对于集合,我们并不陌生,用的很多,也会不知不觉中忽略其中的一些细节,比如细节问题,当在大数据情况下的效率问题等。
我主要是针对list和set使用lamada来对集合进行处理的效率比较,同时还对同步和并发进行了验证
代码如下:
1 //根据数字的大小,有不同的结果 2 private static int size = 10000000; 3 4 /** 5 * 测试list 6 */ 7 public static void testList() { 8 List<Integer> list = new ArrayList<>(size); 9 for (Integer i = 0; i < size; i++) { 10 list.add(new Integer(i)); 11 } 12 13 List<Integer> temp1 = new ArrayList<>(size); 14 //老的 15 long start = System.currentTimeMillis(); 16 for (Integer i : list) { 17 temp1.add(i); 18 } 19 System.out.println("old:" + (System.currentTimeMillis() - start)); 20 21 //同步 22 long start1 = System.currentTimeMillis(); 23 list.stream().collect(Collectors.toList()); 24 System.out.println("同步:" + (System.currentTimeMillis() - start1)); 25 26 //并发 27 long start2 = System.currentTimeMillis(); 28 list.parallelStream().collect(Collectors.toList()); 29 System.out.println("并发:" + (System.currentTimeMillis() - start2)); 30 }
针对不同的数据进行了测试
当size=100000时,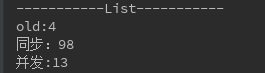
当size=1000000时,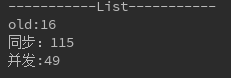
当size=10000000时,
因为本地内存有限,再往大测试会内存溢出,但是我们能看出,list集合 并发 还是比同步快很多,数量级越大差距越大
接下来我们来测试下set的效率
代码如下:
1 //根据数字的大小,有不同的结果 2 private static int size = 100000; 3 4 5 /** 6 * 测试set 7 */ 8 public static void testSet() { 9 List<Integer> list = new ArrayList<>(size); 10 for (Integer i = 0; i < size; i++) { 11 list.add(new Integer(i)); 12 } 13 14 Set<Integer> temp1 = new HashSet<>(size); 15 //老的 16 long start = System.currentTimeMillis(); 17 for (Integer i : list) { 18 temp1.add(i); 19 } 20 System.out.println("old:" + (System.currentTimeMillis() - start)); 21 22 //同步 23 long start1 = System.currentTimeMillis(); 24 list.stream().collect(Collectors.toSet()); 25 System.out.println("同步:" + (System.currentTimeMillis() - start1)); 26 27 //并发 28 long start2 = System.currentTimeMillis(); 29 list.parallelStream().collect(Collectors.toSet()); 30 System.out.println("并发:" + (System.currentTimeMillis() - start2)); 31 }
当size=100000时,
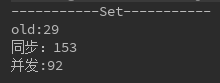
当size=1000000时,
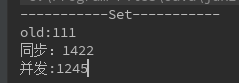
当size=10000000时,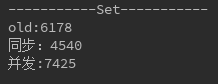
我们会发现,set来说,当超过一定数量级的时候,并发的效率反而低于同步的效率,所以不能盲目认为并发一定高于同步。
总得来说,我们也可以看出来list和set本身特性给他们带来的影响,list是有序且可重复的,而set则是无序且不能重复的,导致并发带来的效率完全不一样。
一次作为经验,用于后续参考使用。