一,使用数组存储
二,缓存行优势&伪共享
三,内存屏障
参考文章:https://ifeve.com/dissecting-disruptor-whats-so-special/
一,使用数组存储
之所以ringbuffer采用这种数据结构,是因为它在可靠消息传递方面有很好的性能。这就够了,不过它还有一些其他的优点。
首先,因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。(译者注:数组内元素的内存地址的连续性存储的)。这是对CPU缓存友好的—也就是说,在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。(校对注:因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)
其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
在本文中并没有介绍如何避免ringbuffer产生重叠,以及如何对ringbuffer进行读写操作。你可能注意到了我将ringbuffer和链表那样的数据结构进行比较,因为我并不认为链表是实际问题的标准答案。
当你将Disruptor和基于 队列之类的实现进行比较时,事情将变得很有趣。队列通常注重维护队列的头尾元素,添加和删除元素等。所有的这些我都没有在ringbuffer里提到,这是因为ringbuffer不负责这些事情,我们把这些操作都移到了数据结构(ringbuffer)的外部。
二,缓存行优势&伪共享
计算机基础
CPU是你机器的心脏,最终由它来执行所有运算和程序。主内存(RAM)是你的数据(包括代码行)存放的地方。本文将忽略硬件驱动和网络之类的东西,因为Disruptor的目标是尽可能多的在内存中运行。
CPU和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一个循环计数-你不想每次循环都跑到主内存去取这个数据来增长它吧)。
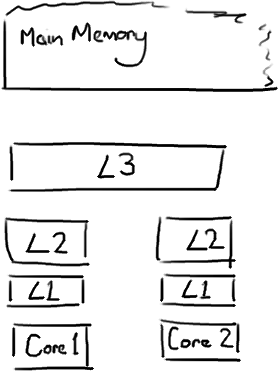
越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。
Martin和Mike的 QCon presentation演讲中给出了一些缓存未命中的消耗数据:
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
| 主存 | 约60-80纳秒 | |
| QPI 总线传输 (between sockets, not drawn) |
约20ns | |
| L3 cache | 约40-45 cycles, | 约15ns |
| L2 cache | 约10 cycles, | 约3ns |
| L1 cache | 约3-4 cycles, | 约1ns |
| 寄存器 | 1 cycle |
如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。
缓存行
现在需要注意一件有趣的事情,数据在缓存中不是以独立的项来存储的,如不是一个单独的变量,也不是一个单独的指针。缓存是由缓存行组成的,通常是64字节(译注:这篇文章发表时常用处理器的缓存行是64字节的,比较旧的处理器缓存行是32字节),并且它有效地引用主内存中的一块地址。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。
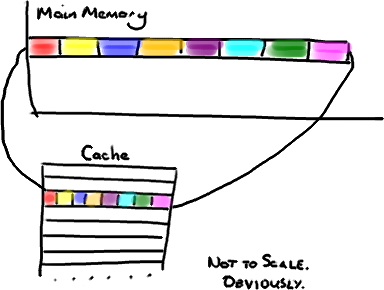
非常奇妙的是如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。因此你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。我在第一篇关于ring buffer的文章中顺便提到过这个,它解释了我们的ring buffer使用数组的原因。
因此如果你数据结构中的项在内存中不是彼此相邻的(链表,我正在关注你呢),你将得不到免费缓存加载所带来的优势。并且在这些数据结构中的每一个项都可能会出现缓存未命中。
不过,所有这种免费加载有一个弊端。设想你的long类型的数据不是数组的一部分。设想它只是一个单独的变量。让我们称它为head,这么称呼它其实没有什么原因。然后再设想在你的类中有另一个变量紧挨着它。让我们直接称它为tail。现在,当你加载head到缓存的时候,你也免费加载了tail。
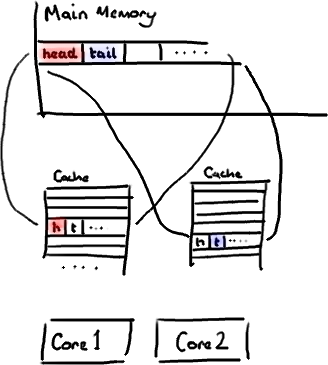
听想来不错。直到你意识到tail正在被你的生产者写入,而head正在被你的消费者写入。这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程所使用。
