异常检测算法先是将一些正常的样本做为无标签样本来学习模型p(x),即评估参数,然后用学习到的模型在交叉验证集上通过F1值来选择表现最好的ε的值,然后在测试集上进行算法的评估。这儿用到了带有标签的数据,那么为什么不直接用监督学习对y=1和y=0的数据进行学习呢?而是要用到异常检测算法(先对无标签数据进行建模(当成无标签数据,其实都是正常的样本))。
异常检测与监督学习有哪些区别?

异常检测系统中一般正例样本(即异常的样本)很少(一般0-20个或者50个,50也是很常见的),这些异常样本用于交叉验证集与测试集中;负例样本(即正常的样本)数量很大,这些正常的样本用于拟合p(x),用于拟合参数u和σ2.
监督学习中,正例样本与负例样本都一样多。
对于异常检测算法通常有多种不同种类的异常,如引起飞机引擎故障的原因有很多种,你的正例样本较少里面可能只包含了5种、10种原因,如果我们根据这些有问题的样本来建立了一个学习模型,来了一个新的有问题的样本,故障的原因不在里面,我们就很难预测出这个是否是异常的飞机引擎,因为我们从来没有见过。
如果我们有大量的正例样本,这样就可以使用监督学习构建学习算法(学习大量的正样本与负样本),这样来了一个正例样本我们就可以通过看是否与训练集中的相似来判断
关键的区别:在异常检测算法中,我们只有少量的正样本(异常情况),因此学习算法不可能从这些正样本中学到太多东西,故我们会使用大量的负样本(正常情况),从这些负样本中学习p(x),同时我们会使用那部分少量的正样本(异常情况)来评估我们的算法(用于交叉验证集与测试集).
在垃圾邮件问题中,虽然垃圾邮件的种类会非常多(如购物邮件,钓鱼邮件等),但是因为我们有很多这些垃圾邮件的样本,我们可以从这些邮件中学习到垃圾邮件识别算法,因此我们一般会使用监督学习来进行垃圾邮件的识别。
异常检测与监督学习的一些应用
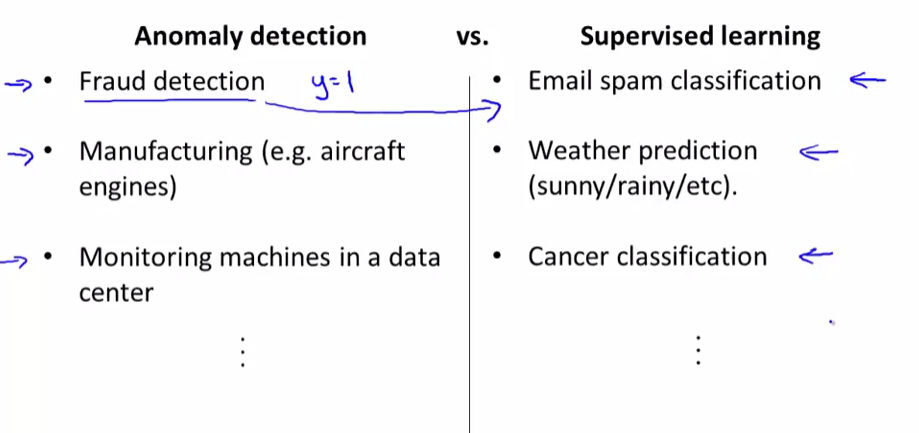
通常欺诈检测使用的是异常检测,但是如果你有大量的用户欺诈的数据,也可以使用监督学习。
在工业生产中,我们一般希望出现问题的产品很少,这时使用异常检测,如果出现问题的产品很多时,我们也可以转化为监督学习来进行学习。
总结
1>正样本(有问题的样本、异常样本)的数量很少时,使用异常检测系统