生成式对抗网络介绍
生成对抗网络(GAN)最初被提议用于在连续空间中生成样本,例如图像。
GAN 网络由两部分组成,生成器和判别器。 生成器接受噪声输入并输出图像。 鉴别器是一个分类器,它将图像分类为“真”(来自真实数据集)或“假”(由生成器生成)。 在训练 GAN 时,生成器和判别器是在做极小极大博弈,其中生成器尝试生成“真实”图像来欺骗判别器,判别器尝试将它们与真实图像区分开来。
随机采样
随机采样方法采用随机替换头尾实体的方式用于负采样,生成的负三元组明显是错误的,因此对训练的贡献很小。
- 基于 log-softmax 损失函数的模型通常在每次迭代中为一个正三元组采样数十或数百个负三元组,其中可能有一些有用的负数,因此传统负采样的缺陷对此类模型影响不大。
- 然而,对于负正比始终为 1:1 的 margin-loss 函数,均匀采样的低质量负样本会严重损害其性能。
KBGAN
背景介绍
针对随机采样的缺陷,论文提出了一个对抗学习框架(KBGAN)用于提升知识图谱嵌入模型的性能。
KBGAN使用两个模型,一个作为生成器,生成高质量的负样本;一个作为判别器,用正样本和生成器生成的负样本进行训练。
