前言
一直以来,对于搜索时模糊匹配的优化一直是个让人头疼的问题,好在强大pgsql提供了优化方案,下面就来简单谈一谈如何通过索引来优化模糊匹配
案例
我们有一张千万级数据的检查报告表,需要通过检查报告来模糊搜索某个条件,我们先创建如下索引:
CREATE INDEX lab_report_report_name_index ON lab_report USING btree (report_name);
然后搜个简单的模糊匹配条件如 LIKE "血常规%",可以发现查询计划生成如下,索引并没有被使用上,这是因为传统的btree索引并不支持模糊匹配
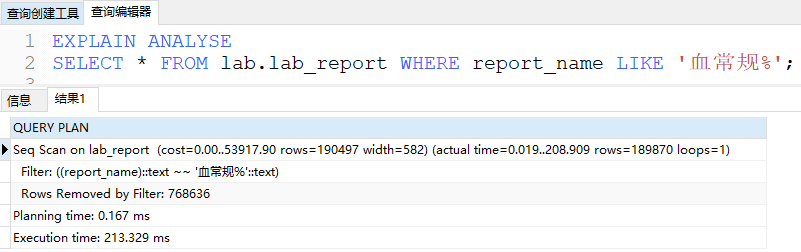
查阅文档后发现,pgsql可以在Btree索引上指定操作符:text_pattern_ops、varchar_pattern_ops和 bpchar_pattern_ops,它们分别对应字段类型text、varchar和 char,官方解释为“它们与默认操作符类的区别是值的比较是严格按照字符进行而不是根据区域相关的排序规则。这使得这些操作符类适合于当一个数据库没有使用标准“C”区域时被使用在涉及模式匹配表达式(LIKE或POSIX正则表达式)的查询中。”, 有些抽象,我们先试试看。创建如下索引并查询刚才的条件 LIKE"血常规%":(参考pgsql的文档 https://www.postgresql.org/docs/10/indexes-opclass.html)
CREATE INDEX lab_report_report_name_index ON lab.lab_report (report_name varchar_pattern_ops);

发现确实可以走索引扫描 ,执行时间也从213ms优化到125ms,但是,如果搜索LIKE "%血常规%"就又会走全表扫描了! 这里我们引入本篇博客的主角"pg_trgm"和"pg_bigm"。
创建这两个索引前分别需要引入如下两个扩展包 :
CREATE EXTENSION pg_trgm; CREATE EXTENSION pg_bigm;
这两个索引的区别是:“pg_tigm”为pgsql官方提供的索引,"pg_tigm"为日本开发者提供。下面是详细的对比:(参考pg_bigm的文档 http://pgbigm.osdn.jp/pg_bigm_en-1-2.html)
Comparison with pg_trgm
The pg_trgm contrib module which provides full text search capability using 3-gram (trigram) model is included in PostgreSQL. The pg_bigm was developed based on the pg_trgm. They have the following differences:
| Functionalities and Features | pg_trgm | pg_bigm |
|---|---|---|
| Phrase matching method for full text search | 3-gram | 2-gram |
| Available index | GIN and GiST | GIN only |
| Available text search operators | LIKE (~~), ILIKE (~~*), ~, ~* | LIKE only |
| Full text search for non-alphabetic language (e.g., Japanese) |
Not supported (*1) | Supported |
| Full text search with 1-2 characters keyword | Slow (*2) | Fast |
| Similarity search | Supported | Supported (version 1.1 or later) |
| Maximum indexed column size | 238,609,291 Bytes (~228MB) | 107,374,180 Bytes (~102MB) |
- (*1) You can use full text search for non-alphabetic language by commenting out KEEPONLYALNUM macro variable in contrib/pg_trgm/pg_trgm.h and rebuilding pg_trgm module. But pg_bigm provides faster non-alphabetic search than such a modified pg_trgm.
- (*2) Because, in this search, only sequential scan or index full scan (not normal index scan) can run.
pg_bigm 1.1 or later can coexist with pg_trgm in the same database, but pg_bigm 1.0 cannot.
如无特殊要求推荐使用"pg_bigm",我们测试一下效果:
CREATE INDEX lab_report_report_name_index ON lab_report USING gin (report_name public.gin_bigm_ops);
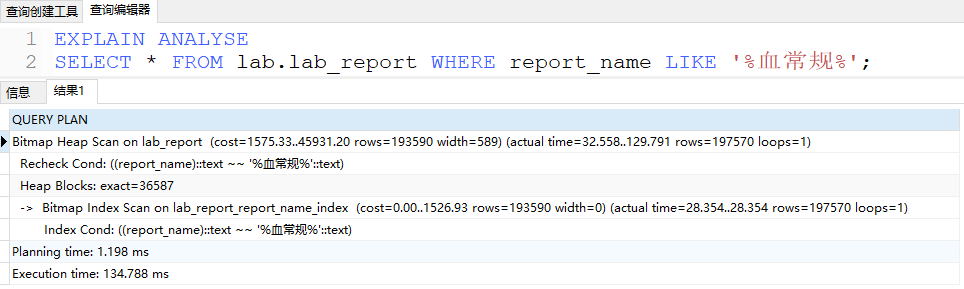
可以使用位图索引扫描,对于本次案例,使用pg_trgm效果同pg_bigm。
以上
本文只是简单的介绍许多细节并未做深入的分析,欢迎留言指教或者讨论