DataSet简介
- Dataset的演变流程:SchemaRDD->DataFrame->DataSet
- DataSet的操作方式和DataFrame几乎没有区别,它是spark1.6出现的
- DataSet是Strong type
为什么官方要推出DataSet?
如一个sql: selec a from table ,selec是错误语法,a是错误列名,正对这种情况,不同的API的运行时异常发现时间完全不一样。
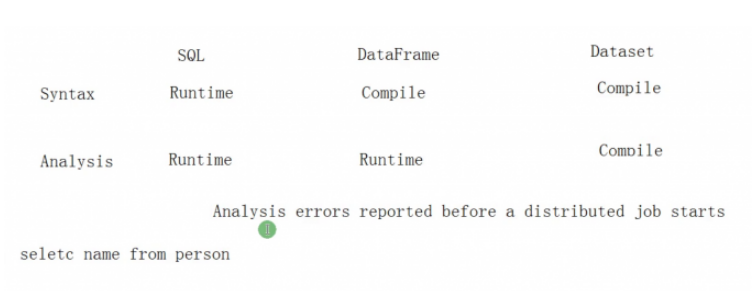
DatSet的出现是为了让运行时错误(如列名错误)在编译时就能发现,这样就不会进行作业提交以及资源的申请。
DS与DF编程对比
scala> case class People(name: String, salary: String) defined class People scala> val ds = spark.read.format("JSON").load("/user/hadoop/examples/src/main/resources/employees.json").as[People] ds: org.apache.spark.sql.Dataset[People] = [name: string, salary: bigint] scala> ds.select("name").show() //这种方式和DF完全一致的 +-------+ | name| +-------+ |Michael| | Andy| | Justin| | Berta| +-------+
scala> ds.map(_.name).show() //这才是ds的正确使用方式,分析在编译时就进行检查了
+-------+
| value|
+-------+
|Michael|
| Andy|
| Justin|
| Berta|
+-------+
扩展1:scala中转义字符是"",如"|" 分割的字符串,则需要转义为"|"
扩展2:RDD的map是RDD,但是DataFrame的map是DataSet