生成器选用基于概率的、log-loss的模型生成更高质量的负样本,判别器选用基于距离的、margin-loss的模型,生成最终的知识图谱嵌入。
margin-loss 函数,普遍用于基于翻译的模型,距离越小,为真的可能性越大,如 TRANSE 、TRANSH 、TRANSR 和 TRANSD 等。损失函数如下:
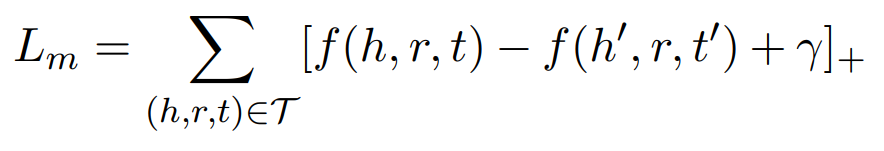
log-softmax 损失函数,普遍用于基于概率的模型,给出了当前三元组在候选三元组中最好的概率,如 DISTMULT 、 COMPLEX 等。损失函数如下:
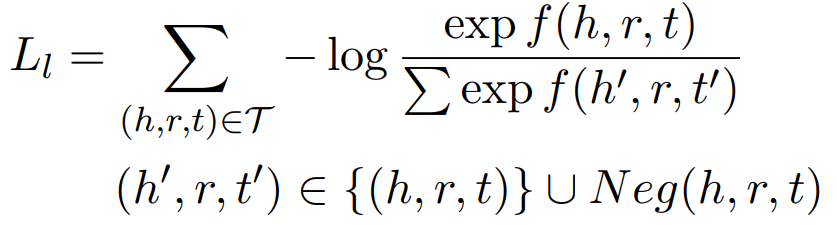
KBGAN独立于模型的具体形式,所以无论复杂性如何,所有模型都可以潜在地合并到KBGAN中。
模型框架
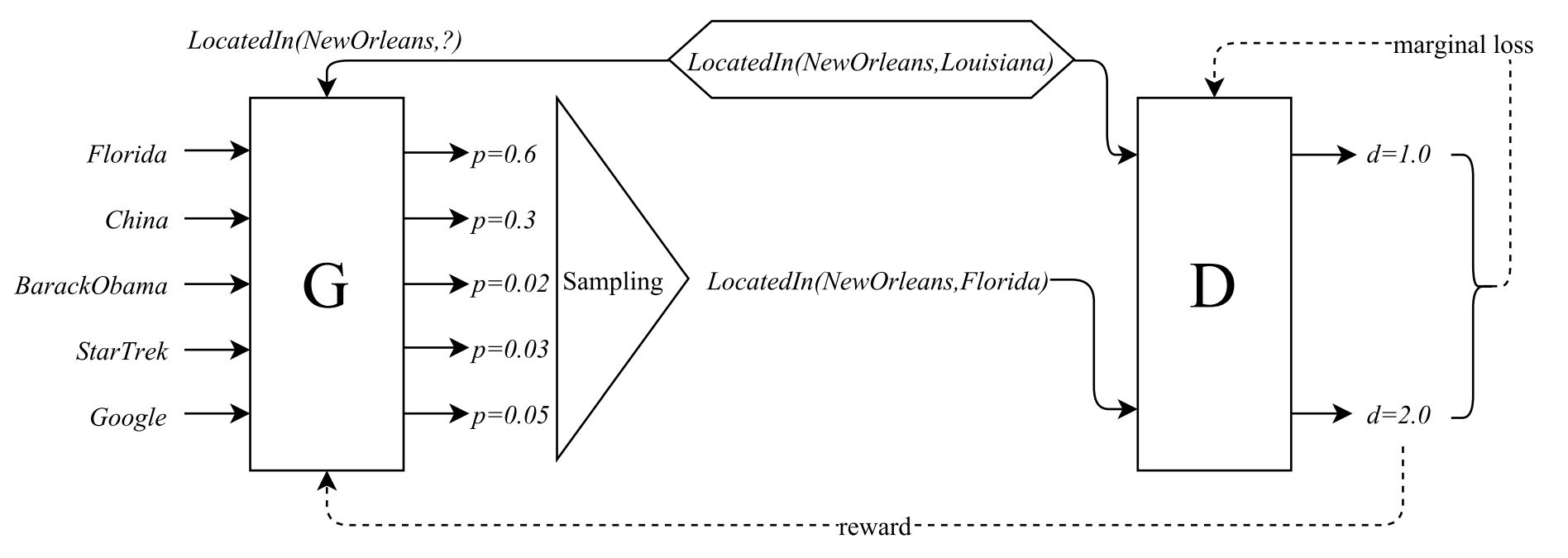 生成器 (G) 计算一组候选负三元组的概率分布,然后从分布中采样一个三元组作为输出。 判别器 (D) 接收生成的负三元组以及真实三元组,并计算它们的分数。 G 通过策略梯度最小化生成的负三元组的得分, D 通过梯度下降最小化正负三元组之间的 margin 损失。
