上一篇介绍了一下Logstash的数据处理过程以及一些基本的配置功能,同时也提到了Logstash作为一个数据采集端,支持对接多种输入数据源,其中就包括Kafka。那么这次的学习不妨研究一下Logstash如何接收Kafka输入的数据,并与日志中的数据进行统一的处理。
首先在Logstash的配置文件中配置Kafka的数据源(因为篇幅原因,Kafka和ZooKeeper的安装部署就不做介绍了):
input { file { path => "D:/logstash-7.14.1/test-log/test.log" start_position => beginning } kafka { bootstrap_servers => "localhost:9092" topics => "test_topic" } }
如上方所示,我们在上一篇的配置文件中追加了Kafka的地址以及主题用来订阅与消费,input插件中kafka项的详细信息也如上一篇所说,可以在官网上进行查看,https://www.elastic.co/guide/en/logstash/current/plugins-inputs-kafka.html#plugins-inputs-kafka-topics
接下来需要一个生产者往Kafka推送数据以供Logstash端采集,那么新增一个Kafka的测试工程来实现,代码如下:
String server = "127.0.0.1:9092"; String topic = "test_topic"; Properties props = new Properties(); props.put("bootstrap.servers", server); props.put("transactional.id", "my-transactional-id"); KafkaCallback callback = new KafkaCallback(); Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer()); producer.initTransactions(); try { producer.beginTransaction(); for (int i = 0; i < 5; i++) { producer.send(new ProducerRecord<String, String>("test_topic", Integer.toString(i), "093124." + (597 + i) + "[0][28412]:[5]FindResponseByPage[fund_account=900010328]"), callback); } producer.commitTransaction(); } catch (KafkaException e) { producer.abortTransaction(); } producer.close();
回调类KafkaCallback的代码也贴一下,主要就是接收一下应答并打印分配的偏移量以及存储的分区信息:
public class KafkaCallback implements Callback { public void onCompletion(RecordMetadata metadata, Exception e) { if (e != null) e.printStackTrace(); SimpleDateFormat df = new SimpleDateFormat("HH:mm:ss.SSS"); System.out.println("[" + df.format(new Date()) + "]partition: " + metadata.partition() + ", offset: " + metadata.offset()); } }
启动Logstash后也把Kafka的生产者小程序给run起来:
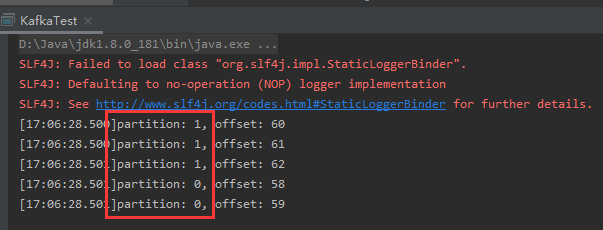
看到消息已经成功推送到Kafka,那么再看下Logstash是否成功收到:
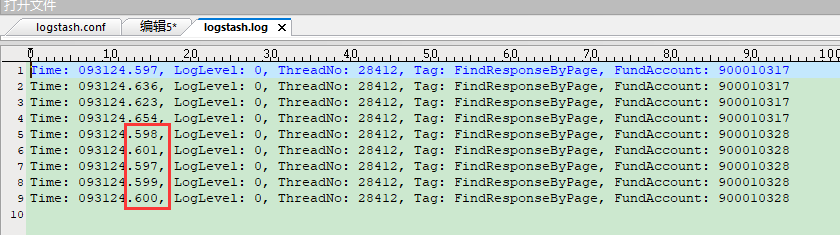
从输出日志中可以看到Logstash从Kafka消费成功,并且来自两个数据源的信息统一进行了输出。不过从上方的两张截图来看,Kafka的消息被发送到了不同的分区,因此Logstash消费时出现了乱序。
这时就引入了两个问题:
1. 从Kafka拉取的数据格式和日志中的数据格式不统一怎么办?
2. Kafka仅在分区内保证顺序,Logstash如果对顺序有着严格要求,怎么办?
首先我们来看第一个问题,不同的数据源数据格式不统一其实是个大概率的事情。那么是否可以针对不同的数据源进行不同的grok分析呢?没找到相关的资料能够支持这种区分的配置,只能通过grok的多match规则顺序执行(第一条失败了会执行第二条)来勉强达到要求。不过进一步考虑下来,架构上可以采用多个Logstash分别来进行不同数据源的信息采集,进行一个数据的初步整理后再分发到下游的ElasticSearch。这样部署上更加灵活,在对各个Logstash的节点进行配置时的限制也会更少。
要回答第二个问题,首先需要了解Kafka为什么会有分区的概念。Kafka对同一个topic支持设置多个分区,主要是为了能够将一个topic的数据处理水平扩展到位于多台服务器的broker中以此提升性能。那么如果说需要对接的系统仅仅是从侵入性考虑不愿意让日志采集直接对接日志或者数据库,而是通过Kafka这种消息中间件来进行解耦,那么专门用来进行日志采集的主题可以设置为只有1个分区。
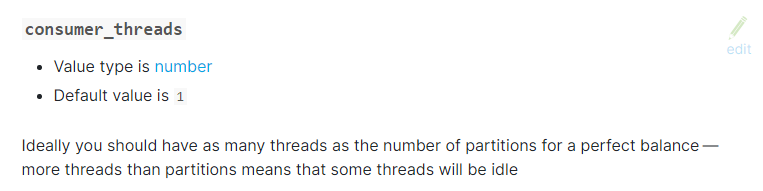
查看官网,发现input-kafka插件有一个配置项叫做consumer_threads,也就是消费者线程数。那么即便是Kafka的对应主题配置了1个分区,还需要将消费者线程数配置为1,否则同一个消费者组内的多个消费者来拉取同一分区内的数据也没有办法做到顺序。不过该配置项默认值就是1,不太容易踩到这个坑。
综上所述,如果对于消费的数据有严格的顺序要求,消息中间件不妨选用RabbiMQ,Logstash本身也提供了对接RabbitMQ的插件。另外,在对接不同数据源时可以采用多Logstash服务进行区分采集的部署方式。