深入理解final和static关键字 #
参考:http://blog.csdn.net/qq1028951741/article/details/53418852
final关键字
final关键字可以应用于类、方法以及变量。
final声明变量
final声明变量可以保证在构造器函数返回之前,这个变量的值已经被设置。详细可以看final声明的重排序规则。分为三种情况:
- final声明基本数据类型变量:该变量只能被赋值一次,赋值后值不再改变。
- final声明引用数据类型变量:final只保证这个引用类型变量所引用的地址不会改变,即一直引用同一个对象,但是这个对象的内容(对象的非final成员变量的值可以改变)完全可以发生改变(比如
final int[] intArray;,intArray不允许再引用其他对象,但是intArray内的int值却可以被修改)。 - final声明方法参数或者局部变量:用来保证该参数或者局部变量在这个函数内部不允许被修改。
final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。接口中声明的所有变量本身是final的。另外,final变量定义的时候,可以先声明,而不给初值,这种变量也称为final空白,无论什么情况,编译器都确保空白final在使用之前必须被初始化。但是,final空白在final关键字的使用上提供了更大的灵活性。比如:
private final int E; //final空白,必须在初始化对象的时候赋初值
public Test3(int x) {
E = x;
}
final声明方法
final声明的方法不可以被重写,但可以被继承。final不能用于修饰构造方法。使用final方法的原因有二:
第一、把方法锁定,防止任何继承类修改它的意义和实现。
第二、高效。因为在编译的时候已经静态绑定了,不需要在运行时再动态绑定。
final声明类
final声明的类不可以被继承,final类中的方法默认是final的。但是成员变量却不一定是final的,必须额外给成员变量声明为final。注意:一个类不能同时被abstract和final声明。
在设计类时候,如果这个类不需要有子类,类的实现细节不允许改变,并且确信这个类不会被扩展,那么就设计为final类。比如Java中有许多类是final的,譬如String, Interger以及其他包装类。
final域(变量)声明的重排序规则
final域的重排序规则,编译器和处理器要遵守两个重排序规则:
- 禁止把final域的写重排序到构造函数之外(即必须先对final域赋值,然后才能引用包含final域的对象)。编译器会在final域的写之后,构造函数return之前,插入一个StoreStore屏障,从而禁止处理器把final域的写重排序到构造函数之外。
- 初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序(即必须先读包含final域的对象,然后才能读final域)。
而普通域是可以被重排序到构造器之外的。重排序可能导致一个线程看到一个对象的时候,这个对象还没有初始化完毕(部分初始化或者完全没有经过初始化,即读取到对象为null)。
下面,我们通过一些示例性的代码来分别说明这两个规则(在这里通过外部方法不安全的发布了对象,即对象还没有构造完成就发布了对象,这种例子也就仅仅起到说明作用):
public class FinalExample {
int i; //普通变量
final int j; //final变量
static FinalExample obj;
public void FinalExample () { //构造函数
i = 1; //写普通域
j = 2; //写final域
}
public static void writer () { //写线程A执行
obj = new FinalExample ();
}
public static void reader () { //读线程B执行
FinalExample object = obj; //读对象引用
int a = object.i; //读普通域
int b = object.j; //读final域
}
}
这里假设一个线程A执行writer ()方法,随后另一个线程B执行reader ()方法。下面我们通过这两个线程的交互来说明这两个规则。
写final域的重排序规则
现在让我们分析writer ()方法。writer ()方法只包含一行代码:obj = new FinalExample ()。这行代码包含两个步骤:
- 构造一个FinalExample类型的对象;
- 把这个对象的引用赋值给引用变量obj。
假设线程B读对象引用与读对象的成员域之间没有重排序(首先说明重排序规则1),下图是一种可能的执行时序:
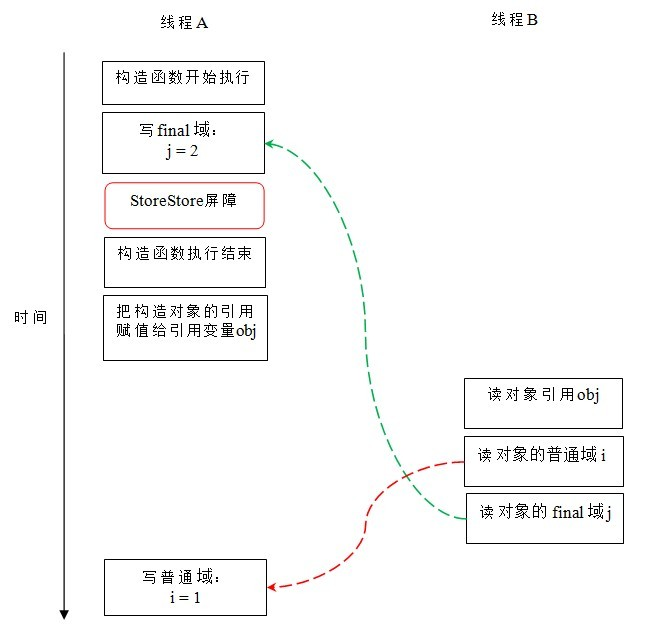
在上图中,写普通域的操作被编译器重排序到了构造函数之外,读线程B错误的读取了普通变量i赋值之前的零值。而写final域的操作,被写final域的重排序规则“限定”在了构造函数之内,读线程B正确的读取了final变量赋值之后的值。即在读线程B“看到”对象引用obj时,很可能obj对象还没有构造完成(对普通域i的写操作被重排序到构造函数外,此时初始值1还没有写入普通域i)。
读final域的重排序规则
初次读对象引用与初次读该对象包含的final域,这两个操作之间存在间接依赖关系。由于编译器遵守间接依赖关系,因此编译器不会重排序这两个操作。大多数处理器也会遵守间接依赖,大多数处理器也不会重排序这两个操作。但有少数处理器允许对存在间接依赖关系的操作做重排序(比如alpha处理器),这个规则就是专门用来针对这种处理器。
reader()方法包含三个操作:
- 初次读引用变量obj;
- 初次读引用变量obj指向对象的普通域i。
- 初次读引用变量obj指向对象的final域j。
现在我们假设写线程A没有发生任何重排序,同时程序在不遵守间接依赖的处理器上执行,下面是一种可能的执行时序:
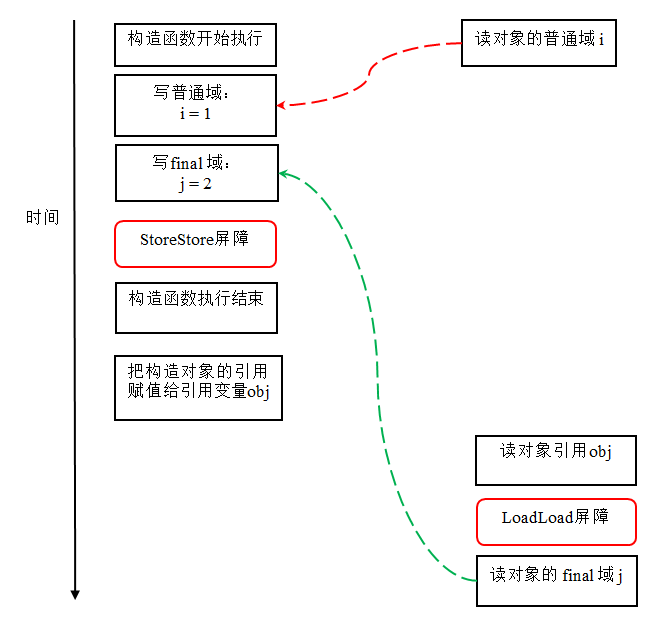
在上图中,读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该域还没有被写线程A写入,这是一个错误的读取操作。而读final域的重排序规则会把读对象final域的操作“限定”在读对象引用之后,此时该final域已经被A线程初始化过了,这是一个正确的读取操作。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
如果final域是引用类型
请看下列示例代码:
public class FinalReferenceExample {
final int[] intArray; // final是引用类型
static FinalReferenceExample obj;
public FinalReferenceExample() { // 构造函数
intArray = new int[1]; // 1
intArray[0] = 1; // 2
}
public static void writerOne() { // 写线程A执行
obj = new FinalReferenceExample(); // 3
}
public static void writerTwo() { // 写线程B执行
obj.intArray[0] = 2; // 4
}
public static void reader() { // 读线程C执行
if (obj != null) { // 5
int temp1 = obj.intArray[0]; // 6
}
}
}
这里final域为一个引用类型,它引用一个int型的数组对象。对于引用类型,写final域的重排序规则对编译器和处理器增加了如下约束:
在构造函数内对一个final引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。(即先对final域引用的对象赋值后才能读取此final域引用的对象)
对上面的示例程序,我们假设首先线程A执行writerOne()方法,执行完后线程B执行writerTwo()方法,执行完后线程C执行reader ()方法。下面是一种可能的线程执行时序:

在上图中,1是对final域的写入,2是对这个final域引用的对象的成员域的写入,3是把被构造的对象的引用赋值给某个引用变量。这里除了前面提到的1不能和3重排序外,2和3也不能重排序。JMM(Java内存模型)可以确保读线程C至少能看到写线程A在构造函数中对final引用对象的成员域的写入。即C至少能看到数组下标0的值为1。而写线程B对数组元素的写入,读线程C可能看的到,也可能看不到。JMM不保证线程B的写入对读线程C可见,因为写线程B和读线程C之间存在数据竞争,此时的执行结果不可预知。
如果想要确保读线程C看到写线程B对数组元素的写入,写线程B和读线程C之间需要使用同步原语(lock或volatile)来确保内存可见性。
为什么final引用不能从构造函数内“逸出”
前面我们提到过,写final域的重排序规则可以确保:在引用变量为任意线程可见之前,该引用变量指向的对象的final域已经在构造函数中被正确初始化过了。其实要得到这个效果,还需要一个保证:在构造函数内部,不能让这个被构造对象的引用为其他线程可见,也就是对象引用不能在构造函数中“逸出”。为了说明问题,让我们来看下面示例代码:
public class FinalReferenceEscapeExample {
final int i;
static FinalReferenceEscapeExample obj;
