第七章的知识总结:
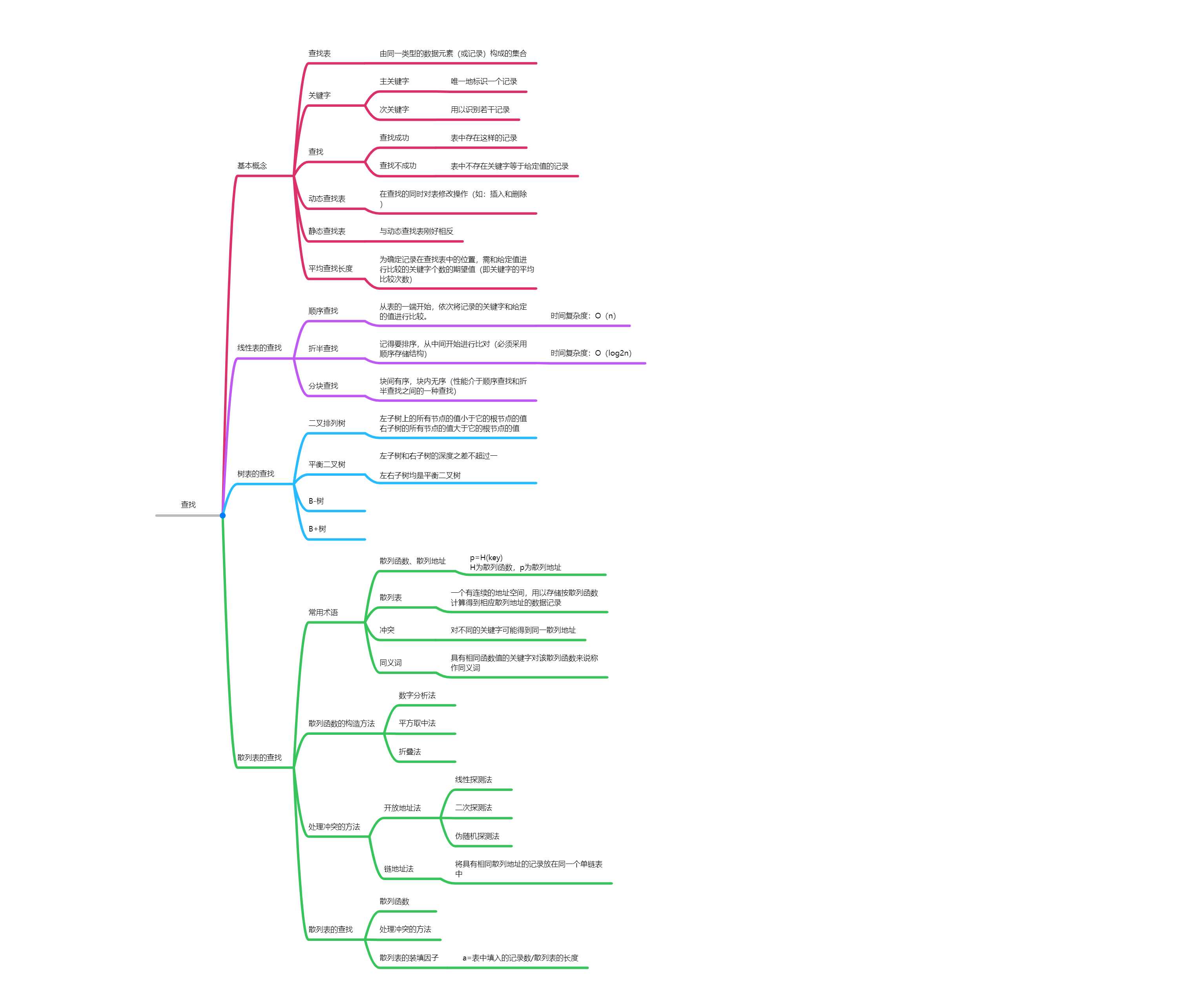
作业:
判断题:
1.在散列表中,所谓同义词就是具有相同散列地址的两个元素。(2分) T F
原因:应该是该两个不同元素,具有同一散列地址才是同义词。
2.在度量搜索引擎的结果集的相关度时,召回率很低意味着大多数相关的文档没有被找到。(2分)T F
3.在度量搜索引擎的结果集的相关度时,准确率很低意味着找出的大部分文档是无关的。(2分)T F
召回率(Recall Rate,也叫查全率)是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率;精度是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。
(关于准确率和召回率:https://blog.csdn.net/yechaodechuntian/article/details/37394967)
选择题:
选择题没有太多挖坑的地方,主要是一些重要的、容易混淆的概念
1.在下列查找的方法中,平均查找长度与结点个数无关的查找方法是: (2分)
利用二叉搜索树
2.(neuDS)对线性表进行二分查找时,要求线性表必须( ) (2分)
以链接方式存储,且结点按关键字值有序排列
3.若查找每个元素的概率相等,则在长度为n的顺序表上查找任一元素的平均查找长度为()。 (2分)
(n-1)/2
原因:第一个元素只用比较一次就可以找到,最后一个要比较n次,所以平均查找长度为(n+1)/2.
