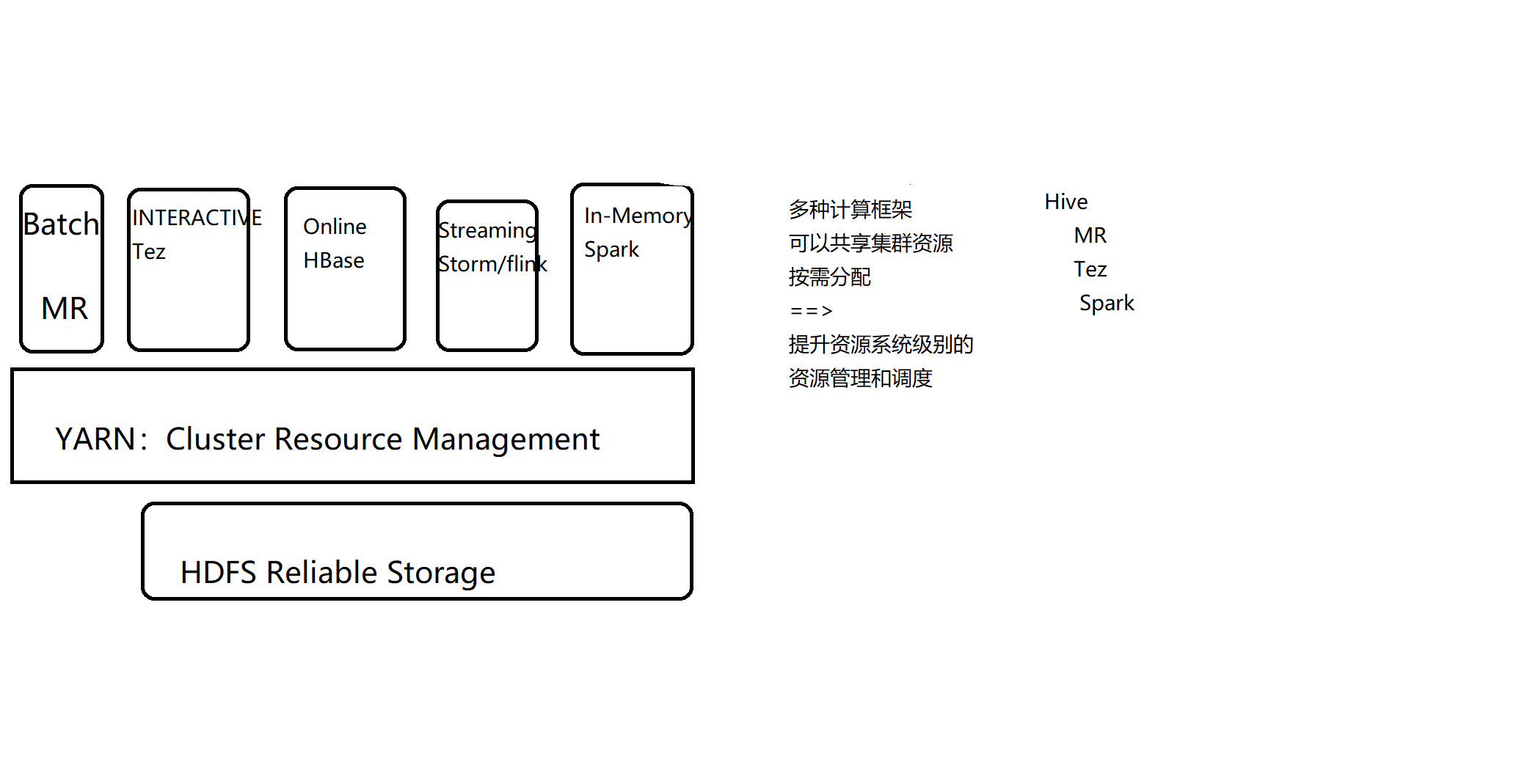
Yarn产生的背景
- 在没有YARN之前,是一个集群一个计算框架。比如:Hadoop一个集群、Spark一个集群、HBase一个集群等,造成各个集群管理复杂,资源的利用率很低;比如:在某个时间段内Hadoop集群忙而Spark集群闲着,反之亦然,各个集群之间不能共享资源造成集群间资源并不能充分利用;
- yarn的出现将所有的计算框架运行在一个集群中,共享一个集群的资源,按需分配;Hadoop需要资源就将资源分配给Hadoop,Spark需要资源就将资源分配给Spark,进而整个集群中的资源利用率就高于多个小集群的资源利用率;
- 随着数据量的暴增,跨集群间的数据移动不仅需要花费更长的时间,且硬件成本也会大大增加;而共享集群模式可让多种框架共享数据和硬件资源,将大大减少数据移动带来的成本;
- 生产中spark作业几乎都是跑在yarn上,不用Standalone,因为集群中可能有MR、Spark、MPI等各类作业,若跑在各自的资源调度框架上,那么整体集群的资源利用率肯定是有问题的。
- 为了统一作业调度以及资源管理,yarn就诞生了,当前YARN能支持所有主流作业的资源管理和作业调度(batch、交互式、online、strem、in-memory、机器学习、图计算等框架),它是一个操作系统级别的资源管理和调度框架
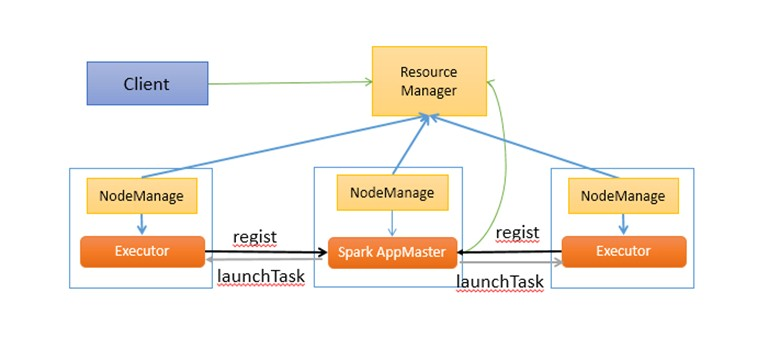
- Yarn的组成:RM,NM,AM,Container
- Yarn的架构流程
- 客户端提交作业
- RM在相应的NM上拿到第一个Container,并启动AM
- AM启动以后就会向RM注册自己
- 注册以后就会向ResourceSchedule采用轮询的方式申请资源
- AM申请到资源以后,就会与相应的NM通信,要求启动task
- NM接到通信以后就会获取Container启动Task
- Container们会有规律的向AM汇报自己的进行情况,Container的启动是由NodeManager启动,Container要向Nodemanage汇报资源信息,Container要向App Mstr汇报计算信息。
- 作业完成以后,AM会向ApplicationsManager注销自己

Spark on Yarn概述
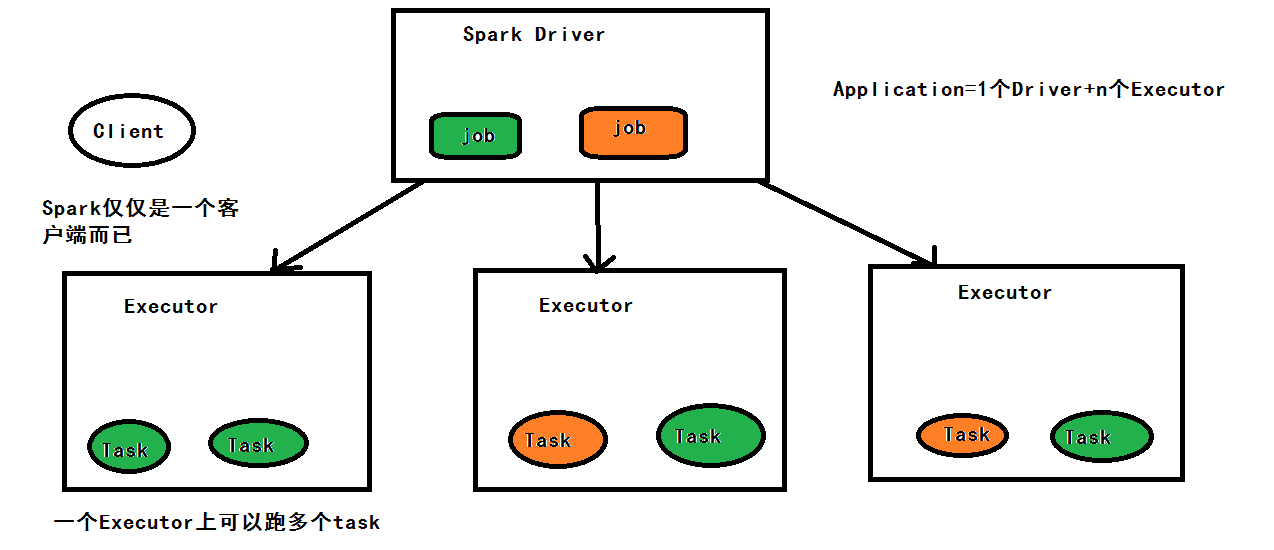
- Spark on yarn模式下,spark仅仅是一个客户端而已,生产中只需要在有gateway权限机器上直接解压部署spark即可。
- MR:在MR作业中每个MAP和REDUCE的task都是一个进程,当task完成后该进程就会注销,任务基于进程,频繁开启进程关闭进程,降低速度