public FinalReferenceEscapeExample () {
i = 1; //1写final域
obj = this; //2 this引用在此“逸出”
}
public static void writer() {
new FinalReferenceEscapeExample ();
}
public static void reader() {
if (obj != null) { //3
int temp = obj.i; //4
}
}
}
假设一个线程A执行writer()方法,另一个线程B执行reader()方法。这里的操作2使得对象还未完成构造前就为线程B可见。即使这里的操作2是构造函数的最后一步,且即使在程序中操作2排在操作1后面,执行read()方法的线程仍然可能无法看到final域被初始化后的值,因为这里的操作1和操作2之间可能被重排序。实际的执行时序可能如下图所示:

final关键字的好处
- 将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行分析优化。比如被final修饰的方法,JVM会尝试为之寻求内联,这对于提升Java的效率是非常重要的。因此,假如能确定方法不会被继承,那么尽量将方法定义为final的。
- 被final修饰的常量,在编译阶段会存入调用类的常量池中(比如子类继承父类,那么父类的final常量会被复制到子类常量池中),当子类使用这个常量时,不会引起父类的初始化。
- final可以用于不可变对象的创建,而不可变对象一定是线程安全的。
static关键字
static关键字可以应用于内部类(注意对于外部类是不能用static声明的)、成员方法、代码块以及成员变量(static不可以修饰局部变量)。
static声明变量
被static修饰的变量,叫静态变量或类变量;没有被static修饰的变量,叫实例变量。
两者的区别是:
- 静态变量属于类,在内存中只有一个复制(所有实例都指向同一个内存地址,节省空间),JVM在加载类的过程中完成静态变量的内存分配,可用
类名.静态变量名直接访问(方便),当然也可以通过对象名.静态变量名来访问(但是这是不推荐的)。 - 实例变量属于对象,每创建一个实例,就会为实例变量分配一次内存,实例变量可以在内存中有多个拷贝,互不影响(灵活),只能通过
对象名.实例变量名来引用。
static声明方法
静态方法的好处就是不用生成类的实例就能直接调用,只要通过 类名.静态方法名 就可以访问,不需要耗费资源反复创建对象,因为在类加载之后就已经在内存中了。而非static方法是对象的方法,只有在对象被实例化以后才能使用。
静态方法不能使用this和super关键字,不能调用非static方法(this涉及到当前对象,super 涉及到父类对象),只能访问所属类的静态成员变量和成员方法。因为当static方法被调用时,这个类的对象可能还没创建,即使已经被创建,也无法确定调用的是哪个对象的方法。因为static方法独立于任何实例,因此static方法必须被实现,而不能是抽象的abstract。
例子:
- 如果这个方法是作为一个工具来使用,可以声明为static,不用new一个对象出来就可以使用了,比如连接到数据库,声明一个 getConnection()的方法,就定义为静态的,因为连接到数据库不是某一个对象所特有的,它只作为一个连接到数据库的工具。
- 实现单例模式:
立即加载/“饿汉模式”
什么是立即加载?立即加载就是在调用方法前,实例已经被创建了(其实是类加载的时候已经将对象创建完毕),常见的实现办法就是直接new一个private static的实例,然后通过public static的方法返回实例。而立即加载从中文的语境来看,有“着急”、“急迫”的含义,所以也称 为“饿汉模式”。
/**
* 立即加载方式==饿汉模式
* 此代码版本为立即加载,此版本代码的缺点是类加载时就要初始化对象
*/
public class Test {
private Test() {}
private static Test uniqueInstance = new Test();
public static Test getInstance() {
return uniqueInstance;
}
}
延迟加载/“懒汉模式”
延迟加载就是在调用get()方法时实例才被创建。比如推迟一些高开销的对象初始化操作直到需要使用这些对象。常见的实现办法就是在get()方法中进行new实例化。而延迟加载从中文的语境来看,是“缓慢”、“不急迫” 的含义,所以也称为“懒汉模式”。但是在《Java并发编程实战》16.2节中给出说明,双检测机制已经被广泛地废弃 了——促使该模式出现的驱动力(无竞争同步的执行速度很慢,以及jvm启动时很慢)已经不复存在,因而它不是一种髙效的优化措施。延迟初始化占位类模式(即下面的内部类方式)能带来同样的优势,并且更容易理解。
