多核编程
大纲
- pthread库
- 各种锁
- 杂谈
- 原子操作
- 锁无关数据结构
pthread库
类型
- pthread_t
- pthread_attr_t
- pthread_mutex_t pthread_mutexattr_t
- pthread_cond_t pthread_condattr_t
- pthread_key_t
- pthread_once_t
- pthread_rwlock_t pthread_rwlockattr_t
- pthread_spinlock_t
- pthread_barrier_t pthread_barrierattr_t
创建线程
- pthread_create
- 线程函数: void _thread_func(void){ while(1){/code here/} }
#include <stdio.h> #include <stdlib.h> #include <pthread.h> #include <unistd.h> #include <string.h> void printids(const char *s) { pid_t pid; pthread_t tid; pid = getpid(); tid = pthread_self(); printf("%s pid %u tid %u (0x%x) ",s,(unsigned int) pid, (unsigned int) tid,(unsigned int) tid); } void *thr_fn(void *arg) { printids("new thread: "); return NULL; } int main(void) { int err; pthread_t ntid; err = pthread_create(&ntid,NULL,thr_fn,NULL); if (err != 0) printf("can't create thread: %s ",strerror(err)); printids("main thread:"); pthread_join(ntid,NULL); return EXIT_SUCCESS; }
线程join
- 主线程调用join,等待子线程执行结束pthread_join,pthread_tryjoin_np, pthread_timedjoin_np
- 调用pthread_detach的线程无法被join
在任何一个时间点上,线程是可结合的(joinable)或者是分离的(detached)。一个可结合的线程能够被其他线程收回其资源和杀死。在被其他线程回收之前,它的存储器资源(例如栈)是不释放的。相反,一个分离的线程是不能被其他线程回收或杀死的,它的存储器资源在它终止时由系统自动释放。
CPU时间片
- pthread_yield放弃线程剩余的时间片
- sched_yield放弃进程剩余的时间片
线程属性
- pthread_attr_init pthread_attr_destroy pthread_getattr_np
- pthread_attr_getdetachstate pthread_attr_setdetachstate //detach
- pthread_attr_getguardsize pthread_attr_setguardsize //各线程堆栈之间的保护区域,4KB
- pthread_attr_getschedparam pthread_attr_setschedparam //设置线程调度策略
- pthread_attr_getschedpolicy pthread_attr_setschedpolicy //设置线程优先级
- pthread_attr_getinheritsched pthread_attr_setinheritsched //设置继承的调度属性(子线程)
- pthread_attr_getscope pthread_attr_setscope //设置竞争作用域(系统级还是进程级)
- pthread_attr_getstackaddr pthread_attr_setstackaddr //已废弃
- pthread_attr_getstacksize pthread_attr_setstacksize //设置堆栈大小
- pthread_attr_setaffinity_np pthread_attr_getaffinity_np //设置CPU亲缘性
pthread_once
- 在多个线程中,初始化函数只会被执行一次
#include<stdio.h> #include<pthread.h> pthread_once_t once=PTHREAD_ONCE_INIT; void run(void) { printf("Function run is running in thread %u ",(unsigned int)pthread_self()); } void *thread1(void *arg) { pthread_t thid=pthread_self(); printf("current thread's ID is %u ",(unsigned int) thid); pthread_once(&once,run); printf("thread1 ends "); } void *thread2(void *arg) { pthread_t thid=pthread_self(); printf("current thread's ID is %u ",(unsigned int) thid); pthread_once(&once,run); printf("thread2 ends "); } int main() { pthread_t thid1,thid2; pthread_create(&thid1,NULL,thread1,NULL); pthread_create(&thid2,NULL,thread2,NULL); sleep(3); printf("main thread exit! "); return 0; } // gcc once.c -o once -lpthread /* current thread's ID is 3582207744 Function run is running in thread 3582207744 thread1 ends current thread's ID is 3573815040 thread2 ends main thread exit! */
线程的私有数据
- int pthread_key_create(pthread_key_t key,void (destructor)(void*));
- int pthread_setspecific(pthread_key_t key,const void *value);
- void *pthread_getspecific (pthread_key_t __key)
- int pthread_key_delete(pthread_key_t key);
在多线程程序中,所有线程共享程序中的变量。现在有一全局变量,所有线程都可以使用它,改变它的值。而如果每个线程希望能单独拥有它,那么就需要使用线程存储了。表面上看起来这是一个全局变量,所有线程都可以使用它,而它的值在每一个线程中又是单独存储的。这就是线程存储的意义。
各种锁
基本概念
- 死锁
死锁发生在两个线程相互持有对方正在等待的东西(实际是两个线程共享的东西)
T1 lock A T1 lock B T2 lock B T2 lock A - 活锁
活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,失败,尝试,失败。事物1可以使用资源,但它让其他事物先使用资源;事物2可以使用资源,但它也让其他事物先使用资源,于是两者一直谦让,都无法使用资源。
- 饿死
事务T1封锁了数据R,事务T2又请求封锁R,于是T2等待。T3也请求封锁R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求。。。。。。T2可能永远等待。
- 优先级反转
优先级反转是指一个低优先级的任务持有一个被高优先级任务所需要的共享资源。高优先任务由于因资源缺乏而处于受阻状态,一直等到低优先级任务释放资源为止。而低优先级获得的CPU时间少,如果此时有优先级处于两者之间的任务,并且不需要那个共享资源,则该中优先级的任务反而超过这两个任务而获得CPU时间。如果高优先级等待资源时不是阻塞等待,而是忙循环,则可能永远无法获得资源,因为此时低优先级进程无法与高优先级进程争夺CPU时间,从而无法执行,进而无法释放资源,造成的后果就是高优先级任务无法获得资源而继续推进。
互斥锁
- pthread_mutex_init pthread_mutex_destroy
- pthread_mutex_trylock pthread_mutex_lock pthread_mutex_timedlock pthread_mutex_unlock
- pthread_mutex_getprioceiling pthread_mutex_setprioceiling //当一个线程拥有互斥量时,它将以指定的优先级运行。
自旋锁
- pthread_spin_init pthread_spin_destroy
- pthread_spin_lock pthread_spin_trylock pthread_spin_unlock
- 不会导致进程切换
- 会导致CPU利用率升高
- 适合小代码段
读写锁
- pthread_rwlock_init pthread_rwlock_destroy
- pthread_rwlock_rdlock pthread_rwlock_tryrdlock pthread_rwlock_timedrdlock
//加读锁 - pthread_rwlock_wrlock pthread_rwlock_trywrlock pthread_rwlock_timedwrlock
//加写锁 - pthread_rwlock_unlock
- pthread_rwlockattr_init pthread_rwlockattr_destroy
- pthread_rwlockattr_getpshared pthread_rwlockattr_setpshared //父子进程间的共享
- pthread_rwlockattr_getkind_np pthread_rwlockattr_setkind_np //读优先还是写优先
- 同一时间只能有一个writer
- 可以同时有多个reader
栅栏
- pthread_barrier_init pthread_barrier_destroy pthread_barrier_wait
- pthread_barrierattr_init pthread_barrierattr_destroy
- pthread_barrierattr_getpshared pthread_barrierattr_setpshared
- 线程执行到栅栏处停下,等到所有线程都执行到栅栏处,再一起继续执行
- 可用于线程池的初始化
条件变量
- 适合于生产者消费者模型
- 条件变量必须和mutex一起使用
//thread1 : while(1) { pthread_mutex_lock(&mutex); iCount++; pthread_mutex_unlock(&mutex); pthread_mutex_lock(&mutex); if(iCount >= 100) { pthread_cond_signal(&cond); } pthread_mutex_unlock(&mutex); } //thread2: while(1) { pthread_mutex_lock(&mutex); while(iCount < 100) { pthread_cond_wait(&cond,&mutex); } printf("iCount >= 100 "); iCount = 0; pthread_mutex_unlock(&mutex); }注意两点:
1) 在thread_cond_wait()之前,必须先lock相关联的mutex,因为假如目标条件未满足,pthread_cond_wait()实际上会unlock该mutex,然后block,在目标条件满足后再重新lock该mutex,然后返回。
2) 为什么是while(sum<100),而不是if(sum<100) ?这是因为在pthread_cond_signal()和pthread_cond_wait()返回之间,有时间差,假设在这个时间差内,还有另外一个线程t4又把sum减少到100以下了,那么t3在pthread_cond_wait()返回之后,显然应该再检查一遍sum的大小。这就是用 while的用意
信号量
- 适用于生产者消费者模型
- 可用于进程间通讯
- 同互斥锁的区别
有A,B两个线程,B线程要等A线程完成某一任务以后再进行自己下面的步骤,这个任务并不一定是锁定某一资源,还可以是进行一些计算或者数据处理之类。而线程互斥量则是“锁住某一资源”的概念,在锁定期间内,其他线程无法对被保护的数据进行操作。
- 信号量,互斥锁,条件变量的区别。http://www。cnblogs。com/lonelycatcher/archive/2011/12/20/2294161。html
互斥锁<读写锁<自旋锁<读写自旋锁<锁无关数据结构(原子操作)
伪共享
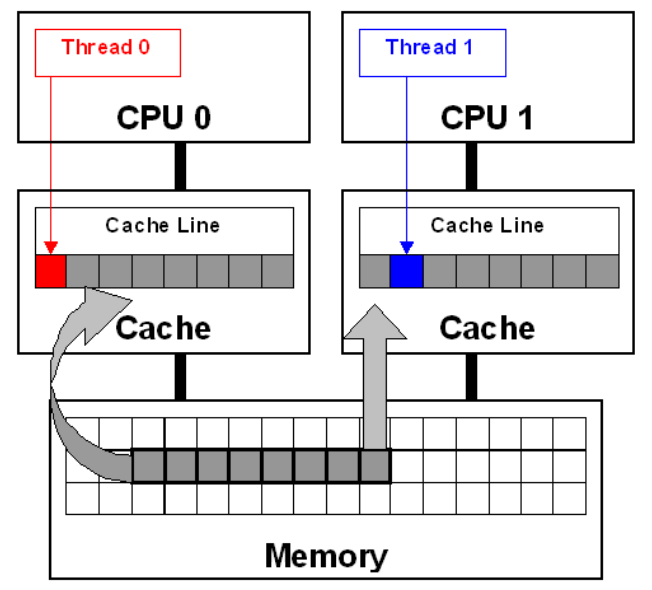
* 查看cache line: cat /proc/cpuinfo | grep cache_alignment
#include <stdio.h>
#include <sys/time.h>
#include <pthread.h>
// #define PACK __attribute__ ((packed))
typedef int cache_line_int __attribute__((aligned(LEVEL1_DCACHE_LINESIZE)));// 指定字节对齐
typedef struct data_t
{
cache_line_int a;
cache_line_int b;
}data;
/*
typedef struct data_t
{
int a;
int b;
}data;
*/
#define MAX_NUM 500000000
inline unsigned long now_ms()
{
struct timeval tv;
gettimeofday(&tv,NULL);
return (tv.tv_sec * 1000 + tv.tv_usec / 1000);
}
void* thread_func_1(void* param)
{
unsigned long start = now_ms();
data* d = (data*)param;
int i=0;
for (; i<MAX_NUM; ++i)
{
++d->a;
}
unsigned long end = now_ms();
printf("thread 1,time=%lums
",end-start);
return NULL;
}
void* thread_func_2(void* param)
{
unsigned long start = now_ms();
data* d = (data*)param;
int i=0;
for (; i<MAX_NUM; ++i)
{
++d->b;
}
unsigned long end = now_ms();
printf("thread 2,time=%lums
",end-start);
return NULL;
}
int main()
{
data d = {a:0,b:0};
pthread_t t1,t2;
pthread_create(&t1,NULL,thread_func_1,&d);
pthread_create(&t2,NULL,thread_func_2,&d);
pthread_join(t1,NULL);
pthread_join(t2,NULL);
printf("end,a=%d,b=%d
",d.a,d.b);
return 0;
}
/*
g++ -o test_false_sharing_2 test_false_sharing_2.cpp -g -Wall -lpthread -DLEVEL1_DCACHE_LINESIZE=`getconf LEVEL1_DCACHE_LINESIZE`
gcc -o false_share main.c -lpthread -DLEVEL1_DCACHE_LINESIZE=`getconf LEVEL1_DCACHE_LINESIZE`
*/
/*
thread 1,time=1531ms
thread 2,time=1531ms
end,a=500000000,b=500000000
*/
volatile
当一个变量定义成volatile之后,它将具备两种特性:第一是保证此变量对所有线程的可见性,这里的“可见性”是指当一条线程修改了这个变量的值,新值对于其它线程是可以立即得知的,变量值在线程间传递均需要通过主内存来完成,如:线程A修改一个普通变量的值,然后向主内存进行回写,另外一条线程B在线程A回写完成了之后再从主内存进行读取操作,新变量的值才会对线程B可见。
使用volatile变量的第二个语义是禁止指令重排序优化,普通的变量仅仅会保证在该方法的执行过程中所有依赖赋值结果的地方能获取到正确的结果,而不能保证变量的赋值操作的顺序与程序代码中的执行顺序一致。因为在一个线程的方法执行过程中无法感知到这一点,这也就是Java内存模型中描述的所谓的”线程内表现为串行的语义“(Within-Thread As-If-Serial Sematics)。
- 正确使用 volatile 的模式
要始终牢记使用 volatile 的限制 只有在状态真正独立于程序内其他内容时才能使用 volatile 这条规则能够避免将这些模式扩展到不安全的用例。- 状态标志
volatile boolean shutdownRequested; 。。。 public void shutdown() { shutdownRequested = true; } public void doWork() { while (!shutdownRequested) { // do stuff } }
- 状态标志
内存屏障
