SparkCore算子简介
SparkCore中的算子可以分为2类:Transformations Operation 和 Action Operation
在Spark的提交过程中,会将RDD及作用于其上的一系列算子(即:RDD及其之间的依赖关系)构建成一个DAG有向无环视图。当遇到action算子的时候就会触发一个job的提交,而Driver程序 则会将触发的job提交给DAGScheduler,由DAGSchedule将job构建成一张DAG
因此,action类算子就是spark application程序分为job的依据,也就是触发job提交的决定性因素
Spark的RDD空间
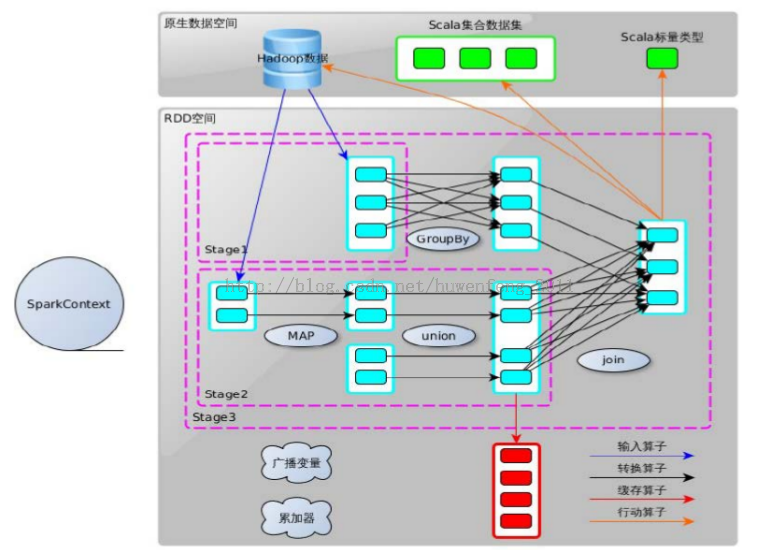
- Stage:
stage是对job的划分,遇到shuffle就划分,一个stage有多个tasks,同一个job间的stage具有依赖关系,前者必须结束才能进行后者的计算。

- RDD的创建
(1)通过集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用的流程

(2) 使用本地文件创建RDD ,在本地临时性地处理一些存储了大量数据的文件

(3)HDFS文件创建RDD,主要用于测试大量数据
其实本地创建RDD和HDFS文件创建RDD是一样的,只是在路径上,要指明是HDFS
hdfs://spark1:9000/data.txt
scala> val linesLength = sc.textFile("hdfs://spark1:9000/rdd.txt").map(line => line.length).reduce(_+_) linesLength: Int = 9
-
常用的算子
| 算子 | 描述 |
| collect() | 无参,以数组的形式返回RDD中的所有的元素:本质上:是将executor中运算得到的RDD--->拉取到Driver程序中来,形成Scala的集合 |
| take(n) | 返回RDD中的前n个元素,无参时,默认为前10个 |
| takeOrdered(n, [ordering]) | 和top类似,先排序(升序/降序),再取前n,不过获取的元素的顺序与top相反 |
| takeSample(withReplacement, num, [seed]) | 返回一个随机采样数组,该数组由从RDD中采样获得,可以选择是否用随机数来替换不足的部分,seed用于指定随机数生成器的种子 |
| first() | 返回RDD的第一个元素(并不一定是最大的,看RDD是否排序,类似于take(1)) |
| top(n) | 返回由RDD前n个最大的元素构成的数组(最大:元素具备可比性,默认取字典顺序最大的) |
| reduce(func) | 通过func函数来聚集RDD中的所有元素,且要求func必须满足:1.可交换;2.可并联。 |
| reduceByKeyLocally(func:(V, V)=>V) | 功能与reduceByKey相同,以key为组进行聚合,但是 唯一不同的是:该算子返回的是一个Map[K, V]的集合 |
| sum() | 只能作用于纯数值形式的RDD,返回元素的总和 |
| count() | 无参,()可以省略,返回RDD的元素个数 |
| countByValue() | 无参,针对于任意类型的RDD,统计RDD中各种元素值及其出现的次数,返回Map[value,count]集合 |
| countByKey() | 无参,针对于PairRDD,返回每种Key对应的元素的个数,返回Map[key, count]形式的Map集合 |
| 算子 | 描述 |
| foreach(func) | 针对于RDD中的每一个元素,运行func进行更新 func 的没有返回值(Unit) |
| foreachPartition(func) | 以Partition为单位进行遍历,遍历每个分区。foreachPartition(func: Iterator[T]=>Unit): Unit |
| 算子 | 描述 |
| saveAsTextFile(path) | 将RDD数据集中的元素,以textFile的格式保存到HDFS或者其他文件系统中去。对于每个元素,Spark程序都会调用toString()方法,将元素转换为文本格式 |
| saveAsSequenceFile(path) | 将数据集的元素以Hadoop SequenceFile的格式保存到指定的目录中,可以使用HDFS或者其他Hadoop支持的文件系统 |
| saveAsObjectFile(path) | 用于将RDD中的元素序列化为对象,存储于磁盘中。对于HDFS,默认采用SequenceFile的格式存储 |
-
collect算子

collect(): 收集数据,将RDD转换为Scala的 Array数组 * 本质上:是将executor中运算得到的RDD--->拉取到Driver程序中来,形成Scala的集合
-
take 算子