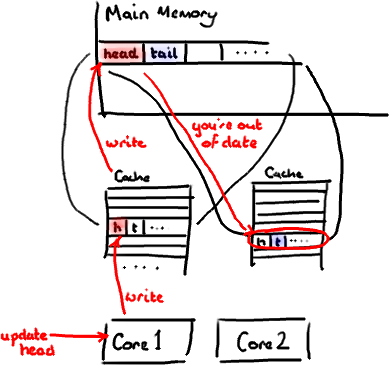
设想你的消费者更新了head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。请记住我们必须以整个缓存行作为单位来处理(译注:这是CPU的实现所规定的,详细可参见深入分析Volatile的实现原理),不能只把head标记为无效。
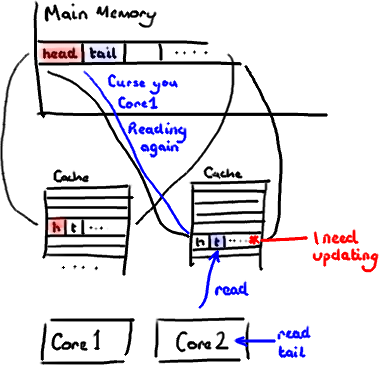
现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个和你的消费者无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。
当然如果两个独立的线程同时写两个不同的值会更糟。因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。
这叫作“伪共享”(译注:可以理解为错误的共享),因为每次你访问head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。
解决方案-神奇的缓存行填充
你会看到Disruptor消除这个问题,至少对于缓存行大小是64字节或更少的处理器架构来说是这样的(译注:有可能处理器的缓存行是128字节,那么使用64字节填充还是会存在伪共享问题),通过增加补全来确保ring buffer的序列号不会和其他东西同时存在于一个缓存行中。
1 |
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding |
2 |
private volatile long cursor = INITIAL_CURSOR_VALUE; |
3 |
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding |
因此没有伪共享,就没有和其它任何变量的意外冲突,没有不必要的缓存未命中。
在你的Entry类中也值得这样做,如果你有不同的消费者往不同的字段写入,你需要确保各个字段间不会出现伪共享。
修改:Martin写了一个从技术上来说更准确更详细的关于伪共享的文章,并且发布了性能测试结果。
三,内存屏障
什么是内存屏障?
它是一个CPU指令。没错,又一次,我们在讨论CPU级别的东西,以便获得我们想要的性能(Martin著名的Mechanical Sympathy理论)。基本上,它是这样一条指令: a)确保一些特定操作执行的顺序; b)影响一些数据的可见性(可能是某些指令执行后的结果)。
编译器和CPU可以在保证输出结果一样的情况下对指令重排序,使性能得到优化。插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。正如去拉斯维加斯旅途中各个站点的先后顺序在你心中都一清二楚。
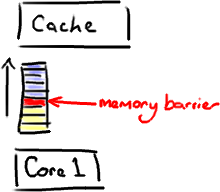
内存屏障另一个作用是强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个cpu核心或者哪颗CPU执行的。
和Java有什么关系?
现在我知道你在想什么——这不是汇编程序。它是Java。
这里有个神奇咒语叫volatile(我觉得这个词在Java规范中从未被解释清楚)。如果你的字段是volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。
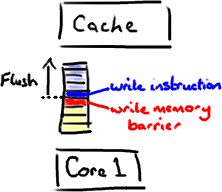
这意味着如果你对一个volatile字段进行写操作,你必须知道:
1、一旦你完成写入,任何访问这个字段的线程将会得到最新的值。
2、在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可见的,因为内存屏障会把之前的写入值都刷新到缓存。
举个例子呗!
很高兴你这样说了。又是时候让我来画几个甜甜圈了。
RingBuffer的指针(cursor)(译注:指向队尾元素)属于一个神奇的volatile变量,同时也是我们能够不用锁操作就能实现Disruptor的原因之一。
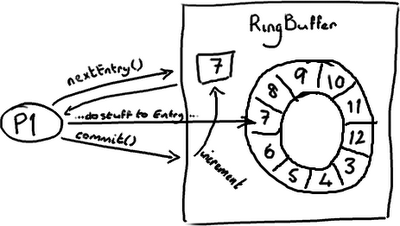
生产者将会取得下一个Entry(或者是一批),并可对它(们)作任意改动, 把它(们)更新为任何想要的值。如你所知,在所有改动都完成后,生产者对ring buffer调用commit方法来更新序列号(译注:把cursor更新为该Entry的序列号)。对volatile字段(cursor)的写操作创建了一个内存屏障,这个屏障将刷新所有缓存里的值(或者至少相应地使得缓存失效)。
这时候,消费者们能获得最新的序列号码(8),并且因为内存屏障保证了它之前执行的指令的顺序,消费者们可以确信生产者对7号Entry所作的改动已经可用。
…那么消费者那边会发生什么?
