一、概述
机器学习是人工智能AI的一个分支,包括决策树、分类、聚类、贝叶斯学习、深度学习和神经网络等方面的研究。通过机器学习,我们可以从大量数据中挖掘出潜在的规律,并用于分析和预测。机器学习就是学习过程中尽量找到一个能够模拟真实情况的模型,即目标函数。输入是样本数据,输出是期望的结果,我们寄希望于建立的模型不仅适应于当前的样本数据,也适用于新的样本数据,即泛化能力。
二、基本步骤
1、收集:“巧妇难为无米之炊”,机器学习需要数据,首先,我们就要获取适当的数据。
2、数据预处理:数据可能具有不同的来源,单位或者格式可能不一致,同时还可能存在误差数据,因此,需要进行数据预处理。
3、拆分:将数据集拆分为两个部分,一部分用于训练,一部分用于预测。
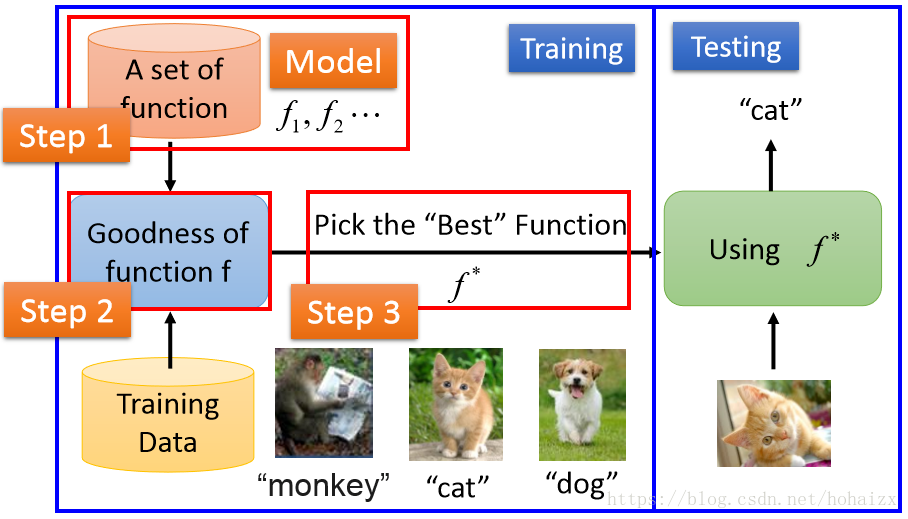
4、训练:根据不同的问题和情景选择适当的模型,这里的模型是可以看做一组函数的集合。模型碰到数据集的一部分时,将会尝试处理数据。测量其自身的性能并自动调整其参数,直到它能不断产生期望的结果具有足够的可靠性。
5、评估:为了评价模型的好坏,需要有一个评量标准,即损失函数。针对不同的问题,损失函数是不一样的。
6、优化:对模型进行优化。
三、按学习的方式进行分类
1、监督学习(supervised learning)
针对的是标签数据。计算机可以使用特定的模式来识别每种标记类型的新样本。监督学习的两种主要类型是分类和回归。
分类,是将一组数据分为不同的类。例如,电子邮件帐户上的垃圾邮件过滤器。过滤器分析你以前标记为垃圾邮件的电子邮件,并将它们与新邮件进行比较。如果它们匹配一定的百分比,这些新邮件将被标记为垃圾邮件并发送到适当的文件夹。那些比较不相似的电子邮件被归类为正常邮件并发送到你的邮箱。
回归,是指确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。在机器学习中,我们通过对标签按照合适的模型进行训练,得到相应的参数,并对未来进行预测。例如,天气预报,通过对气象事件的历史数据(即平均气温、湿度和降水量)进行回归分析,对未来时间内的天气进行预测。
2、无监督学习(unsupervised learning)
针对的是无标签数据,直接在数据点之间找有意义的关系,它的价值在于发现模式以及相关性。如,一个喜欢这瓶酒的人也喜欢这一个。无监督学习分为聚类和降维。
聚类,是指根据属性和行为对象进行分组。聚类有别于分类,分类中的组是给定的,而聚类不是。例如,对人群按照年龄进行划分,以采取有针对性的营销策略。
降维,是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。如主成分分析(PCA)。
3、强化学习(reinforcement learning)
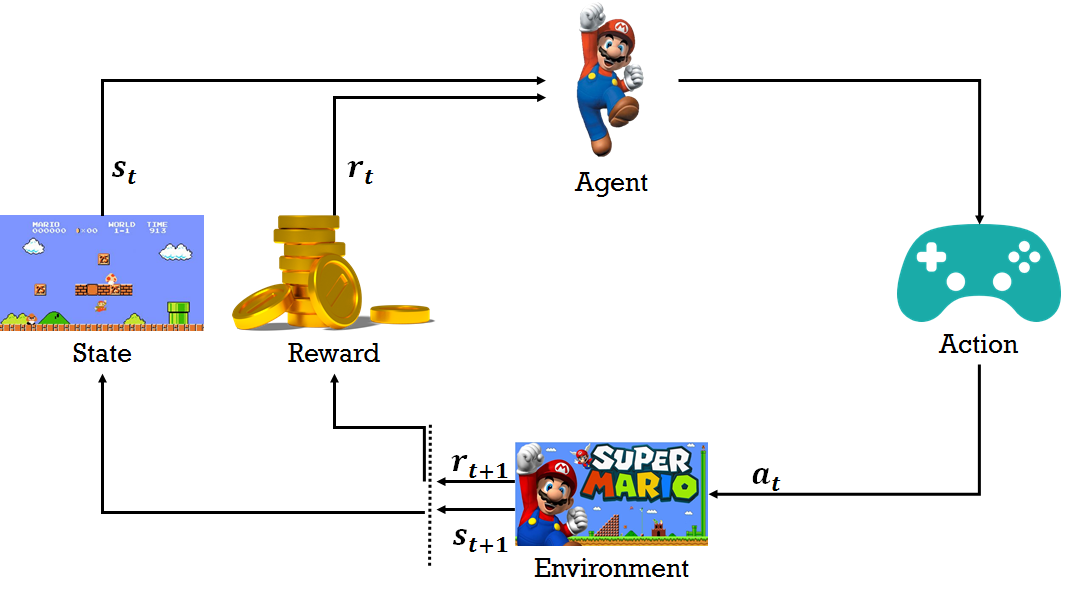
强化学习是一个学习最优策略(policy),可以让本体(agent)在特定环境(environment)中,根据当前状态(state),做出行动(action),从而获得最大回报(reward)。强化学习和有监督学习最大的不同是,每次的决定没有对与错,而是希望获得最多的累计奖励。强化学习可以用于控制机器人手臂、机器人导航、逻辑游戏等领域。