- Spark:Spark中一个Excutor进程会跑多个task,该进程会在整个Application的生命周期存活,即使没有作业运行,任务基于线程,内部是线程池,没有启动和关闭的开销,速度很快
- Cluster manager:spark作业启动时driver program会通CM去向Local、Standaone、YARN、Mesos、K8s等资源调度器申请资源,故向哪些资源调度申请的模块不一定是pluggable(可插拔)。
- YARN Application:使用yarn框架进行的计算作业,第一启动的容器一定跑的是AM
- Worker node:spark 作业运行在yarn环境下是没有Worker node概念,因为spark的executer运行在container内(故container的memory和vcore配置一定要大于executer的设置)
基于Yarn的Spark架构与作业执行流程
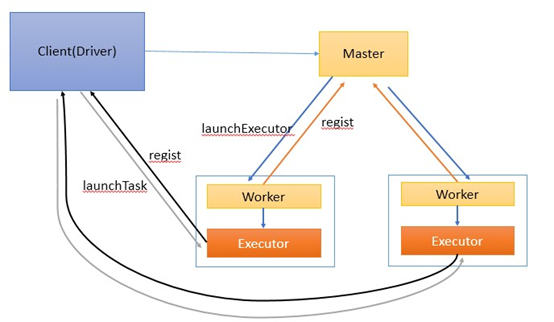
基于standalone的Spark架构与作业执行流程
Standalone模式下,集群启动时包括Master与Worker,其中Master负责接收客户端提交的作业,管理Worker。提供了Web展示集群与作业信息。
名词解释:
1. Standalone模式下存在的角色。
- Client:客户端进程,负责提交作业到Master。
- Master:Standalone模式中主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
- Worker:Standalone模式中slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
- Driver: 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
- Executor:即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
2.作业相关的名词解释
- Stage:一个Spark作业一般包含一到多个Stage。
- Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。
- DAGScheduler: 实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
- TaskScheduler:实现Task分配到Executor上执行。
