我们在往ceph rgw中写入文件时,这些文件在底层其实就是一个一个的对象,只要找到某个文件对应的对象,就能通过这些对象来将原始的文件拼接出来。
1、查询ceph rgw中的文件列表:
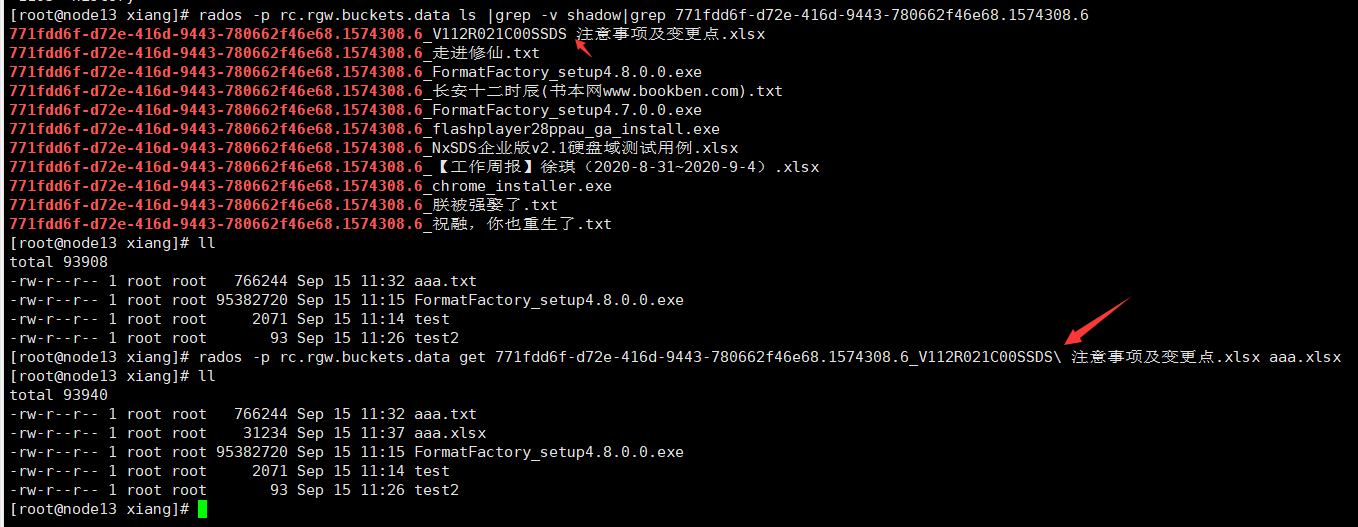
rados -p rc.rgw.buckets.data ls |grep -v shadow
上面这条命令中的 rc.rgw.buckets.data 是ceph rgw网关对应的数据存储池,下面图片中每一行的最后一列就是文件的文件名称。
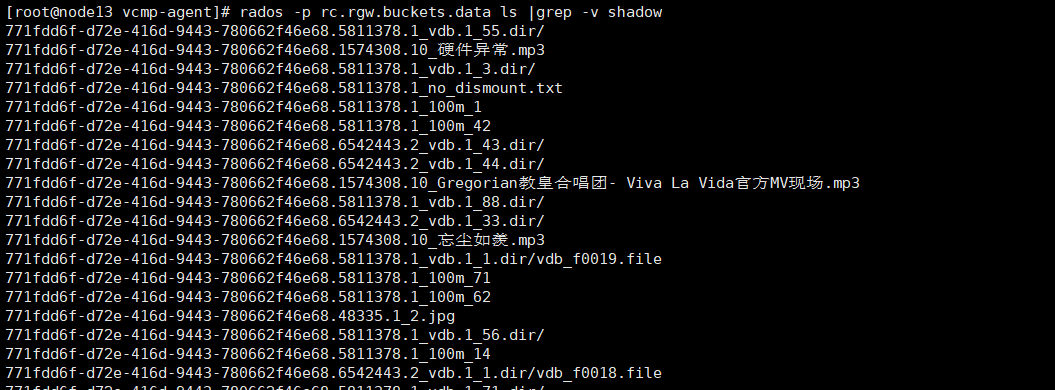
2、查询网关中的桶对应的marker:
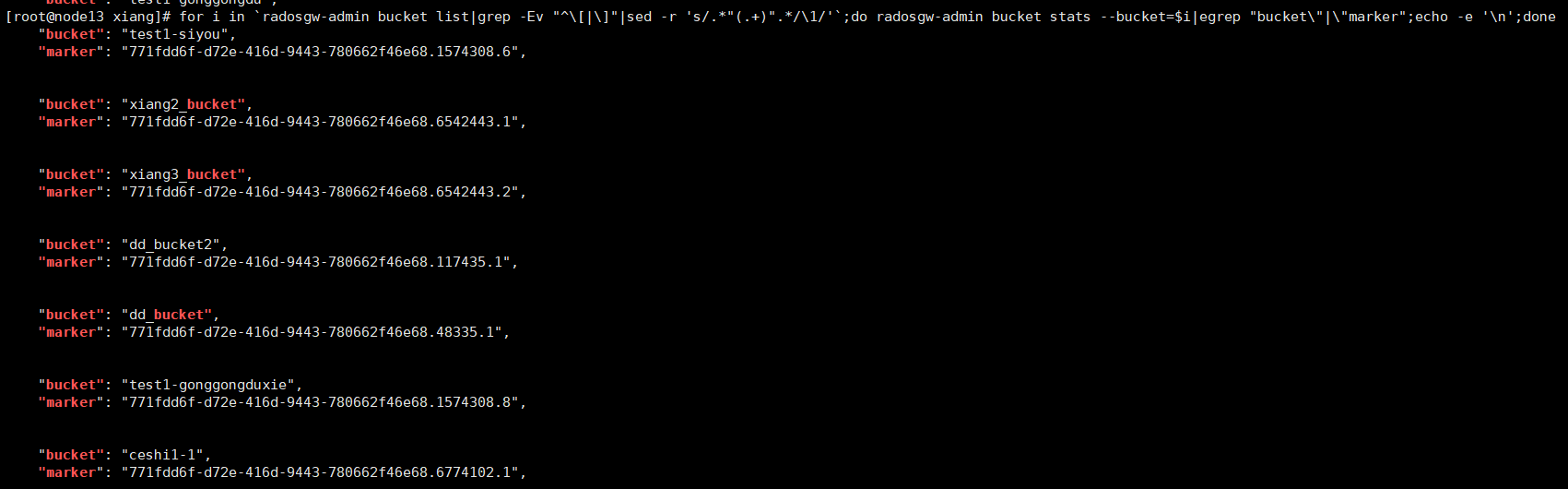
