种情形下的实参为位置参数
print("--------------------")
func(x=175,y=55) # func(y=55, x=175)和前面的等同,主要看前面的关键字和形参对应就好。
#这种的的参数我们叫做关键字参数,关键字参数不需要注意位置。
#当关键字参数和位置参数一起用的时候,一定要记住位置参数一定要在前面。
#同时位置参数对应的形参关键字不能够再次对应,要不程序回报错。
#关键字参数和位置参数必须要和上面的形参数目一样,不能少也不能多
#func(175,y=55)这样可以、func(55,x=175)这样会报错说同一个参数只能赋值一次
#func(x=175,55)这样写也会报错
#记住传参的时候,不管使用位置参数还是关键字参数,都要遵守上面的要求。
#上面运行屏幕输出的结果
Your height is 170 cm
Your weight is 55 kg
--------------------
Your height is 175 cm
Your weight is 55 kg
默认参数
def func(name, age, salary=3000):
print('Your name is %s '% name)
print('Your age is %s '% age)
print('Your salary is %s' % salary)
func(name='xiaoming',age='man')
print('---------------------')
func(name='xiaoming',age='man',salary=5000)
#上面运行的结果
Your name is xiaoming
Your age is man
Your salary is 3000
---------------------
Your name is xiaoming
Your age is man
Your salary is 5000
#上面可以看出我们的有默认参数时,在调用函数时,如果没有传递参数,则使用默认参数。
#如果默认参数传递了参数,就以传递的参数为准
#同时注意写函数是默认参数都放在右边要不就会报错,
#如果里面有不定长参数的时候,因为不定长参数可以在任何位置,
#所以有可能默认参数在不定长参数前面
不定长参数*args
def func(name,age,salary=3000,*args):
print('Your name is %s '% name)
print('Your age is %s '% age)
print('Your salary is {}'.format( salary))
print(args)
func('xiaoming','man',5000,'music',)
#运行的结果
Your name is xiaoming
Your age is man
Your salary is 5000
('music',)
#由于不定长参数*args传参的时候传的是位置参数,且位置参数必须要在关键字参数前面
#所以我们使用*args时,如果里面使用位置参数和关键字参数那么可以把*args放在前面
#如:
def func(*args,name,age,salary=3000):
print('Your name is %s '% name)
print('Your age is %s '% age)
print('Your salary is {}'.format( salary))
print(args)
func('music',name='xiaoming',age='man',salary=5000)
#如果把不定长参数*args放在后面的话,前面就不能使用关键字参数来传参
#同时*args传进去的参数会以元组的方式出现
不定长参数**kwargs
#**kwargs传参使用的是关键字参数,且传入参数会以字典(dict)的形式出现
def func(name,age,**kwargs):#**kwargs放在后面
print('Your name is %s '% name)
print('Your age is %s '% age)
print(kwargs)
func(name='xiaoming',age='man',salary=6000,address='beijing')
#上面运行的结果
Your name is xiaoming
Your age is man
{'address': 'beijing', 'salary': 6000}
#由于不定长参数**kwargs传参的时候使用的是关键字传参。
#所以不定长参数**kwargs所以一定要把它放在后面。
可更改与不可更改对象
传递不可变对象
def func(a):
a = 100
b = 50
func(b)
print(b) #结果是50
从上面的结果中可以看出当我们传递一个不可变的对象的时候,我们在函数内部修改该对象的时候到外面的时候该对想还是没有改变,上面的实列中我们可以看到先把b指向了内存中的50的位置,当我们传递给func()函数的时候是把50的位置传递给了函数中的a,然后a重新给它赋值,指向内存中100的位置,这样我们b指向内存中的位置实际上是没有改变的,
传递可变对象
def func(a):
a.append(5)
print('a',a)
b = [1,3,6]
func(b)
print('b',b)
#结果为
#a [1, 3, 6, 5]
#b [1, 3, 6, 5]
从上面的列子中我们可以看出当我们传入可变对象的时候,在函数里面修改该可变对象,我们外面的对象也会被改变。我们可以认为b指向内存地址中可变对象的位置把把它,调用到函数中时,a也指向该地址,当我们修改该里面的内容的时候,我们的内存地址的位置没有改面改变的只是里面的内容,所以b的内容也会被改变。因为a、b指向内存中的地址都是一样的。