生成器 (G) 计算一组候选负三元组的概率分布,然后从分布中采样一个三元组作为输出。 判别器 (D) 接收生成的负三元组以及真实三元组,并计算它们的分数。 G 通过策略梯度最小化生成的负三元组的得分, D 通过梯度下降最小化正负三元组之间的 margin 损失。
生成器的目标是最小化判别器为生成的三元组给出的距离,即
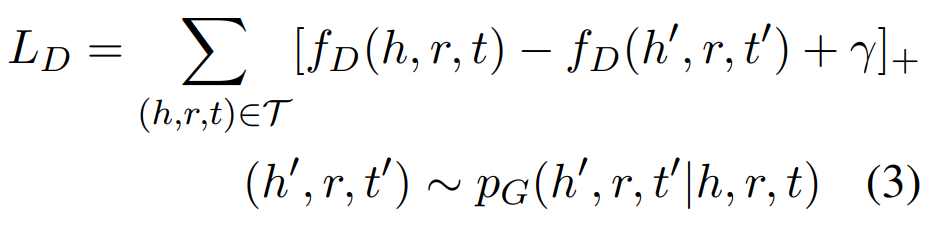
判别器的目标是最小化正三元组和生成的负三元组之间的margin损失,即
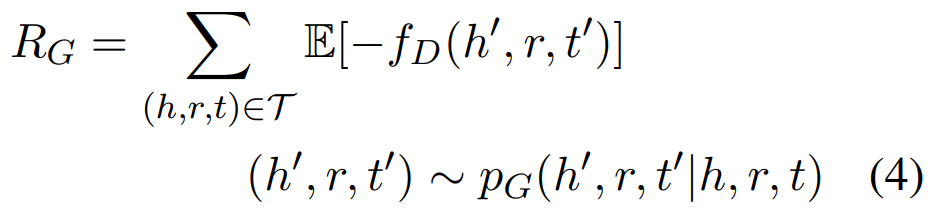
使用决策梯度法获得 RG 的梯度,即
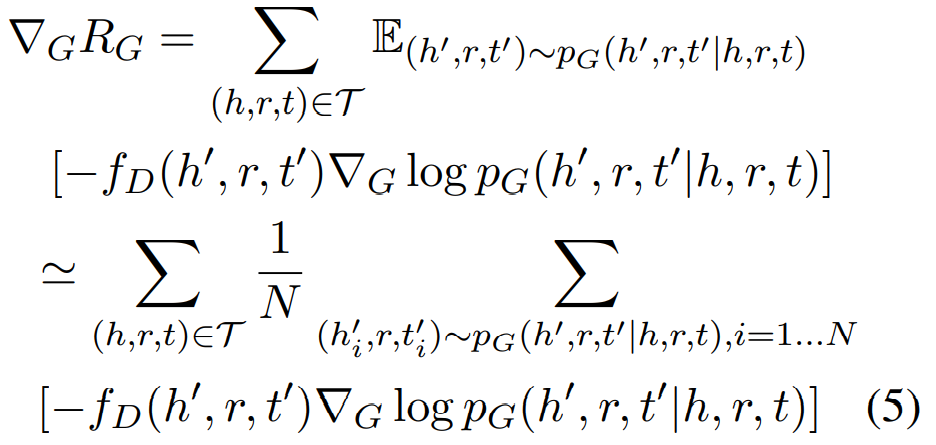
模型的伪代码如下

KBGAN与强化学习模型类比
