在学习决策树类的算法时,总是绕不开 信息熵、Gini指数和它们相关联的概念,概念不清楚,就很难理解决策树的构造过程,现在把这些概念捋一捋。
信息熵
信息熵,简称熵,用来衡量随机变量的不确定性大小,熵越大,说明随机变量的不确定性越大。计算公式如下:
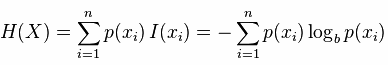
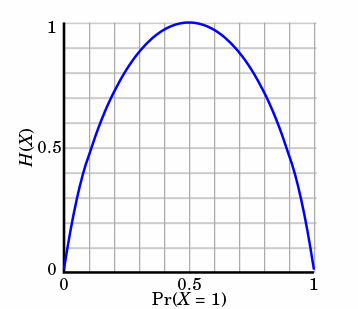
考虑二元分布的情况,当取2为对数底时,可以得到如下的函数曲线。可以看到,当p=0.5时,不确定性最大,熵的值是1,也最大,当p=0或1时,没有不确定性,熵的值最小,是0。
条件熵
我们在分析某个特征对随机变量的影响时,需要计算条件熵,即随机变量Y的信息熵相对特征X的条件期望,公式如下:

互信息
互信息,也叫信息增益,是熵和条件熵的差值,g(Y,X) = H(Y) - H(Y|X)。
信息增益的含义是,某一个特征会使得随机变量的不确定性下降多少。下降的越多,说明这个特征与标签的相关性越强,分类效果自然越好。在构造决策树时,常用的做法是选择信息增益更大的特征构造分支。
另外,在构造决策树时,信息增益有两种算法,一是差值(ID3),二是比值(C4.5),比值是差值与特征的信息熵的比例,公式如下所示:

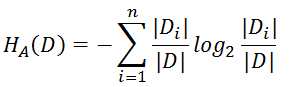
比值比差值能更准确的反应不确定性变化的程度,原因是,如果按差值选取节点,那些取值数量更多的特征总是会排在前面,在比值的计算公式中,分母可以度量特征的取值数量,相当于对各个特征做了归一化,所以不会出现,特征取值数量多,信息增益一定更大的情况。
Gini指数
Gini指数和熵类似,都是衡量随机变量不确定程度的,计算公式是:
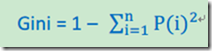
Gini指数有一个比较直观的解释:从样本中任意挑选两个,两个样本属于不同类别的概率就是Gini指数。从Gini指数的定义和解释就可以发现,它和熵和类似,不确定性越大,Gini指数和熵也越大。不同点在于Gini指数的最大值是0.5,不是1。把Gini指数公式和信息熵公式都变换成求和的形式,可以发现二者只相差一个乘积项,Gini指数是 1-p,信息熵是-log(p),就是这么一点点差别。
Gini指数的另一种说法是不纯度(impurity),Gini指数越大,不确定性越大,数据越混乱,不纯度越高。
笔者没研究过信息熵和Gini指数的发迹史,但可以猜测,Gini指数和信息熵很可能是不同领域的研究者分别建立的评价不确定性的指标,从含义上看,二者殊途同归。在实际使用时,往往用Gini指数来构造CART。