问题现象
文件a的内容如下:

查看第3行到第5行的内容:sed -n '3,5p' /tmp/test/a

可见在命令行执行,是没有问题的。
在python中使用paramiko模块执行linux命令,主要代码如下:
def toServer(self, str): sys.setdefaultencoding('utf-8') return str.decode('utf-8').encode('GB18030') def fromServer(self, str): sys.setdefaultencoding('GB18030') return str.decode('GB18030') def executeCmd(self, cmd, isErr=False): cmd = self.toServer(cmd) print 'exec_command:%s' % cmd stdin, stdout, stderr = self.ssh.exec_command(cmd) out = stdout.read() out = self.fromServer(out) out = out[:len(out) - 1] if isErr == True: err = stderr.read() err = self.fromServer(err) err = err[:len(err) - 1] return out, err else: return out
执行:
print sa.executeCmd('''sed -n '3,5p' /tmp/test/a''')
输出:
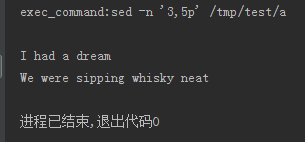
可见,输出第2行时(文件的第3行)是空的!
分析
打断点
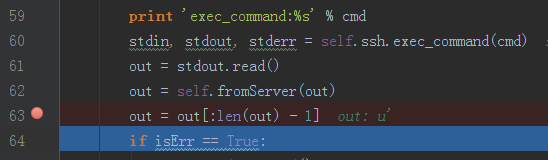
查看out完整的值:
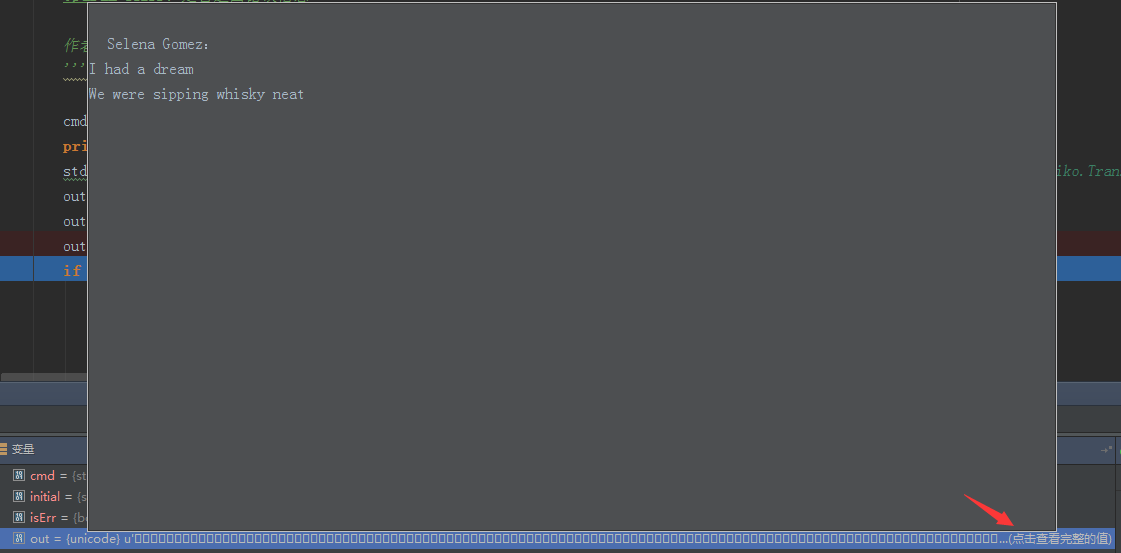
可以看到“Selena Gomez:”这一行其实是已经获取到了,但是可以看到前面有空格和空行,不禁让人怀疑这中间是否包含什么特殊的字符。
使用vi查看a文件的内容:发现里面包含了大量的^@字符!

^@是一个特殊字符,通过ctrl+V ctrl+@可以敲出来。
在实际使用中,是检查日志的时候发现的这个问题。这里只是用歌词代替日志。
首先备份日志:cat log >> log.bak
然后清空日志:echo "" > log
之后再让程序写入日志(log文件),然后再去检查这个日志文件。
发现程序每次写入日志时,前面会有大量的^@字符。原因有可能是程序写入日志的代码有问题。
解决
在vi末行模式下输入:冒号%s/^@//g
注意:是通过ctrl+V ctrl+@敲出来。
这是目前为止我所知道的从文件上把字符去掉,但是如果是做成自动化去获取日志,手动去操作就不现实了。
目前的解决办法是:传入一个字符串,并查找这个字符串的位置,然后从这个位置开始截取
def executeCmd(self, cmd, isErr=False, initial='nope'): cmd = self.toServer(cmd) print 'exec_command:%s' % cmd stdin, stdout, stderr = self.ssh.exec_command(cmd) out = stdout.read() out = self.fromServer(out) if initial != 'nope': # 截取正文,过滤特殊字符^@ startPosition = out.find(initial) out = out[startPosition:len(out) - 1] else: out = out[:len(out) - 1] if isErr == True: err = stderr.read() err = self.fromServer(err) err = err[:len(err) - 1] return out, err else: return out
执行:
print sa.executeCmd('''sed -n '3,5p' /tmp/test/a''',initial='Selena')
输出:

因为实际使用过程中,每次去获取日志都是最新的日志(经过了备份和清空),所以包含^@符号只有一段,而且是在第一行内容的前面,所以这种方法适用。
如果要获取的日志包含多段^@符号,就不适用。
如果你有更好的方法,欢迎分享。