生成器可以被视为一个代理,通过执行动作与环境交互,并通过最大化从环境返回的奖励以响应其动作来改进自身;判别器可以看作是环境;\(\left( h,r,t \right)\)是状态,决定角色可以采取什么动作;\(p_G\left( h',r,t'|h,r,t \right)\)是策略,决定actor如何选择动作;\(\left( h',r,t' \right)\)是动作;\(-f_D\left( h',r,t' \right)\)是奖励。与一般的RL模型不同的是,在 KBGAN 中,动作不会影响状态,并且在每个动作之后以另一个不相关的状态重新开始
为了减少强化算法的方差,通常会从奖励中减去基线,这是一个仅取决于状态的任意数字,不影响梯度的期望。在实践中,b 取最近生成的负三元组的奖励的平均值。
实验
数据集:FB15k-237、WN18、WN18RR
模型的实验结果如下
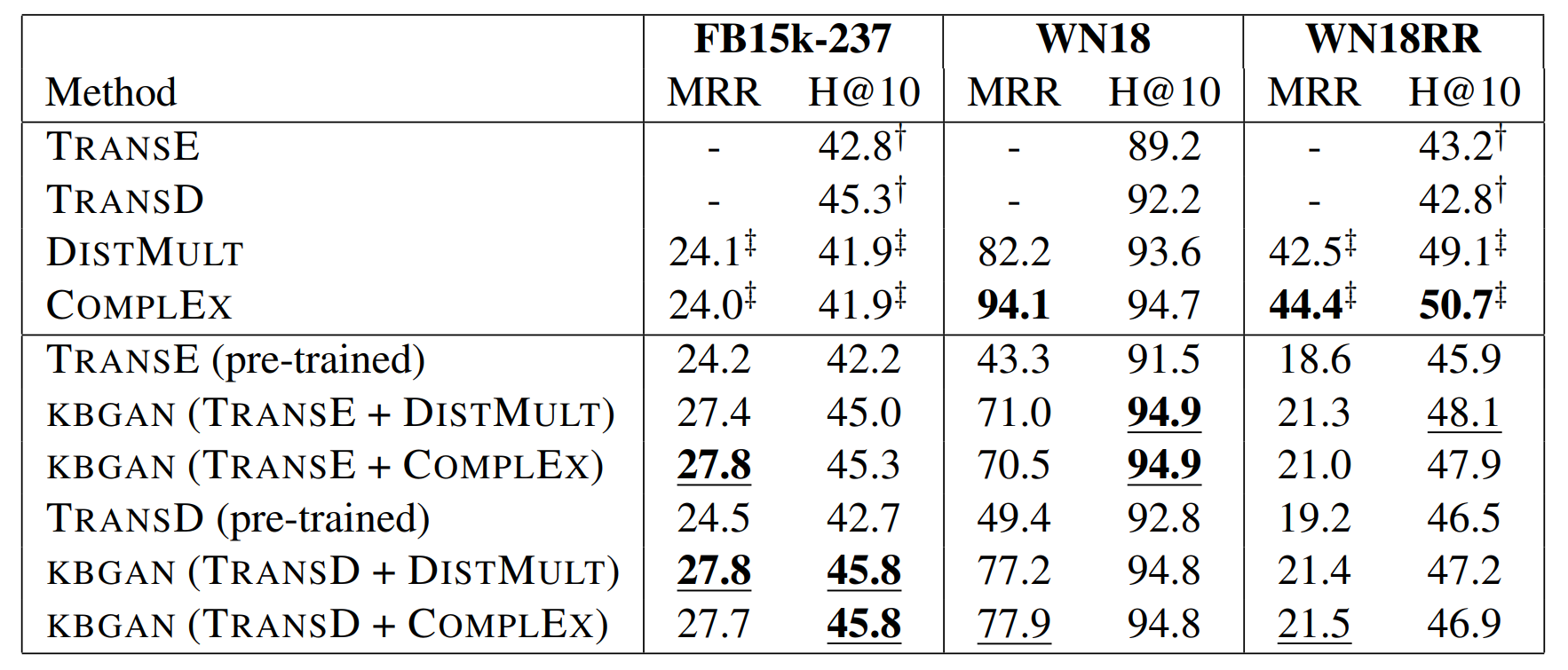
模型的效果并不是很好,相比于baseline提升不大,但是该论文是第一个提出用对抗学习进行知识图谱嵌入学习的
模型生成的负样本举例如下
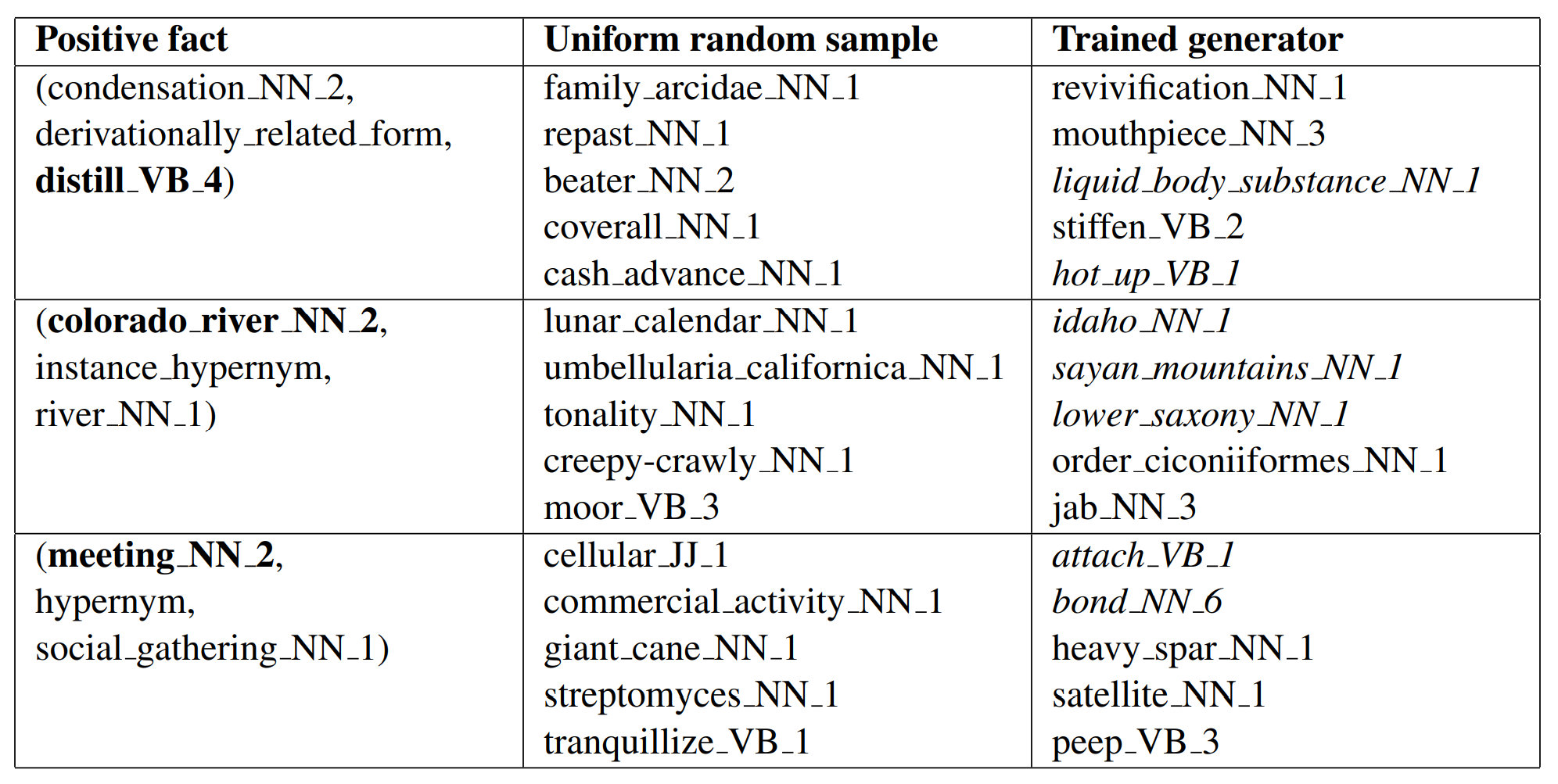
斜线表示与替换实体相关,模型确实生成了更高质量的负样本。