(以下所有文件:点此链接
里面还有安装的视频教学,我这里是亲测了一次,如有报错请看红色部分。实践高于理论啊兄弟们!!)
CentOS6.4版本:
一.安装CentOS 6.4 在VMWare虚拟机上,我设置的用户是hadoop,密码是hadoop;
二.安装完成后以root用户进入,密码还是之前设的密码hadoop。
配置网络:右键右上角符号,

Edit Connections

选择Edit

要想填这个,打开windows的命令行(直接win+R,输入cmd),输入ipconfig,查看无线局域网适配器的iPv4地址,子网掩码和默认网关,并填写到虚拟机的相对应位置(注意,ipv4的地址不能一样,最好改的就差一位就好),并虚拟机的DNS servers 输入8.8.8.8,8.8.4.4,Search domains输入4.4.4.4:(输入完后点击Apply,再点击close就可以了)
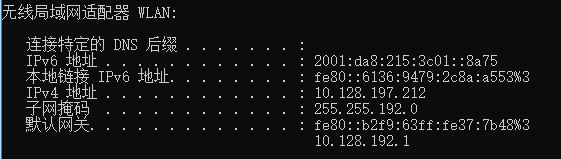

完成后桌面右键open int terminal,输入service network restart,显示下图时就完成了

打开Windows的命令行,输入ping (之前填的ipv4地址),ping通就成功了。

P.S.注意,关于网络配置这一部分,每次换一个网络环境就要重来一次,因为ipv4的地址会随着你的网络环境而变换。
error:我”service network restart“这里没成功:

解决方式:在terminal中输入以下命令行:

你会看见一直出现RTNETLINK answers: File exists。不用管他,输入service network restart,就成功了。
error:我又没ping通。。
1.设置虚拟机为桥接模式
VM -> Settings -> Network Adapter: Bridged
2.配置虚拟机的ip等信息
修改ip: gedit /etc/sysconfig/network-scripts/ifcfg-eth0 # Advanced Micro Devices [AMD] 79c970 [PCnet32 LANCE] DEVICE=eth0 BOOTPROTO=static IPADDR=10.128.192.213 (主机ip:10.128.192.212) NETMASK=255.255.192.0 (子网掩码同主机) GATEWAY=10.128.192.1 (网关同主机) BROADCAST=192.168.16.113 HWADDR=00:0C:29:C9:0A:84 ONBOOT=yes 重启服务 /etc/init.d/network restart 关闭Linux防火墙 chkconfig iptables off 关闭虚拟机的selinux: gedit /etc/selinux/config //把SELINUX=enforcing改为SELINUX=disabled 关闭windows防火墙(控制面板里) 关闭所有windows的杀毒软件(如果所有配置都做了,仍然不通,把杀毒软件关了试试)
三.后面的过程我们用一个工具,SecureCRT来完成。
连接过程如下图:

连接以后需要输入密码。
后面是一系列的命令行:
关闭防火墙:service iptables stop chkconfig iptables off vim /etc/selinux/config //把SELINUX=enforcing改为SELINUX=disabled ,需要输入时按i,退出保存是先按esc按钮,然后:wq! 修改主机名:vim /etc/sysconfig/network //把HOSTNAME改为hadoop 修改映射关系:vim /etc/hosts //添加一行 10.128.197.213 hadoop(注意,中间不是一个空格,是一个tab) 重启机器:reboot (这里重启完了以后虚拟机会重启,再从虚拟机登录进去后再用secureCRT连接)
P.S.有一个编译器叫gedit,如果是桌面安装的话可以直接用 gedit xxxx 命令,可以直接在文本上进行修改
P.S.这里重启后出错了,解决:点此链接
配置ssh:
ssh-keygen -t rsa //四个回车键 ssh-copy-id 10.128.197.213 ssh 10.128.197.213 //此时不需要输入密码说明配置成功
CentOS7版本:
1.安装CentOS7
这里需要注意一下,和6.4版本不同,中间会有需要选择的地方。可以选择在安装过程中配置好网络,安装源。软件选择默认是最小安装,即不安装桌面环境。如果要安装桌面需要选择gnome桌面。
后面部分不分centos版本:
配置jdk:创建文件夹(这个步骤实际上可以直接在虚拟机上手动完成,不一定要输入命令行): cd /home rm -r hadoop //删除home下的hadoop文件夹 mkdir softwares //创建软件文件夹 mkdir data //创建数据文件夹 mkdir tools //创建放包的文件夹(注意,这三个文件夹都是在home目录下的) rpm -qa|grep jdk //查看系统是否自带jdk rpm -qa|grep java //还是在查看系统是否自带java yum install -y lrzsz //安装一个上传下载的插件(实际上这个没必要,直接从Windows里拖拽进去就好了,或者安装一个软件WinSCP
tar -zxf jdk-8u151-linux-x64.tar.gz -C ../software //将jdk的包解压到software文件夹中
//顺便说一句,jdk的包真的很长,自己打特别不科学,你先写一个jdk然后按tab键就可以全部出来!!!很方便的有木有亲~ cd /home/software/jdk1.8.0_151/ //进入jdk安装路径 pwd //找到安装路径,复制 vim /etc/profile //打开这个文件夹,加入:(注意啊,这两行后面部分千万不要加空格,否则就会报bash: export: `=': not a valid identifier 这个错)
export JAVA_HOME=/home/software/jdk1.8.0_151
export HADOOP_HOME=/home/software/hadoop-2.6.5 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
source /etc/profile //保存执行
java -version //检查是否java安装成功,下面出现版本号就是安装成功了
sudo权限配置:给hadoop用户也添加权限(注意,我此时还是root权限,如果不是root权限输入命令行 su,切换至root权限)
chmod u+w /etc/sudoers //添加文件的写权限 vim /etc/sudoers
 (中间是tab不是空格)
(中间是tab不是空格)
至此,hadoop的前置环境就配完了,接下来我们配hadoop环境。
打开Hadoop官网:http://hadoop.apache.org/,按照下面两个图片,进入Hadoop 2.6.5 的伪分布式安装配置中(注意,如果你要自己下载hadoop的安装包,请安装tar.gz结尾的那个,那个是有配置的,而不是src.tar.gz结尾的,无配置版本还要配置,时间花费很多)