* take(n): 获取 RDD的前n个元素 * ---返回前n个元素组成的数组,而不是返回新的RDD(属于Action类的算子)
-
first 算子

first(): 返回RDD的第一个元素(Scala变量),== take(1) * 并不会排序(区别于top())
-
top 算子

top(n):取 RDD的最大的前 n个元素,返回Array集合,属于action算子; * * 1) 当为普通单值RDD时:按照元素值的字典顺序,取最大的前n个; * * 2) 当为PairRDD时:先按照key值进行降序排序,当KEY值相同时,再按照value降序排序, * 最后取最大的前N个;
-
count算子

* count():统计 RDD的元素个数!
-
countByKey 算子:

* countByKey(): 针对于PairRDD,按照key统计每一种 key的元素的个数 * 统计的是每一种 key的数量(与value无关)
-
countByValue()

* countByValue(): 针对于各种RDD,统计其中每一种唯一的元素 的出现次数!! * 此处的value指的是RDD的元素,并不是k,v中的value; * 与是PairRDD、还是普通单值RDD无关! * ---返回Map集合,属于action类算子
-
foreach 算子
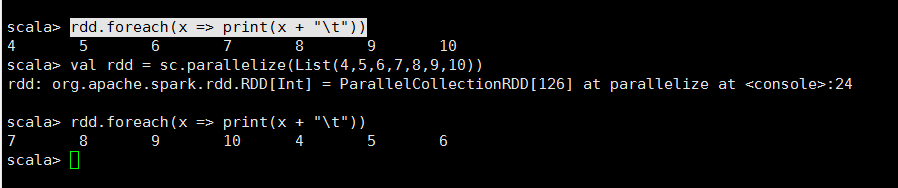
* foreach(func): 用于遍历 RDD,将函数func应用于每一个元素。 * -- 无返回值(不会返回新的RDD,也不会返回scala集合) * func必须为没有返回值的方法(返回值为 Unit类型)
-
foreachPartition 算子
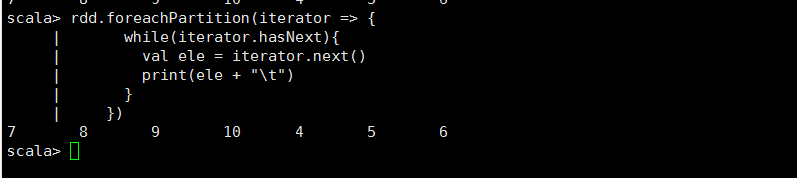
/** * foreachPartition():func中的參數iterator包含了一个分区中的所有元素构成的迭代器; * ---与foreach的效果类似,但是能够以分区为单位进行处理,对于多数场景的处理效率要高! */
wc案例演示
scala> val file = sc.textFile("/home/hadoop/data/ruozedata.txt").collect file: Array[String] = Array(word ruoze jepson, xiaohai ruoze word, dashu xiaohai jepson, xiaoshiqi) scala> val file = sc.textFile("/home/hadoop/data/ruozedata.txt").flatMap(_.split(" ")).collect file: Array[String] = Array(word, ruoze, jepson, xiaohai, ruoze, word, dashu, xiaohai, jepson, xiaoshiqi) scala> val file = sc.textFile("/home/hadoop/data/ruozedata.txt").flatMap(_.split(" ")).map((_,1)).collect file: Array[(String, Int)] = Array((word,1), (ruoze,1), (jepson,1), (xiaohai,1), (ruoze,1), (word,1), (dashu,1),
(xiaohai,1), (jepson,1), (xiaoshiqi,1)) scala> val file = sc.textFile("/home/hadoop/data/ruozedata.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect file: Array[(String, Int)] = Array((word,2), (jepson,2), (ruoze,2), (xiaohai,2), (xiaoshiqi,1), (dashu,1))
scala>val file = sc.textFile("/home/hadoop/data/ruozedata.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).
sortBy(_._2,false).collect
scala> file
res0: Array[(String, Int)] = Array((word,2), (jepson,2), (ruoze,2), (xiaohai,2), (xiaoshiqi,1), (dashu,1))
下一节出常用Transiformation算子
参考博客:https://blog.csdn.net/qq_16759443/article/details/82801332