1、配置启动参数
1.1 Linux服务器
1.1.1 启动参数配置
Linux配置部分的内容来自互联网,文章地址
https://blog.csdn.net/weixin_43073775/article/details/111137770
此处只做摘录收集,方便自己查看,原文有详细介绍。可以仔细查看,老手可以掠过。
另一篇很不错的文章:
https://blog.csdn.net/u012550080/article/details/81605189
在启动Linux服务器上启jar包时配置启动参数,参数如下:
java -Djava.rmi.server.hostname=xxx.xxx.xx.xx -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=xxxxx -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -jar my.jar
注:
- 如果有-javaagent参数,把以上参数放到-javaagent之前。
- hostname为服务器运行的ip,指定的服务器端口号要开放。
1.1.2 关闭防火墙。
如果已经关闭可以忽略。
# 查看防火墙是否开启
systemctl status firewalld
# 开启防火墙
systemctl start firewalld
# 关闭防火墙
systemctl stop firewalld
# 永久开放指定某端口
firewall-cmd --zone=public --add-port=80/tcp --permanent
# 命令参数含义:
# -zone:作用域
# -add-port=80/tcp 添加端口,格式:端口/通讯协议
# -permanent 永久生效,没有此参数后重启失效
# 永久禁止访问某端口
firewall-cmd --remove-port=80/tcp --permanent
# 设置开开放/禁止端口后需要重启防火墙
firewall-cmd --reload
# 查看所有开放的端口号
firewall-cmd --list-ports
1.2 IDEA中配置
在下图中圈起来的位置添加配置参数:
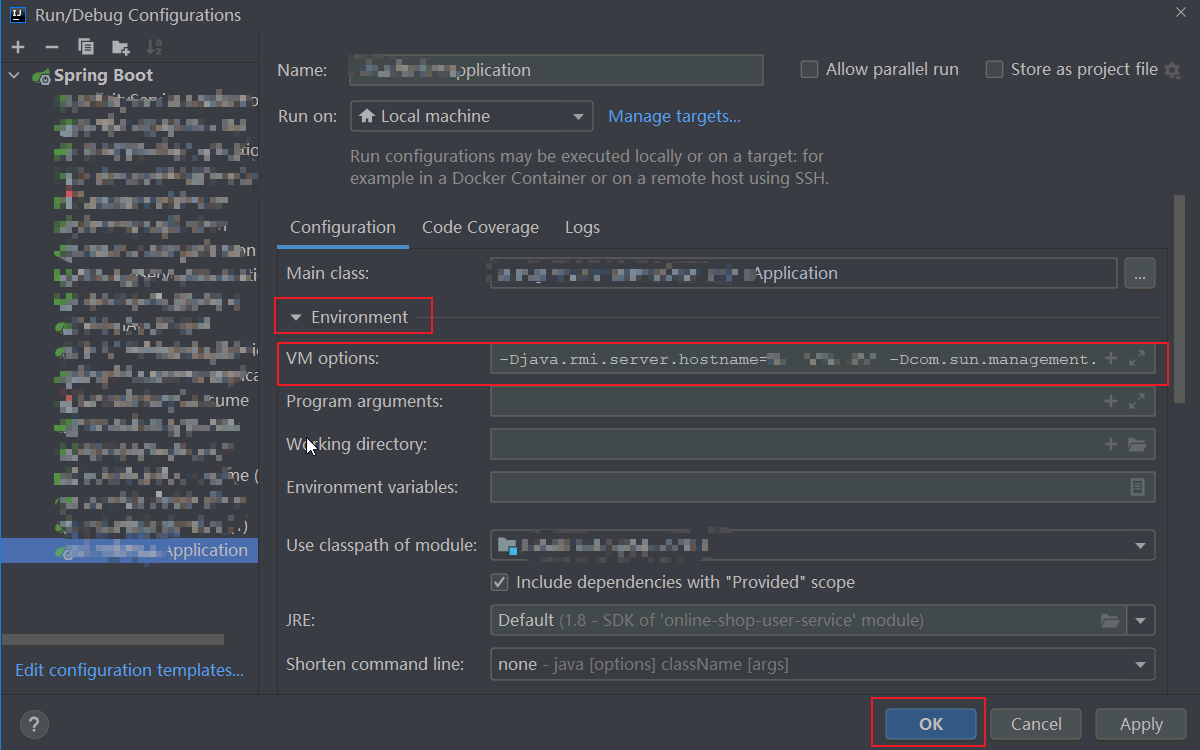
具体参数如下:
-Djava.rmi.server.hostname=10.7.66.181 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=7777 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
注:hostname和port含义同上,不过hostname要填本机的ip。
2. 启动Jvisualvm
这个就只能在windows上进行远程连接了。
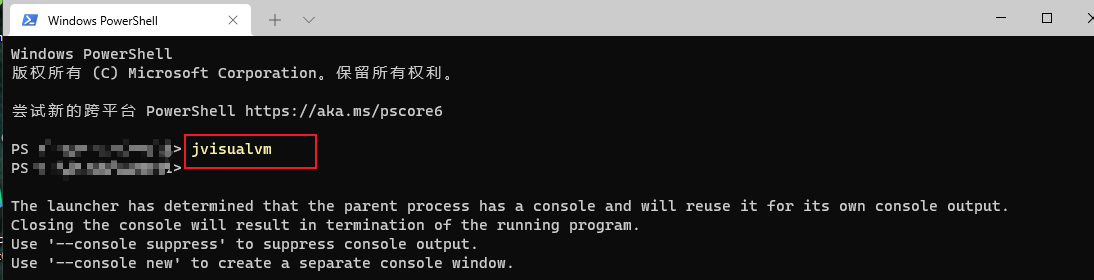
2.1 连接服务器
在Windows的cmd、owershell或Windows terminal上输入【jvisualvm】。(前提是要配置好了jdk的环境变量)。以Windows terminal为例如图:
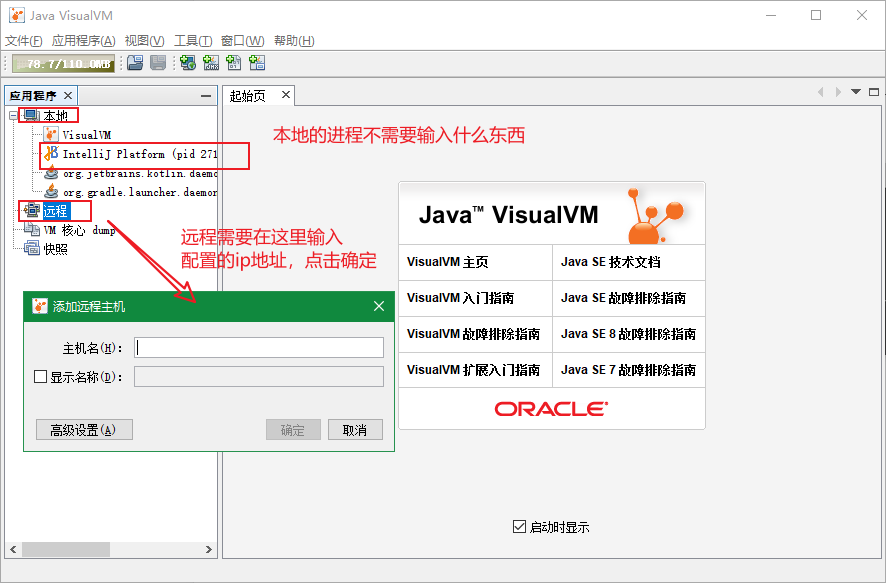

