1.下载Hive安装包:
官网下载:http://hive.apache.org/downloads.html
百度云分享:https://pan.baidu.com/s/1M4LmdOXaq6T-PqkyvpFHQw
2.上传Hive的tar包,并解压:
解压:tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /usr/local/src/
修改解压后的文件名称:mv apache-hive-1.2.1-bin hive-1.2.1
3.安装MySql:
MySQL用于存储Hive的元数据,不建议使用Hive自带Derby作为Hive的元数据库,因为它的数据文件默认保存在运行
目录下面,下次换一个目录启动就看不见之前的数据了
4.修改配置文件:主要是配置metastore(元数据存储)存储方式
4.1. vi /usr/local/src/hive-1.2.1/conf/hive-site.xml(存储方式:内嵌Derby方式、本地mysql、远端mysql)
4.2 粘贴如下内容:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value> //mysql密码不正确, 查看hive-site.xml配置与mysql的密码是否一致
<description>password to use against metastore database</description>
</property>
</configuration>
5.拷贝jar包:
拷贝mysql驱动jar包到Hive的lib目录下面去,下载路径:https://pan.baidu.com/s/1azWOAdloQR6Y_Ov9cREdGw
6.启动Hive:启动诸多问题参考:http://www.cnblogs.com/qifengle-2446/p/6424426.html
启动Hive之前需要先把Hadoop集群启动起来。然后使用下面的命令来启动Hive:
启动命令:/usr/local/src/hive-1.2.1/bin/hive
出现如下表示启动成功:

验证Hive运行正常:启动Hive以后输入下面的命令:

输出为:

创建数据库,输出结果如下:数据库的数据文件被存放在HDFS的/user/hive/warehouse/test_db.db下面

创建表:表的数据文件被存放在HDFS的/user/hive/warehouse/test_db.db/t_test下面

插入数据
准备下面的数据文件,sz.data,文件内容如下:
1,张三 2,李四 3,风凌 4,三少 5,月关 6,abc
上传到HDFS上:hadoop fs -put sz.data /user/hive/warehouse/test_db.db/t_test/sz.data
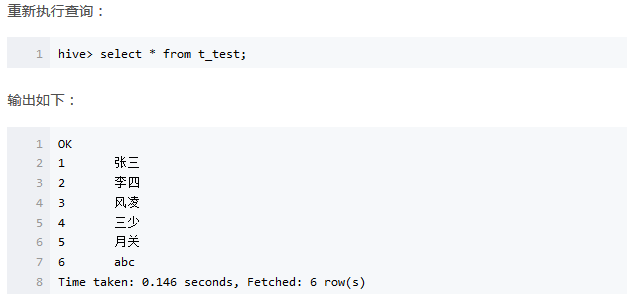
然后使用下面的语句尝试进行一下查询:

输出的结果如下:

数据没有被成功识别,这是因为没有指定数据的分隔符。使用下面的命令清空表数据:

count查询:select count(1) from t_test;
能看到下面的运行提示:
Query ID = root_20170325234306_1aaf3dcf-e758-4bbd-9ae5-e649190d8417 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1490454340487_0001, Tracking URL = http://amaster:8088/proxy/application_1490454340487_0001/ Kill Command = /root/apps/hadoop-2.7.3/bin/hadoop job -kill job_1490454340487_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2017-03-25 23:43:23,084 Stage-1 map = 0%, reduce = 0% 2017-03-25 23:43:36,869 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.71 sec 2017-03-25 23:43:48,392 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.4 sec MapReduce Total cumulative CPU time: 3 seconds 400 msec Ended Job = job_1490454340487_0001 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.4 sec HDFS Read: 6526 HDFS Write: 2 SUCCESS Total MapReduce CPU Time Spent: 3 seconds 400 msec
发现Hive的速度确实很慢,不适合用于在线业务支撑,同时,在YARN集群里面也可以看到任务信息

输出结果如下:

Hive的元数据
接下来,我们来看一下在MySQL里面保存的Hive元数据
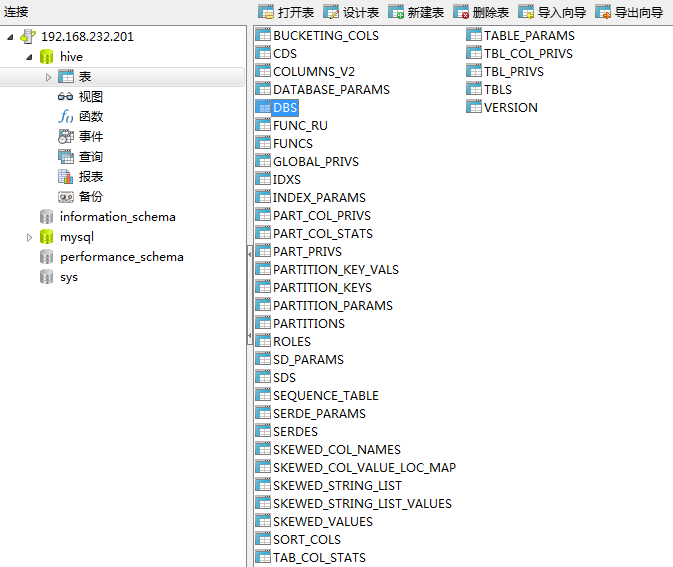
可以看到有很多表。其中DBS表记录了数据库的记录:
