由于个人在JMeter 3.0的实际应用中,脚本中的Test Plan/Sampler等元件命名都没有使用中文,所以在之前介绍Dashboard Report特性的博客(原文戳这里))成文时,没有提到关于中文的问题。之后有朋友反馈,Sampler名称为中文时,生成的报告中展示为乱码,自己测试,确实如此。
如图,脚本包含两个命名为中文的Sampler:
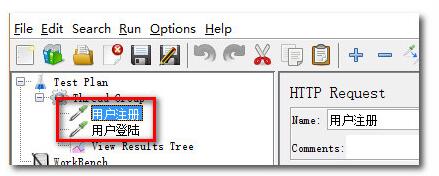
执行测试后,生成的Dashboard Report图表中文乱码:
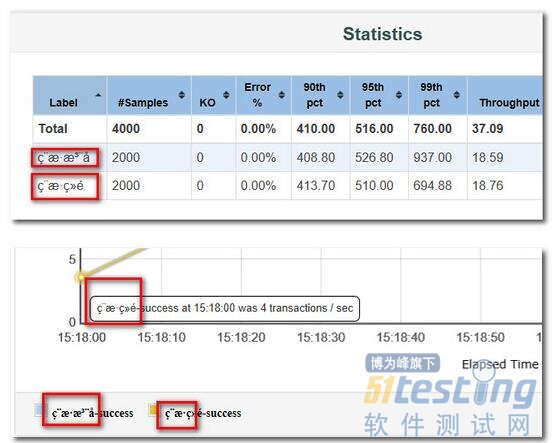
于是通过查看官方文档和源码,找到原因并进行了解决,原打算直接追加到之前那篇文章,但考虑到篇幅过长,于是决定新成一文,然后在之前的文章中补充链接。
二. 解决方案
先上解决方案:修改JMeter report模块读取数据源码中的字符集设置为UTF-8,编译后替换到 JMETER_HOMElibextApacheJMeter_core.jar 内,这里会分享一个我处理好的一个jar包,但建议自己亲自动手:
基础方案
1、在官网 下载页面 下载 apache-jmeter-3.0_src.zip
2、相关源码位置:
apache-jmeter-3.0/src/core/org/apache/jmeter/report/core/CsvSampleReader.java
3、将 CsvSampleReader 的 CHARST 赋值为 UTF-8
private static final String CHARSET = StandardCharsets.UTF_8.displayName();
4、编译该文件,用得到的 .class 文件替换 JMETER_HOMElibextApacheJMeter_core.jar 内的原文件。当然也可以直接对源码重新编译打包,但会比较费时。
效果如图:
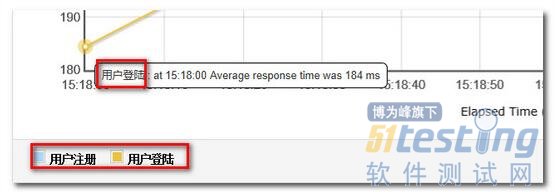
推荐方案
关于设置字符编码,一个更推荐的方案是设置默认字符编码为UTF-8,同时支持.properties配置项。JMeter读写结果文件(xml/csv)的字符编码配置项是 ./bin/saveservice.properties 文件内的 _file_encoding ,由 org.apache.jmeter.save.SaveService.getFileEncoding(String dflt) 读取,当没有在配置相中指定时,将使用方法的入参作为默认编码,这里我们传入UFT-8作为默认格式,因此将基础方案中的步骤3做如下变更:
private static final String CHARSET = SaveService.getFileEncoding(StandardCharsets.UTF_8.displayName());
编译后替换即可。saveservice.properties文件的_file_encoding默认已配置为UTF-8,多数情况下,我们不需要修改。
文件分享
分享的文件和jar包是使用推荐方案进行处理。可以取用class文件自己替换进本地的ApacheJMeter_core.jar,也可以直接下载分享的jar包替换本地对应jar包。
· 单独的CsvSampleReader.class文件: https://pan.baidu.com/s/1bo10QnX ,提取码 ee68
· 处理完毕的ApacheJMeter_core.jar: https://pan.baidu.com/s/1mhKLwgw ,提取码 id7h
注:github上可以看到jmeter的trunk分支已经将dashboard report的默认字符编码更改为UFT-8,本文的推荐方案即是官方更新中的实现方式。只是目前官方还没有发布更新,所以自己动手。
三. 成因分析
Dashboard Report特性生成HTML图表,使用JMeter记录测试结果数据的文件 (命令行执行时 -l 指定的文件,也可在图形界面的监听器中指定,作为基础知识不在这里展开) 作为数据源,Apache FreeMarker作为模板引擎,默认的模板位于JMETER_HOMEin
eport-template。
· 查看官方说明,确认没有关于HTML报告字符编码的配置项。
· 查看数据源文件,确定文件格式为UTF-8,文件中的中文正常可读,排除数据源存在问题的可能。
· 查看生成的结果文件,主要数据在 指定路径/content/js/graph.js ,任选一个图表数据,查看其标签的值(“label”:” * “),显示为乱码,排除js解析成乱码的可能。
· 此时首先想到Java文件读取过程问题,从官方发布的源码包查看源码 src/core/org/apache/jmeter/report/core/CsvSampleReader ,发现代码中字符编码指定为ISO8859-1:
|
package org.apache.jmeter.report.core;
//次要内容略...
public class CsvSampleReader implements Closeable{
//次要内容略...
private static final String CHARSET = "ISO8859-1";
//次要内容略...
private CsvSampleReader(File inputFile, SampleMetadata metadata, char separator, boolean useSaveSampleCfg) {
if (!(inputFile.isFile() && inputFile.canRead())) {
throw new IllegalArgumentException(inputFile.getAbsolutePath()
+ " does not exist or is not readable");
}
this.file = inputFile;
try {
this.reader = new BufferedReader(new InputStreamReader(
new FileInputStream(file), CHARSET), BUF_SIZE);
} catch (FileNotFoundException | UnsupportedEncodingException ex) {
throw new SampleException("Could not create file reader !", ex);
}
}
}
|
至此,问题原因得以确定。