for i in `radosgw-admin bucket list|grep -Ev "^[|]"|sed -r 's/.*"(.+)".*/1/'`;do radosgw-admin bucket stats --bucket=$i|egrep "bucket"|"marker";echo -e ' ';done
下面图片中显示每一个桶对应的标签,根据这个标签我们再来查询一下每个桶下面的文件列表。
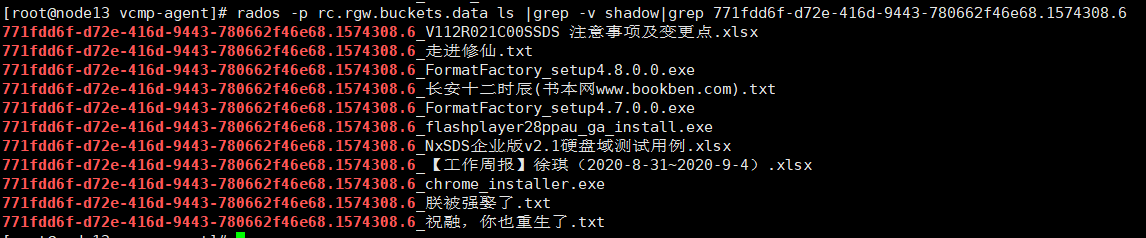
3、根据桶的marker,查看指定桶下面的文件列表:
rados -p rc.rgw.buckets.data ls |grep -v shadow|grep 771fdd6f-d72e-416d-9443-780662f46e68.1574308.6