4.(neuDS)当采用分块查找时,数据的组织方式为( )。(2分)
数据分成若干块,每块内数据必须有序,但块间不必有序
5.__是HASH查找的冲突处理方法: (2分)
开放地址法
这些都是平常不太容易注意到的点,这些选择题帮我们很好地帮我们总结了一下易混淆的知识点。
3.编程题
这一道主要就是考察运用哈希算法的能力。一定要注意表长是否是素数,不是的话要找出合适的素数。找素数的两种方法:
第一种方法:
1 int NextPrime(int n) //求素数 2 { 3 int p; 4 if(n==1) return 2; 5 if(n%2==1) 6 { 7 p = n+2; 8 } 9 else p = n+1; 10 while (1) 11 { 12 int i; 13 for(i=3; i*i<=p; i+=2) 14 { 15 if(p%i == 0) break; 16 } 17 if(i*i > p) break; 18 else p += 2; 19 } 20 return p; 21 }
这种方法会比较难理解,但是判断表长和找素数是在一个函数里完成的,看起来会整洁很多
第二种方法:
1 bool prime(int a)//返回值为布尔类型,判断素数 2 { 3 int i, k; 4 if(a==0||a==1) return 0; 5 k=(int)sqrt(a);//k=根号a 6 for(i=2; i<=k; i++) 7 if(a%i==0) return 0; 8 return 1; 9 } 10 int get_prime(int a) 11 { 12 while(!prime(a)) 13 { 14 a++; 15 } 16 return a; 17 }
这种方法简单易懂,和上学期学习的判断素数的方法很像,推荐同学们使用
我的代码最开始有三个测试点报错,后来改了很久,才发现是一些很小但很容易错的地方
第一个:
1 int Hash (int Key, int p) 2 { 3 int a = Key % p; 4 for(int i = 0; i <= p; i++) //这里应该是i<p,i的取值应该在0 - (p-1),等于p的时候相当于回到了第一次循环,没有意义 5 { 6 int b = (a + i*i) % p; 7 if(!HashTable[b]) 8 { 9 HashTable[b] = 1; 10 return b; 11 } 12 } 13 return -1; 14 }
第二个:
1 int Hash (int Key, int p) 2 { 3 int a = Key % p; 4 for(int i = 0; i < p; i++) 5 { 6 a = (a + i*i) % p; //这里应该单独定义一个变量来存值,因为每次应该都是在原来数的基础上进行增加的操作 7 if(!HashTable[a]) 8 { 9 HashTable[a] = 1; 10 return a; 11 } 12 } 13 return -1; 14 }
正确的代码:
1 int Hash (int Key, int p) 2 { 3 int a = Key % p; 4 for(int i = 0; i < p; i++) 5 { 6 int b = (a + i*i) % p; 7 if(!HashTable[b]) 8 { 9 HashTable[b] = 1; 10 return b; 11 } 12 } 13 return -1; 14 }
第三个,不要想着直接用char作为Hash函数的返回值,因为char类型只有八位且 ‘0’ + 10 != ‘10’,所以将返回类型设为int,输出时按返回值的情况分别进行输出。
该题的完整代码:
1 #include <iostream> 2 #include<cmath> 3 using namespace std; 4 5 int HashTable[11000], a[11000]; 6 7 int NextPrime(int n) //求素数 8 { 9 int p; 10 if(n==1) return 2; 11 if(n%2==1) 12 { 13 p = n+2; 14 } 15 else p = n+1; 16 while (1) 17 { 18 int i; 19 for(i=3; i*i<=p; i+=2) 20 { 21 if(p%i == 0) break; 22 } 23 if(i*i > p) break; 24 else p += 2; 25 } 26 return p; 27 } 28 29 int Hash (int Key, int p) 30 { 31 int a = Key % p; 32 for(int i = 0; i < p; i++) 33 { 34 int b = (a + i*i) % p; 35 if(!HashTable[b]) 36 { 37 HashTable[b] = 1; 38 return b; 39 } 40 } 41 return -1; 42 } 43 44 int main() 45 { 46 int n, t; 47 cin >> t >> n; 48 t = NextPrime(t); 49 for(int i=0; i<n; i++) 50 { 51 cin >> a[i]; 52 HashTable[i] = 0; 53 } 54 int p; 55 p = Hash(a[0], t); 56 if(p<0) cout << "-"; 57 else cout << p; 58 for(int i=1; i<n; i++) 59 { 60 p = Hash(a[i], t); 61 if(p<0) cout << " -"; 62 else cout << " " << p; 63 } 64 return 0; 65 }
实践1的编程题看起来不是特别难,但是一定要注意几种情况:
1.当要找的数小于全部数的时候,输出0,而不是-1;
2.当要找的数大于全部数的时候,可以不用进行比较,直接返回-1就好了;
代码如下:
1 #include <iostream> 2 using namespace std; 3 4 typedef struct 5 { 6 int key; 7 }ElemType; 8 9 typedef struct 10 { 11 ElemType *R; 12 int length; 13 }SSTable; 14 15 void init(SSTable &ST, int n) 16 { 17 ST.length = n; 18 ST.R = new ElemType[n+1]; 19 } 20 21 int Search_Bin(SSTable ST, int key) 22 { 23 int low = 0; 24 int high = ST.length-1; 25 int mid; 26 if(key>ST.R[high].key) return -1; 27 else 28 { 29 while(low<=high) 30 { 31 mid = (low + high)/2; 32 if(key<=ST.R[mid].key) high = mid - 1; 33 else low = mid + 1; 34 } 35 return low; 36 } 37 } 38 39 int main() 40 { 41 int n; 42 SSTable ST; 43 44 cin >> n; 45 46 int i, m, x; 47 init(ST, n); 48 49 for(i=0; i<n; i++) 50 { 51 cin >> ST.R[i].key; 52 } 53 54 cin >> x; 55 56 if(Search_Bin(ST, x)!=-1) cout << Search_Bin(ST, x) <<endl; 57 else cout << "-1" <<endl; //分情况进行输出 58 59 delete []ST.R; //申请了空间一定要记得释放哦 60 61 return 0; 62 }
第七章对写代码很有帮助,查找也是大部分代码里需要用到的算法,感觉学好了查找,用对查找的方法,对提高代码的时间复杂度很有帮助。
希望下一章打代码的时候可以细心一些,多注意一些小的细节。