消费者中的序列号是volatile类型的,会被若干个外部对象读取——其他的下游消费者可能在跟踪这个消费者。ProducerBarrier/RingBuffer(取决于你看的是旧的还是新的代码)跟踪它以确保环没有出现重叠(wrap)的情况(译注:为了防止下游的消费者和上游的消费者对同一个Entry竞争消费,导致在环形队列中互相覆盖数据,下游消费者要对上游消费者的消费情况进行跟踪)。
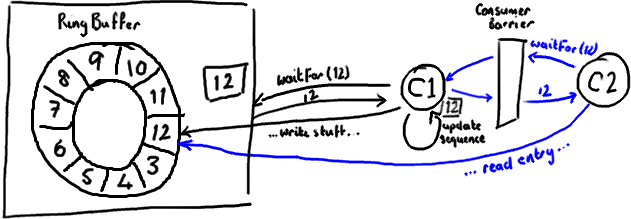
所以,如果你的下游消费者(C2)看见前一个消费者(C1)在消费号码为12的Entry,当C2的读取也到了12,它在更新序列号前将可以获得C1对该Entry的所作的更新。
基本来说就是,C1更新序列号前对ring buffer的所有操作(如上图黑色所示),必须先发生,待C2拿到C1更新过的序列号之后,C2才可以为所欲为(如上图蓝色所示)。
对性能的影响
内存屏障作为另一个CPU级的指令,没有锁那样大的开销。内核并没有在多个线程间干涉和调度。但凡事都是有代价的。内存屏障的确是有开销的——编译器/cpu不能重排序指令,导致不可以尽可能地高效利用CPU,另外刷新缓存亦会有开销。所以不要以为用volatile代替锁操作就一点事都没。
你会注意到Disruptor的实现对序列号的读写频率尽量降到最低。对volatile字段的每次读或写都是相对高成本的操作。但是,也应该认识到在批量的情况下可以获得很好的表现。如果你知道不应对序列号频繁读写,那么很合理的想到,先获得一整批Entries,并在更新序列号前处理它们。这个技巧对生产者和消费者都适用。以下的例子来自BatchConsumer:
01 |
long nextSequence = sequence + 1; |
02 |
while (running) |
03 |
{ |
04 |
try |
05 |
{ |
06 |
final long availableSequence = consumerBarrier.waitFor(nextSequence); |
07 |
while (nextSequence <= availableSequence) |
08 |
{ |
09 |
entry = consumerBarrier.getEntry(nextSequence); |
10 |
handler.onAvailable(entry); |
11 |
nextSequence++; |
12 |
} |
13 |
handler.onEndOfBatch(); |
14 |
sequence = entry.getSequence(); |
15 |
} |
16 |
… |
17 |
catch (final Exception ex) |
18 |
{ |
19 |
exceptionHandler.handle(ex, entry); |
20 |
sequence = entry.getSequence(); |
21 |
nextSequence = entry.getSequence() + 1; |
22 |
} |
23 |
} |
(你会注意到,这是个旧式的代码和命名习惯,因为这是摘自我以前的博客文章,我认为如果直接转换为新式的代码和命名习惯会让人有点混乱)
在上面的代码中,我们在消费者处理entries的循环中用一个局部变量(nextSequence)来递增。这表明我们想尽可能地减少对volatile类型的序列号的进行读写。
总结
内存屏障是CPU指令,它允许你对数据什么时候对其他进程可见作出假设。在Java里,你使用volatile关键字来实现内存屏障。使用volatile意味着你不用被迫选择加锁,并且还能让你获得性能的提升。
但是,你需要对你的设计进行一些更细致的思考,特别是你对volatile字段的使用有多频繁,以及对它们的读写有多频繁。