不可变对象指的是字符串、元组、整数等、我们在传递他们的时候该变量名指向的内存地址没有改变,只是把它指向的内存地址给了函数里面,当函数的变量名指向内存中的地址发生改变的时候,外部的变量名没有受到影响。
可变对象包含了字典(dict)、列表(list)。在函数内部发生改变,外部也会发生变化
函数的返回值(return)
在函数中return[表达式]在函数里面表示退出该函数,向调用该函数的返回一个表达式。
当函数中没有return时,返回的是一个None。
当函数中return返回一个表达式时,返回的就是该表达式的值。
当函数中return返回多个表达式时,返回多个值时,并将多个值放在元组中。
在调用该函数的时候,在函数中return以下的代码将不会执行。
def func(a):
c = a + 20
return c
print('a',a)
b = 10
x=func(b)
print('x',x)#结果为 x 30
def func(a):
c = a + 20
return c,a
print('a',a)
b = 10
x=func(b)
print('x',x) #结果为 x (30, 10)
函数的调用,在调用函数的时候一定要记住,我们的调用一定要在该函数之后。只要我们调用的函数里面还有其他的函数,那么我们调用的时候也要把其它的函数写在这个调用的前面,要不程序会报错的。
匿名函数
使用lambda表达式来创建匿名函数。
lambda表达式的描述
lambda只是一个表达式,比函数def简单的多
lambda主体就是一个表达式,不像def有一个代码块,只能在lambda表达式中封装有限的逻辑语句。
lambda函数拥有自己的名字空间,且不能访问自有参数列表之外或全局名字空间里的参数
lambda函数虽然只有一行,但是却不同于C或C++的内联函数,后者目的是调用小函数时,
不占用栈内存从而增加运行速度。
lambda函数的格式
lambda[arg1[,arg2...[,argn]]]]:expression
lambda函数我们可以直接使用也可以把它赋值一个函数名在调用
lambda函数直接使用
print((lambda x:x**2)(4))#结果是16 把(4)中的4赋值给x,即x=4 #记住直接调用的时候,需要传参时一定要用括号把lambda函数括起来。
给lambda函数一个函数名
#向lambda函数里面传递一个参数
func = lambda x:x**2
print(func(4))#结果是16
#向lambda函数里面传递多个参数
func2 = lambda x,y,z=4:(x+y)*z
print(func2(x=2,y=2)) #结果是16
print(func2(x=2,y=2,z=5))#结果是20
#这里面传参的时候,也就是与def函数传参相似。
五、局部变量与全局变量
当我们在函数内声明变量的时候,它与我们函数外面具有相同名称的其他变量没有任何关系,
相对函数来说函数里面的的变量名为局部变量,这个变量只在这个函数里面起作用,
不管函数外有没有相同的变量名,而函数里面的变量(局部变量)作用域就是这个函数块,
只在这个函数里面起作用,对函数外面的不起作用。
x = 100 #这个x为全局变量
def func(a):
print('a is',a)
x = 10 #这个x就是局部变量
print('x is', x)
func(5)
print('x is ',x)
#运行的结果
x is 5
x is 10
x is 100
#当函数里面的变量名和函数外有相同的变量名时,在函数里面调用该变量的时候它会调用函数里面的变量。
#也就是说当我们在函数里面调用函数的时候,它会检查函数里面有没有该变量有的话就调用它,
#没有的话它就会调用函数外面的变量,函数里面的变量为局部变量。
#注意当函数里面和外面有相同的变量,如果我们在函数里面调用该变量的时候,
#调用的位置在函数里面声明该变量之前程序会报错说。
#局部变量只在这个函数模块起作用除了这个模块这个变量就没有效果了。
x = 100
def func():
print('x',x)
x=50
func()
#运行上面的时候,程序报错,告诉我们局部变量我们在赋值前引用导致的错误。
要想在函数里面我们赋值的变量为全局变量只需要在赋值的时候在前面声明一下就可以了
def func():
global x
x = 10
func()
print(x)# 结果为 10
#记住要想这个全局变量生效那么一定要调用该函数,否则这个变量将会没有效果。
六、递归
递归函数就是一个函数内部调用函数自身,这个函数就叫递归函数。
递归特性:
必须要有一个明确的结束条件
每次进入更深一层递归时,问题的规模相比上一次递归都应有所减少
递归效率不高,递归层次过多会导致栈溢出
递归函数不像while能够无限递归,在网上查了一下有的人说可以递归999次有的人说可以递归1000次。
这不是重点,重点是Python设置这种机制是用来防止无限递归造成Python溢出,这个最大递归次数我们可以自己调整的。
#使用递归函数计算l累加
def accum(n):
if n==1:
return 1
return n+accum(n-1)
print(accum(3))#结果是6
七、高阶函数
高阶函数:
变量可以指向函数。
函数的参数可以接收变量
一个函数可以接收另一个函数作为参数
def add(a,b,f):
return f(a)+f(b)
print(add(-4,25,abs))#结果是29
#上面就是把a的绝对值和b的绝对值相加,因为涉及到绝对值所以我们引入绝对值的函数abs
#这个就是符合高阶函数要求,所以它是高阶函数。
本人属于小白级别的上面写的如有错误欢迎指正和交流。