/**
* 延迟加载方式==懒汉模式
* 使用双检测机制,尽量减小同步块的大小,同时保证线程安全
*/
public class Test {
private Test() {}
private volatile static Test uniqueInstance;
public static Test getInstance() {
if (uniqueInstance == null) {
synchronized (Test.class) {
if (uniqueInstance == null) {
uniqueInstance = new Test();
}
}
}
return uniqueInstance;
}
}
说明:
- 如果不进行同步,可能多个线程同时检测到uniqueInstance == null,就会出现取出多个实例的情况。
- 如果用synchronized同步整个getInstance()方法,会将线程中耗时较长,并且不需要同步的代码也锁上,导致效率太低。
- 如果没有第二个if (uniqueInstance == null) 检测,同样可能出现:多个线程同时检测到uniqueInstance == null,从而取出多个实例的情况。
注意:若在static变量前用private修饰,则表示这个变量只能在本类中的静态代码块或者静态成员方法使用,而不能通过类名直接引用。
内部类方式--推荐:
public class Test {
private static class MyObject {
public static Test uniqueInstance = new Test();
}
private Test() {
}
public static Test getInstance() {
return MyObject.uniqueInstance;
}
}
在内部类方式中,使用了一个专门的类来初始化Test。JVM将推迟Test的初始化操作,直到开始使用这个类时才初始化,并且由于通过一个静态初始化来初始化Test,因此不需要额外的同步。 当任何一个线程第一次调用getInstance时,都会使Test被加载和被初始化,此时静态初始化器将执行Test的初始化操作。
static声明代码块
static代码块也叫静态代码块,是在类中独立于类成员的static语句块,可以有多个,位置可以随便放,它不在任何的方法体内,JVM加载类时会自动执行这些静态的代码块,如果static代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次(除初始化静态变量的一些公共处理语句可以放在这里。比如:当一个类需要在被载入时就执行一段程序,这样可以使用静态程序块)。
静态对象的好处
静态变量、静态代码块和静态方法都属于静态对象,我们上面总结了他们的特点,这里说明静态对象的好处:
- 静态对象的数据在全局是唯一的。任何一处地方修改了静态变量的值,在程序所有使用到的地方都将会体现到这些数据的修改。 非静态的东西你修改以后只是修改了他自己的数据,但是不会影响其他同类对象的数据。
- 引用方便。直接用
类名.静态方法名或者类名.静态变量名就可引用并且直接修改其属性值,不用get和set方法。 - 节约空间。静态变量和静态方法属于类,在内存中只有一个复制(所有实例都指向同一个内存地址--方法区)
- 由于静态对象的初始化是在类加载的初始化阶段进行,在实例化对象的构造函数返回时一定已经初始化完成,因此可以用于安全的发布对象,当然对象发布后的安全性要靠其他措施来保证。
坏处:
- 类属性中被static所引用的变量,会被作为GC的root根节点。作为根节点就意味着,这一类变量是基本上不会被回收的。因此,static很容易引入内存泄漏的风险。
static声明内部类
静态内部类是指在一个类的内部,又定义了一个用static修饰的类。它可以不依赖于外部类实例对象而被实例化,但他不能访问外部类的普通成员变量和普通成员方法,只能访问外部类的static成员(包括私有类型)。
一个没有被static修饰的内部类,必须要这么声明。
OutterClass.InnerClass innerClass = new OutterClass().new InnerClass();
如果你使用了static修饰,那么你就可以这样使用内部类。
OutterClass.StaticInnerClass staticInnerClass = new OutterClass.StaticInnerClass();
这两种方式最大的区别就是,第一种方式,如果你想要获得InnerClass的实例,你必须有一个OutterClass的实例,所有其实这种方式你创建了两个实例,所以有两个new关键字。而第二种方式就好理解一些,静态内部类不依赖于外部类的实例存在,因此只需要直接创建内部类的实例就可以了,所以只有一个new关键字。