1.YARN的运行机制
1.1.概述:
Yarn集群:负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager
Yarn是一个资源调度(作业调度和集群资源管理)平台,负责为运算程序提供服务器运算资源(包括运行
程序的jar包,配置文件,CPU,内存,IO等),相当于一个分布式的操作系统平台,而Mapreduce等运算程
序则相当于运行于操作系统之上的应用程序
Linux的资源隔离机制cgroup实现了CPU和内存的隔离(一个程序分配单独的CPU和内存),从而给不同的进
程分开运算资源,其中虚拟化技术就是做这种资源隔离的,例如Docker、OpenStack等,在NodeManager中的
运行容器Container就包含了一定的CPU+内存
1.2.YARN的重要概念:
1.Yarn只负责程序运行所需资源的分配回收等调度任务,与用户提交的应用程序的内部运行机制完全
无关,所以Yarn已经成为一个通用的资源调度平台,许多运算框架都可以借助它来实现资源调度,如spark
storm,从而提高资源利用率,方便数据共享
2.yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
3.yarn中的主管角色叫ResourceManager
4.yarn中具体提供运算资源的角色叫NodeManager
5.这样一来,yarn其实就与运行的用户程序完全解耦,就意味着yarn上可以运行各种类型的分布式运算程
序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序,tez ……只要他们各自的框架中
有符合yarn规范的资源请求机制即可
1.3.MR运行在YARN集群的流程分析:
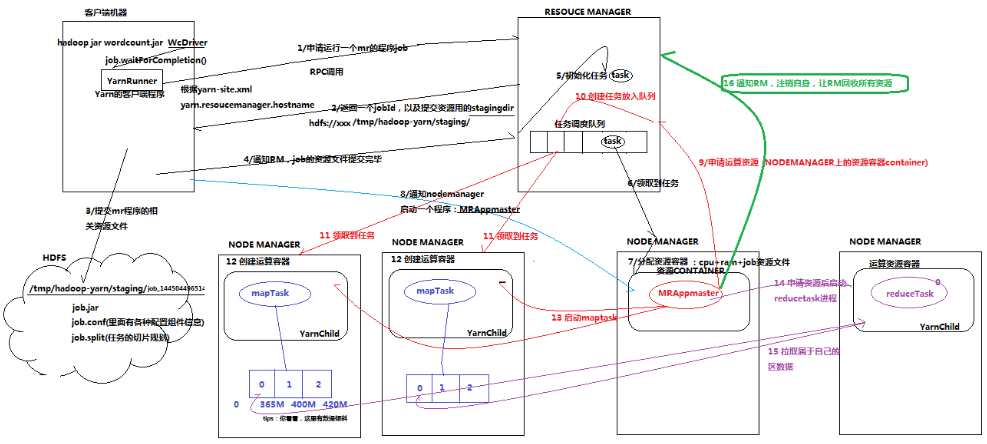
详细步骤说明:
提交过程
- 当客户端(jobclient)提交一个MapReduce程序(作业/job submission)后,将获取到一个跟Yarn通信的客户端程序YarnRunner,它本质上是一个动态代理对象。它负责将任务提交到Yarn集群中
- 接着,YarnRunner根据配置文件yarn-site.xml(yarn.resoucemanager.hostname)中的配置信息向ResourceManager申请提交一个Application,此时ResourceManager会返回一个Application资源提交路径hdfs://xxx/.staging以及job_id
- 提交程序运行所需资源到ResourceManager指定的HDFS目录中,包含job.split(任务的切片规划),job.xml,job.jar等,然后通知ResourceManager,job的资源文件提交完成,申请运行MRAppMaster
运行过程
- 由于ResourceManager会接收很多程序,而运算资源是有限的。因此不能保证每个任务一提交就能运行,所以需要有一个调度机制(调度策略包括FIFO:First Input First Output,先入先出队列;Fair;Capacity等)
- 然后由ResourceManager把Job封装成一个Task对象放入任务调度队列
- NodeManager与ResourceManager通信,领取需要运行的Task任务,并根据Task的任务描述,由NodeManager生成任务运行的容器container,并从HDFS上把任务需要的文件下载下来,放到container的工作目录中,启动MRAppmaster在该容器中运行
- MRAppmaster请求ResourceManager分配若干个Container来启动MapTask,此时ResourceManager同样会将Task放入队列中,NodeManager与ResourceManager通信时,会领取这个Task。然后由NodeManager创建一个容器,有了容器后,MRAppmaster会发送启动程序的脚本给NodeManager。MapTask就运行起来。并由MRAppmaster进行监管,如果某个MapTask失败了,MRAppmaster会申请一个新的容器去再运行这个MapTask
- 等到MapTask运行完毕之后,输出结果保存在container的工作目录下面
- MRAppmaster再申请容器运行ReduceTask
- ReduceTask运行起来以后,会去下载MapTask的输出结果,每个ReduceTask获取自己相应的分区数据,
- ReduceTask执行完毕后,MRAppmaster会向ResourceManager注销自己,YARN会回收所有的计算资源
总结:1. Yarn只负责程序运行所需要资源的分配回收等调度任务,和MapReduce程序只需要请求资源和Yarn并没有什么耦合。所以许许多多的其他的程序也可以在YARN上运行,比如说Spark,Storm等
2. Hadoop1中没有Yarn,它使用JobTracker和TaskTracker。客户端提交任务给JobTracker,JobTracker负责启动MapTask和ReduceTask。JobTracker知道我们的程序是怎么运行的,即JobTracker和MR程序是紧紧耦合在一起的,JobTracker只有一个节点,要负责资源调度和应用的运算流程管理监控,如果JobTracker挂了,所有的程序都不能运行了,而Hadoop2中MRAppmaster一旦挂了,只会影响到当前这一个程序