同样,解压包到software里 tar -zxf /home/tools/hadoop-2.6.5.tar.gz -C /home/software/ tar -zxf /home/tools/protobuf-2.5.0.tar.gz -C /home/software/ tar -zxf /home/tools/apache-maven-3.0.5-bin.tar.gz -C /home/software/ tar -zxf /home/tools/findbugs-1.3.9.tar.gz -C /home/software/
配置maven,findbugs环境路径:类似于上面的jdk配置,记得source重置,查看完成与否:mvn -v,findbugs -version

配置protobuf:
进入protobuf下: cd /home/software/protobuf-2.5.0/ ./configure
安装依赖: yum -y install autoconf automake libtool cmake ncurses-devel openssl-devel lzo-devel zlib-devel gcc gcc-c++
再进入protobuf,重新configure一下
./configure
make install
error:使用yum时报错:Cannot find a valid baseurl for repo
解决方式:Cannot find a valid baseurl for repo: base
我在这篇博文里详细写了各种网搜的解决方法
下面就是配置Hadoop的各种配置文件了,这里推荐一个工具,notepad++,添加一个插件NppFTP.dll,远程连接虚拟机。安装包:点此链接
使用方法:点击上排最右边的按钮

右边出现工具栏

选择Profile settings,填写内容(自己的配置):

点击连接:

如果连接不上,一种可能是没联网,一种可能是网络变动换ip地址了,虚拟机终端ifconfig查看IP地址
进入hadoop的安装目录,首先是etc/hadoop/hadoop-env.sh
export JAVA_HOME=/home/software/jdk1.8.0_151
然后是etc/hadoop/core-site.xml:(创建文件夹/home/software/hadoop-2.6.5/data/tmp)
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/software/hadoop-2.6.5/data/tmp</value> </property> </configuration>
etc/hadoop/hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
etc/hadoop/mapred-site.xml:(文件夹下原名mapred-site.xml.template,把名字改一下)
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
etc/hadoop/yarn-site.xml:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
进入hadoop安装目录:
bin/hdfs namenode -format sbin/start-dfs.sh sbin/start-yarn.sh
输入命令行jps,查看几个运行(正常有6个)

如果不用hadoop,关闭进程:
sbin/stop-dfs.sh sbin/stop-yarn.sh
error:bash: jps: command not found
解决:
cd vim .bash_profile 里面path地方改成: PATH=$PATH:$HOME/bin:/home/software/jdk1.8.0_151/bin source .bash_profile
P.S.Linux中含有两个重要的文件 /etc/profile和.bash_profile 每当系统登陆时都要读取这两个文件,用来初始化系统所用到的变量,其中/etc/profile是超级用户所用,.bash_profile是每个用户自己独立的,我们可以修改该文件来设置一些变量。
实际上后来一直还是打不开,我也不知道为什么,总是找不到jps。两种方法,第一种就是找不到就source .bash_profile,第二种是进入jdk的安装目录,进入bin文件夹,打开终端,运行./jps。亲测可用。
至此,CentOS6.4下Hadoop 2.6.5的所有配置就完毕了。
error:后来改了配置以后,nodemanager消失了,这是改了配置以后会出现的问题。那么先stop两个sh,再重新format了以后再start就ok了。