爬取百度贴吧
=====================
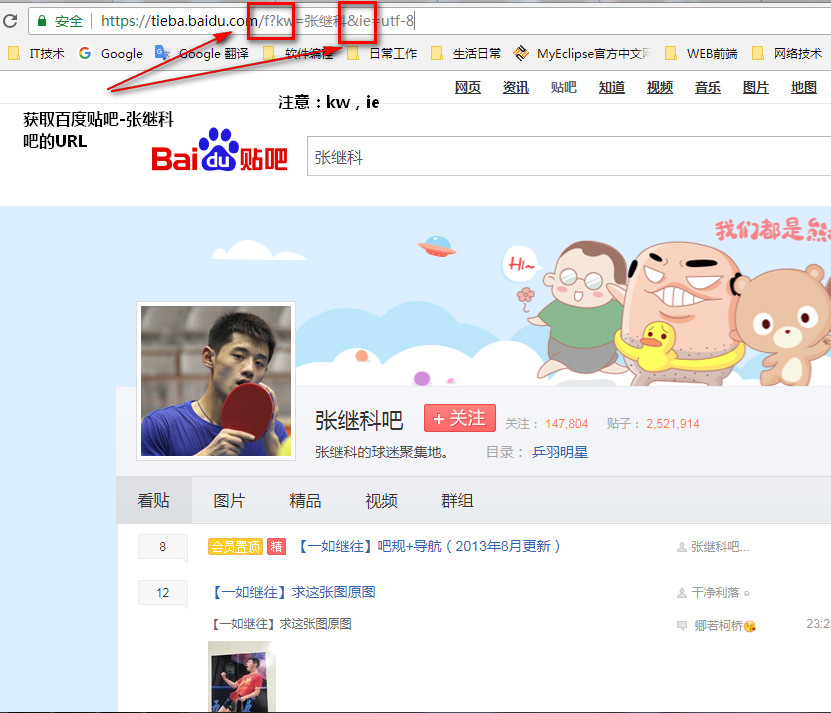
=====
结果示例:
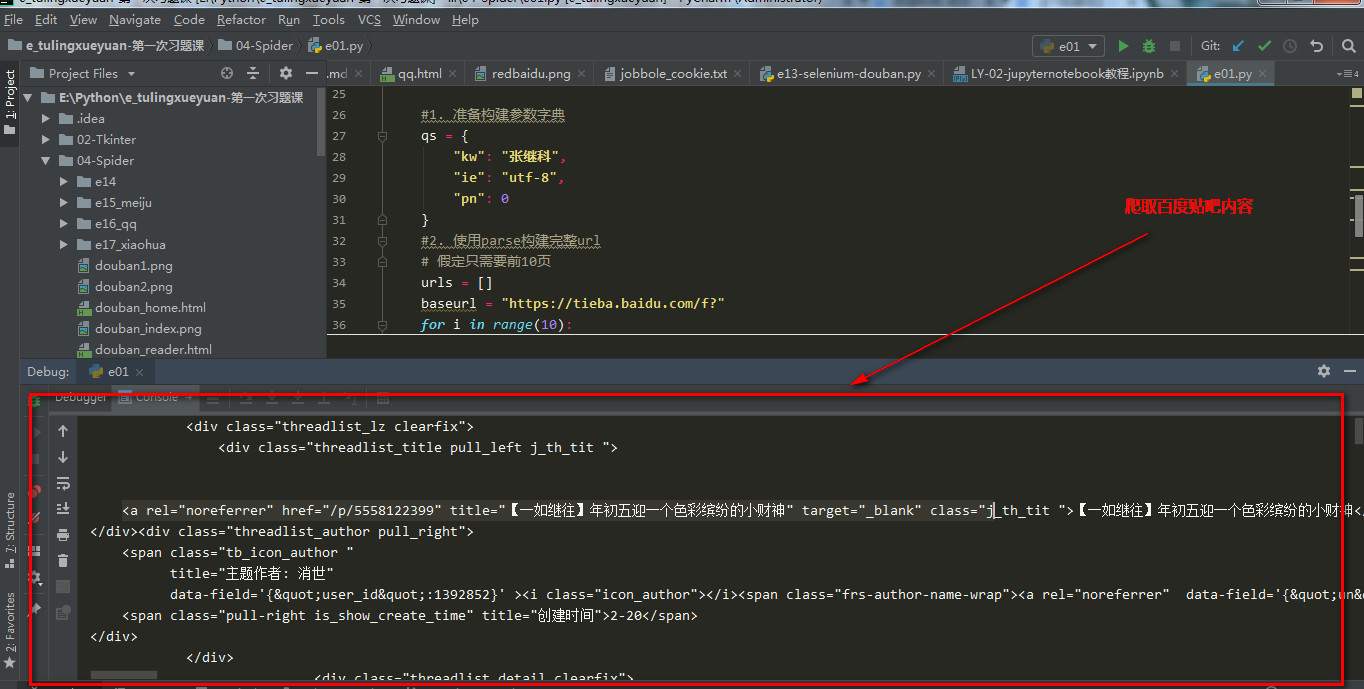
=====================================
1 ''' 2 爬去百度贴吧-张继科吧 3 1. 张继科吧主页是 https://tieba.baidu.com/f?kw=张继科 4 2. 进去之后,贴吧有很多页 5 第一页网址:https://tieba.baidu.com/f?kw=张继科&ie=utf-8&pn=0 6 第二页网址:https://tieba.baidu.com/f?kw=张继科&ie=utf-8&pn=50 7 第三页网址:https://tieba.baidu.com/f?kw=张继科&ie=utf-8&pn=100 8 第四页网址:https://tieba.baidu.com/f?kw=张继科&ie=utf-8&pn=150 9 第五页网址:https://tieba.baidu.com/f?kw=张继科&ie=utf-8&pn=200 10 3. 由上面网址可以找到规律,每一页只有后面数字不同,且数字应该是 (页数-1)x50 11 12 解决方法: 13 1. 准备构建参数字典 14 字典包含三部分,kw,ie,pn 15 2. 使用parse构建完整url 16 3. 使用for循环下载 17 ''' 18 19 from urllib import request, parse 20 21 22 23 if __name__ == '__main__': 24 25 #1. 准备构建参数字典 26 qs = { 27 "kw": "张继科", 28 "ie": "utf-8", 29 "pn": 0 30 } 31 #2. 使用parse构建完整url 32 # 假定只需要前10页 33 urls = [] 34 baseurl = "https://tieba.baidu.com/f?" 35 for i in range(10): 36 # 构建新的qs 37 pn = i * 50 38 qs['pn'] = str(pn) 39 # 把qs编码后和基础url进行拼接 40 # 拼接完毕后装入url列表中 41 urls.append( baseurl + parse.urlencode(qs) ) 42 43 print(urls) 44 #3. 使用for循环下载 45 46 for url in urls: 47 rsp = request.urlopen(url) 48 html = rsp.read().decode("utf-8") 49 print(url) 50 print(html) 51 52 ''' 53 待完善: 54 1. 把每个抓到的内容保存到文件中,文件后缀是html 55 '''