3. 简单使用
双击IDEA的进程,随便点点,切换到监视,发现有CPU、堆、类、线程等图形化信息。此时我的机器正在编译Spring的源码,所以看到图中还是有些许变化。

3.1 概述

这里可以看到一些启动时的JVM参数和系统属性等信息。还可以看到线程Dump数等保存的信息。
3.2 监视
看到的信息如第一张图所示。点击堆Dump按钮会将当前堆的情况转储成dump文件。如下图所示:

这里可以看到有个名为【ApplicationImpl pooled thread 649】线程正在运行,线程id是【3073】,线程状态是【TIMED_WAITING】。还可以看到线程详细的堆栈信息。至于后面的【类】和【实例】等选项卡我就不太清楚,点进去看也没发现啥。后面再继续探索。
3.3 线程
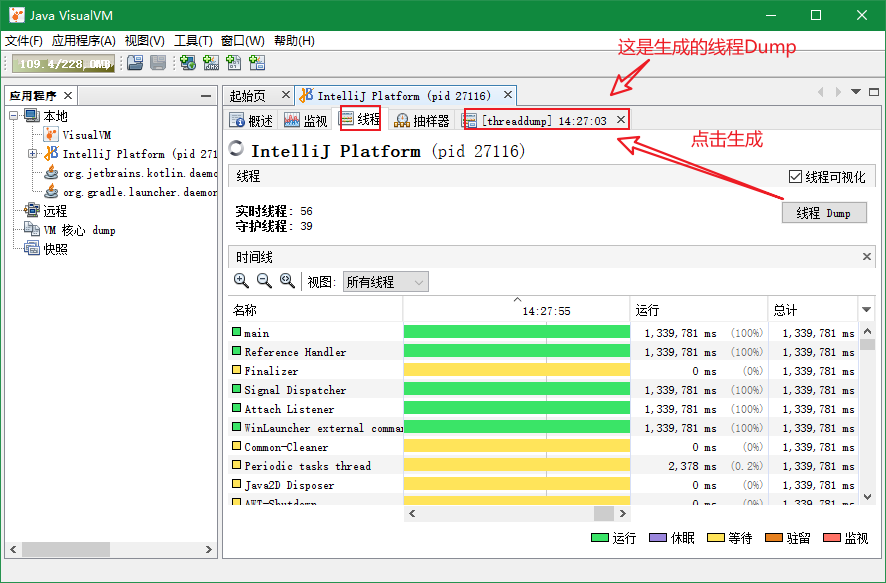
线程选项卡就可以显示当前进程下正在运行的线程。可以根据颜色来分辨各个线程的状态。点击右上角的【线程Dump】按钮可以生成最后一个选项卡【threaddump】的文件,和刚刚的【heapdump】文件一样,都是在某一时刻的【快照】,记录了这个时刻的堆和线程的信息。具体如下图:
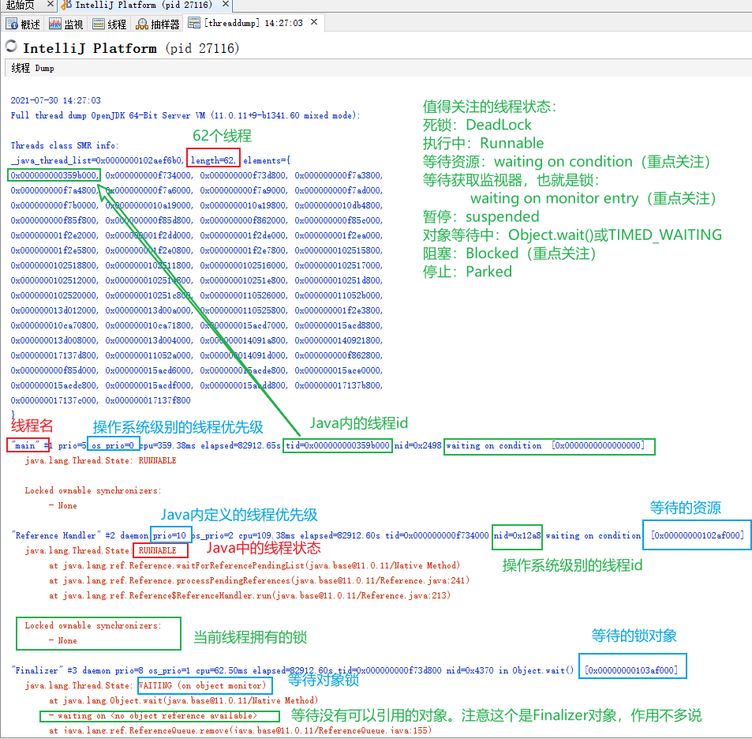
还有很多东西我也不知道是什么,知识和经验尚浅。
3.4 抽样器
利用抽样器对CPU进行抽样。可以点击【热点方法】进行排序,也就是会被JIT优化的方法。也可以点击创建【快照】。

切换到线程CPU时间,可以看到使用cpu时间最长的线程名称。也可以点击【增量】将目前的【总量】统计模式切换成增量统计模式。

点击内存抽样,可以看到差不多的内容。切换到【每个线程分配】可以看到线程【已分配的内存总字节数】统计,同样可以切换增量。右边还可以执行GC和堆dump。

硬核内容我太菜了,我写不来:
笔者才疏学浅,这个笔记到这儿就结束了。接下来就可以自己写死锁代码、堆内存溢出代码、栈溢出代码、多线程代码等进行内存分析啦。也可以分析线上跑的服务的内存了。