内存屏障是为应付内存访问操作的乱序执行而生的。 那么,内存访问为什么会乱序呢? 这里先简要介绍一下:
* 乱序
现在的CPU一般采用流水线来执行指令。一个指令的执行被分成:取指,译码,访存,执行,写回,等若干个阶段。指令流水线并不是串行化的,并不会因为一个耗时很长的指令在”执行”阶段呆很长时间,而导致后续的指令都卡在”执行”之前的阶段上。
相反,流水线中的多个指令是可以同时处于一个阶段的,只要CPU内部相应的处理部件未被
占满。比如说CPU有一个加法器和一个除法器,那么一条加法指令和一条除法指令就可能同
时处于”执行”阶段,而两条加法指令在”执行”阶段就只能串行工作。
这样一来,乱序可能就产生了。比如一条加法指令出现在一条除法指令的后面,但是由于除法的执行时间很长,在它执行完之前,加法可能先执行完了。再比如两条访存指令,可能由于第二条指令命中了cache(或其他原因)而导致它先于第一条指令完成。
一般情况下,指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终乱序执行完成。这就是所谓的 “顺序流入,乱序流出” 。
指令流水线除了在资源不足的情况下会卡住之外(如前所述的一个加法器应付两条加法指令),指令之间的相关性才是导致流水线阻塞的主要原因。
下文中也会多次提到,CPU的乱序执行并不是任意的乱序,而必须保证上下文依赖逻辑的正
确性。 比如: a++; b=f(a); 由于b=f(a)这条指令依赖于第一条指令(a++)的执行结果,所以b=f(a)将在”执行”阶段之前被阻塞,直到a++的执行结果被生成出来。
如果两条像这样有依赖关系的指令挨得很近,后一条指令必定会因为等待前一条执行的结果,而在流水线中阻塞很久。而编译器的乱序,作为编译优化的一种手段,则试图通过指令重排将这样的两条指令拉开距离,以至于后一条指令执行的时候前一条指令结果已经得到了,那么也就不再需要阻塞等待了。
由于指令执行存在这样的乱序,那么自然,由指令执行而引发的内存访问势必也可能乱序。
- 内存屏障(__sync_synchronize())
正如上面所说,无关的内存操作会被按随机顺序有效的得到执行,但是在CPU与CPU交互时或CPU与IO设备交互时,这可能会成为问题。我们需要一些手段来干预编译器和CPU,使其限制指令顺序。
内存屏障就是这样的干预手段。他们能保证处于内存屏障两边的内存操作满足部分有序。 (这里”部分有序”的意思是,内存屏障之前的操作都会先于屏障之后的操作,但是如果
几个操作出现在屏障的同一边,则不保证它们的顺序。)
原子操作
- 原子操作的本质:总线锁
在x86 平台上, CPU提供了在指令执行期间对总线加锁的手段。 CPU芯片上有一
条引线#HLOCK pin,如果汇编语言的程序中在一条指令前面加上前缀”LOCK”
,经过汇编以后的机器代码就使CPU在执行这条指令的时候把#HLOCK pin的电
位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的
CPU就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中的原子
性。
LOCK是一个指令的描述符,表示后续的指令在执行的时候,在内存总线上加锁
。总线锁会导致其他几个核在一定时钟周期内无法访问内存。虽然总线锁会影
响其他核的性能,但比起操作系统级别的锁,已经轻量太多了。
#lock是锁FSB(前端串行总线, front serial bus), FSB是处理器和RAM之间的总线
,锁住了它,就能阻止其他处理器或者core从RAM获取数据。 - GCC内置函数
- 返回原值并操作
type __sync_fetch_and_add (type ptr, type value); // i++
type __sync_fetch_and_sub (type ptr, type value); // i–
type __sync_fetch_and_or (type ptr, type value); // or
type __sync_fetch_and_and (type ptr, type value); // and
type __sync_fetch_and_xor (type ptr, type value); // xor
type __sync_fetch_and_nand (type ptr, type value); // not and, not (a and b) - 操作并返回操作后的值
type __sync_add_and_fetch (type ptr, type value); // ++i
type __sync_sub_and_fetch (type ptr, type value); //–i
type __sync_or_and_fetch (type ptr, type value); // or
type __sync_and_and_fetch (type ptr, type value); // and
type __sync_xor_and_fetch (type ptr, type value); // xor
type __sync_nand_and_fetch (type ptr, type value); // not and - 指针的原子操作
type __sync_lock_test_and_set (type ptr, type value); // 将ptr设为value并返回ptr操作之前的值。
void __sync_lock_release (type ptr); // 将ptr置0 - CAS
bool __sync_bool_compare_and_swap (type ptr, type oldval, type newval)
if (ptr==oldval){ptr=newval; return true;}
else {return false;}
type __sync_val_compare_and_swap (type ptr, type oldval, type newval)
if (ptr==oldval){ptr=newval;}
return oldvale;
- 返回原值并操作
- ABA problem