每一行的最后一列就是文件的名称,有了文件名称就能通过该名称来查询这个文件对应的对象列表。
4、查找指定文件的所有对象的后缀:
rados -p rc.rgw.buckets.data getxattr '771fdd6f-d72e-416d-9443-780662f46e68.1574308.6_V112R021C00SSDS 注意事项及变更点.xlsx' user.rgw.manifest | ceph-dencoder type RGWObjManifest import - decode dump_json
这里是查询文件的元数据,从元数据中找到该文件的对象后缀,有了这个,我们就能知道哪些对象是这个文件的了。
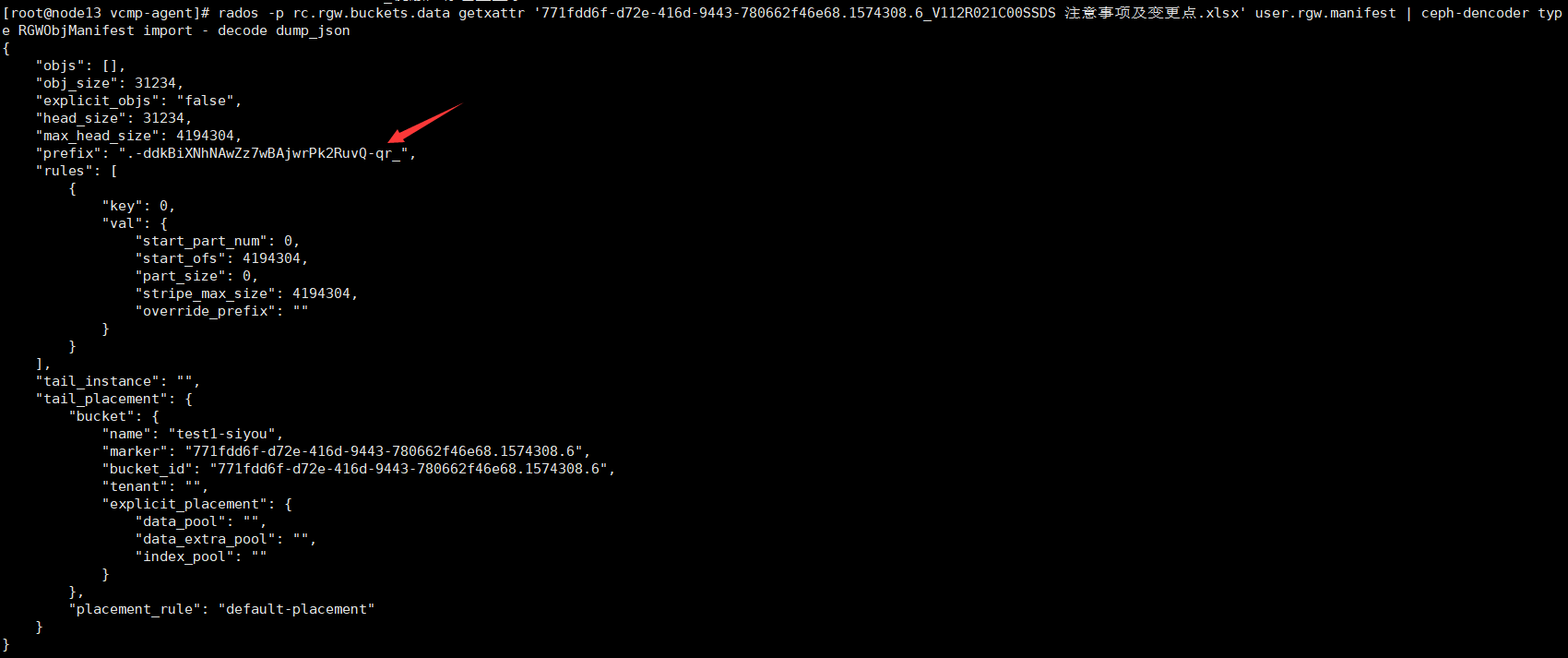