提交作业有两种方式,分别是Driver(作业的master,负责作业的解析、生成stage并调度task到,包含DAGScheduler)运行在Worker上,Driver运行在客户端。接下来分别介绍两种方式的作业运行原理。
Driver运行在Worker上
通过org.apache.spark.deploy.Client类执行作业,作业运行命令如下:
./bin/spark-class org.apache.spark.deploy.Client launch spark://host:port file:///jar_url org.apache.spark.examples.SparkPi spark://host:port
作业执行流如图1所示。

作业执行流程描述:
-
客户端提交作业给Master
-
Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。
-
另外Master还会让其余Worker启动Exeuctor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
-
ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序,生成执行计划,并调度执行。对于每个stage的task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报的时候把TaskScheduler中的task调度到ExecutorBackend执行。
-
所有stage都完成后作业结束。
Driver运行在客户端
直接执行Spark作业,作业运行命令如下(示例):
./bin/run-example org.apache.spark.examples.SparkPi spark://host:port
作业执行流如图2所示。
作业执行流程描述:
-
客户端启动后直接运行用户程序,启动Driver相关的工作:DAGScheduler和BlockManagerMaster等。
-
客户端的Driver向Master注册。
-
Master还会让Worker启动Exeuctor。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
-
ExecutorBackend启动后会向Driver的SchedulerBackend注册。Driver的DAGScheduler解析作业并生成相应的Stage,每个Stage包含的Task通过TaskScheduler分配给Executor执行。
- 所有stage都完成后作业结束。
转载参考博客:https://www.cnblogs.com/shenh062326/p/3658543.html