Union-Find算法

如图所示,输入4、3就将4、3两个节点连接起来,如果4和3相连,3和8相连,那么4和8也是相连的,通过输入这样大量的整数对,获取保存大量的信息之后再判断两个节点是否相连,这样的问题被称为动态连通性问题。
这里的整数对我们称为连接,单个对象被称为触点,多个连接起来的对象称为等价类,也被称为连接分量简称分量。所以两个触点是否相连,就可以根据他们是否处于同一分量来进行判断。
- union-find算法完整代码
public class UF { //分量id int[] id; //分量个数 int count; public UF(int N){ //初始化N个触点 id = new int[N]; count = N; //初始化id数组 for (int i = 0; i < N; i++){ id[i] = i; } } //返回连通分量的数目 public int count(){ return count; } //判断pq是否在同一分量 public Boolean connected(int p, int q){ return find(p) == find(q); } //返回p所在的的分量标识符 public int find(int p){ return id[p]; } //在pq之间添加一条连接 public void union(int p, int q){ int pID = find(p); int qID = find(q); //如果已经是同一分量不需要采取任何行动 if (pID == qID) return; // 遍历一次,将p分量名修改为q for(int i = 0; i < id.length; i++){ if(id[i] == pID){ id[i] = qID; } } count--; } }
这里创建了一个名为ID的数组,作为基础的数据结构来表示所有的分量,同时使用分量中的某一个触点的名称作为分量的标识符。一开始我们有N个触点,所以有N个分量,然后将id[i]的值初始化为i,count将记录分量的数目,union将使两个触点连接起来,find将返回触点所在分量的标识符,connected将判断两个触点是否存在于同一个分量。
//返回p所在的的分量标识符 public int find(int p){ return id[p]; } //在pq之间添加一条连接 public void union(int p, int q){ int pID = find(p); int qID = find(q); //如果已经是同一分量不需要采取任何行动 if (pID == qID) return; // 遍历一次,将p分量名修改为q for(int i = 0; i < id.length; i++){ if(id[i] == pID){ id[i] = qID; } } count--; }
这里在查找p的标识符时直接使用p作为索引,union方法中将所有标识符和p一样的全修改成了q的标识符。所以其实如果要添加m个连接,时间复杂度将是m*n。
问题有一点就是为什么不直接把q触点的标识符修改为p的标识符呢,这样时间复杂度就会降低很多昂,这个一会再说,先看看如何优化这个m*n的时间复杂度。
//返回p所在的的分量标识符 public int find(int p){ while (p != id[p]) p = id[p]; return p; } //在pq之间添加一条连接 public void union(int p, int q){ int pROOT = find(p); int qROOT = find(q); //如果已经是同一分量不需要采取任何行动 if (pROOT == qROOT) return; //修改根节点 id[pROOT] = qROOT; count--; }
这样修改将p所在分量的根节点的标识符直接修改为q触点所在分量的根节点的标识符。其实这里和上面说的问题看起来好像是一样的,区别就是这样是对的,上面所提的那个解决方法是错误的,因为如果q或者p是已经处在一个已经有很多节点的分量中的时候,只修改p或者q的标识符是将p或者q移到了q或者p所在的分量,没有实现连接两个分量的功能。
至于find方法的修改,这样的写法解释其实就是分量将使用分量的某一触点的名称作为分量的标识符,所以标识符和索引相等的自然就是分量的标识符。
然后其实上面两个方法谁块谁慢其实还是不一定的,假设我们输入的整数对是有序的,0-1、0-2、0-3等,那么我们的find操作的时间复杂度会越来越高也会变成n,最后还将是m*n。
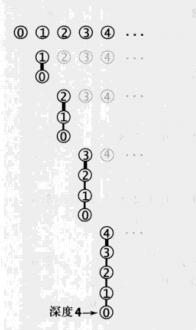
为了解决这样的问题,我们可以进行加权处理,像上面这种总是将大的一个树连接到小的树上就会使树的深度越来越大,所以我们应该将小的树连接到大树上。把连接方式修改为下面这种。
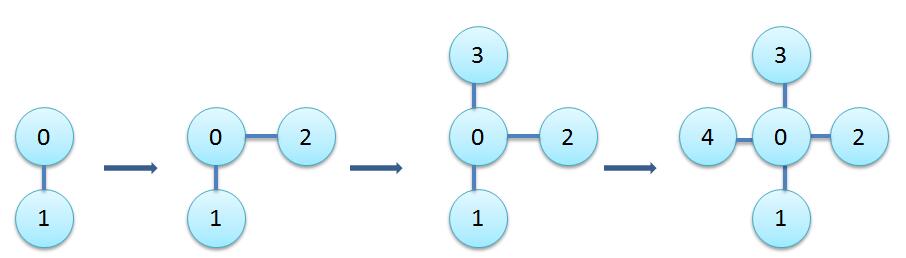
代码:
public class UF { //分量id int[] id; //分量个数 int count; //权重 int[] size; public UF(int N){ //初始化N个触点 id = new int[N]; size = new int[N]; count = N; //初始化id数组 for (int i = 0; i < N; i++){ id[i] = i; size[i] = 1; } } //返回连通分量的数目 public int count(){ return count; } //判断pq是否在同一分量 public Boolean connected(int p, int q){ return find(p) == find(q); } //返回p所在的的分量标识符 public int find(int p){ while (p != id[p]) p = id[p]; return p; } //在pq之间添加一条连接 public void union(int p, int q){ int pROOT = find(p); int qROOT = find(q); //如果已经是同一分量不需要采取任何行动 if (pROOT == qROOT) return; //将小树的根节点连接到大树的根节点 if(size[p] < size[q]){ id[pROOT] = qROOT; size[q] += size[p];} else{ id[qROOT] = pROOT; size[p] += size[q]; } count--; } }