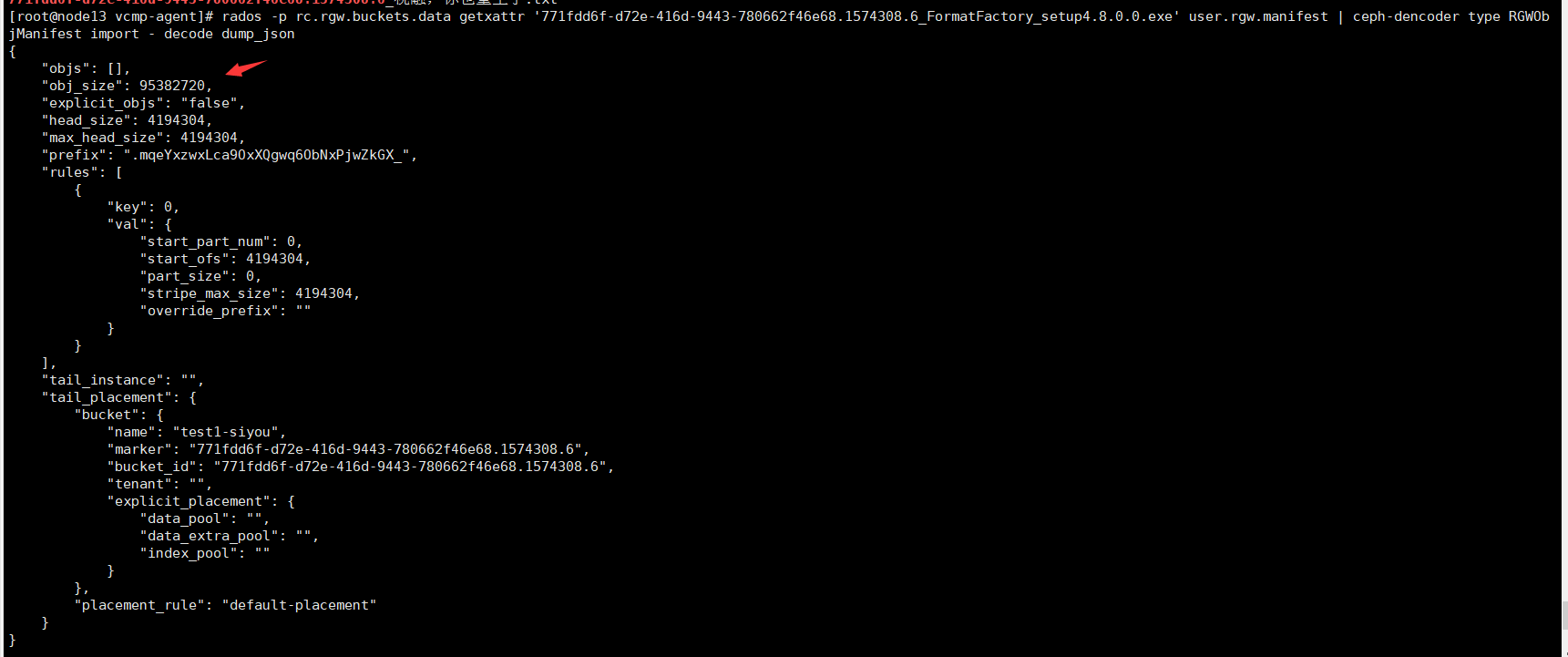
5、根据该文件的对象后缀查找出该文件的所有对象(注意如果文件本身小于4mb的话,是没有其他对象的,所以查询结果会是空的,也就是说小于4M的文件,直接使用步骤3中的那个对象就能把文件恢复出来了):
rados -p rc.rgw.buckets.data ls |grep .mqeYxzwxLca9OxXQgwq6ObNxPjwZkGX_
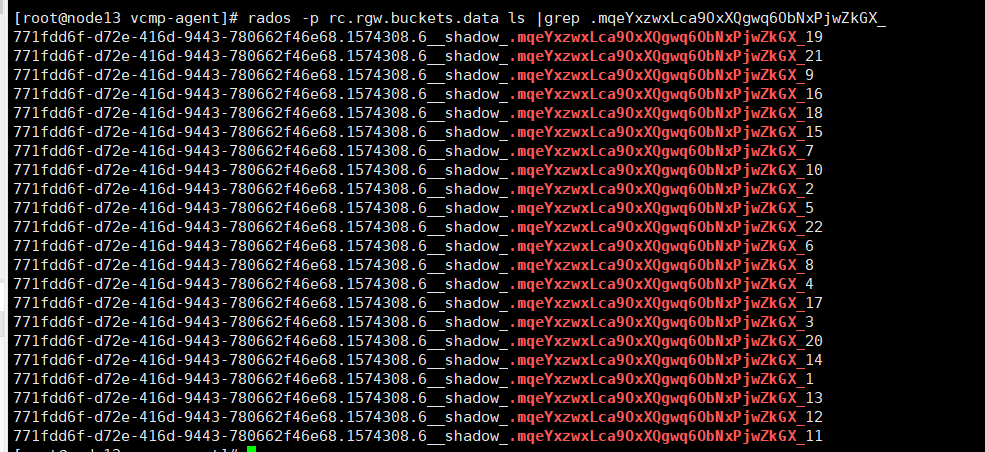
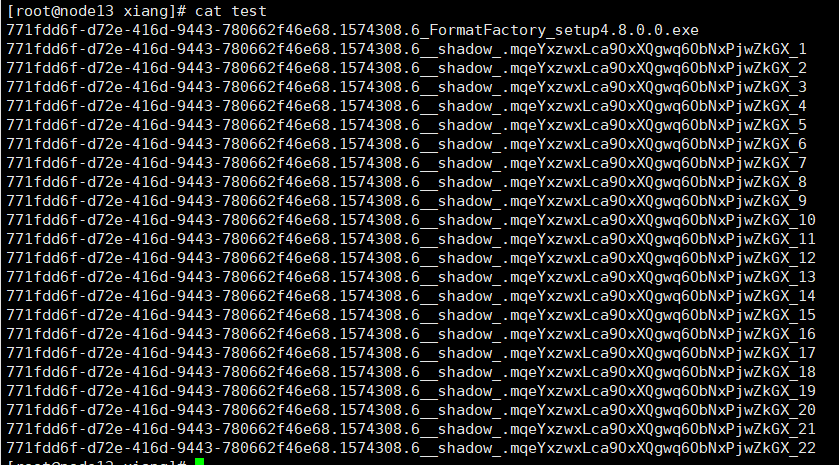
6、将文件的所有对象按照序号顺序排列好,然后导出到一个文件中,注意一定要按照序号排好,不然恢复出来的文件无效:
rados -p rc.rgw.buckets.data ls |egrep "771fdd6f-d72e-416d-9443-780662f46e68.1574308.6_FormatFactory_setup4.8.0.0.exe|.mqeYxzwxLca9OxXQgwq6ObNxPjwZkGX_"|sort>test
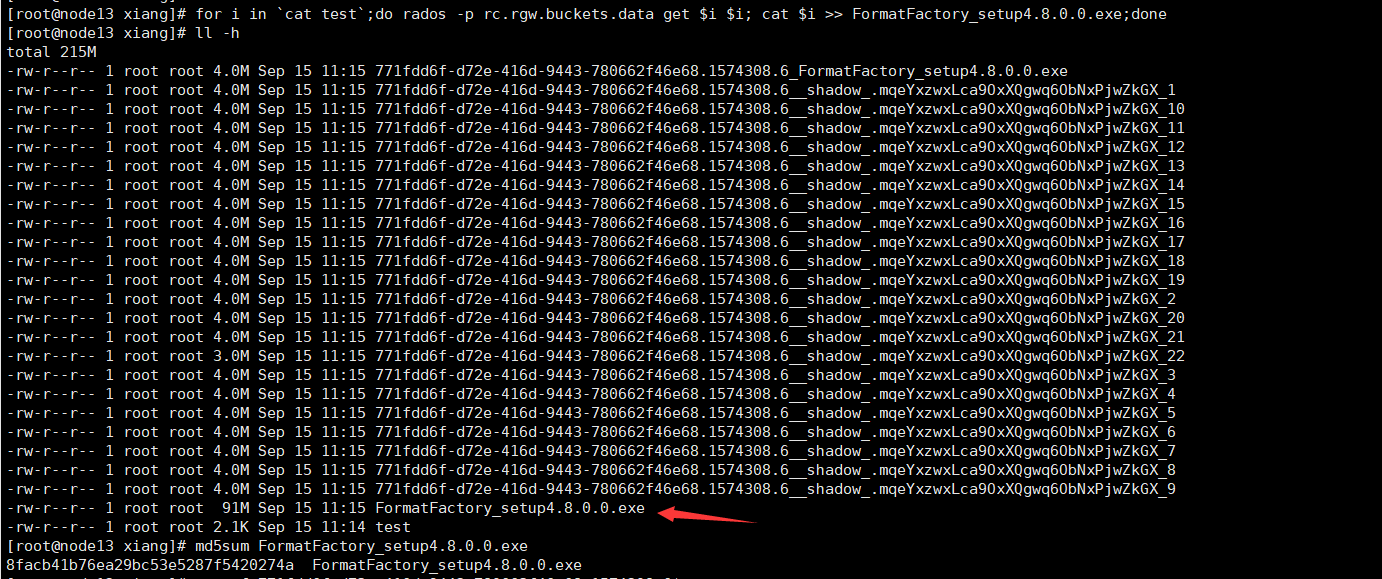
7、开始使用文件的对象来拼接文件:
for i in `cat test`;do rados -p rc.rgw.buckets.data get $i $i; cat $i >> FormatFactory_setup4.8.0.0.exe;done
遇到的问题:
1、如果对象名称中有空格,在空格前面加个“”杠即可将对象导出: