前言
本文主要介绍的是ELK日志系统入门和使用教程。
ELK介绍
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
-
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
-
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
-
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
-
Filebeat是一个轻量型日志采集器,可以方便的同kibana集成,启动filebeat后,可以直接在kibana中观看对日志文件进行detail的过程。
ELasticSearch介绍
ElasticSearch是什么
Elasticsearch 是一个基于JSON的分布式搜索和分析引擎。它可以从RESTful Web服务接口访问,并使用模式少JSON(JavaScript对象符号)文档来存储数据。它是基于Java编程语言,这使Elasticsearch能够在不同的平台上运行。使用户能够以非常快的速度来搜索非常大的数据量。
ElasticSearch可以做什么
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
Lucene是什么
ApacheLucene将写入索引的所有信息组织成一种倒排索引(Inverted Index)的结构之中,该结构是种将词项映射到文档的数据结构。其工作方式与传统的关系数据库不同,大致来说倒排索引是面向词项而不是面向文档的。且Lucene索引之中还存储了很多其他的信息,如词向量等等,每个Lucene都是由多个段构成的,每个段只会被创建一次但会被查询多次,段一旦创建就不会再被修改。多个段会在段合并的阶段合并在一起,何时合并由Lucene的内在机制决定,段合并后数量会变少,但是相应的段本身会变大。段合并的过程是非常消耗I/O的,且与之同时会有些不再使用的信息被清理掉。在Lucene中,将数据转化为倒排索引,将完整串转化为可用于搜索的词项的过程叫做分析。文本分析由分析器(Analyzer)来执行,分析其由分词器(Tokenizer),过滤器(Filter)和字符映射器(Character Mapper)组成,其各个功能显而易见。
更多ElasticSearch的相关介绍可以查看我的这篇博文:https://www.cnblogs.com/xuwujing/p/12093933.html
Logstash介绍
Logstash是一个数据流引擎:
它是用于数据物流的开源流式ETL引擎,在几分钟内建立数据流管道,具有水平可扩展及韧性且具有自适应缓冲,不可知的数据源,具有200多个集成和处理器的插件生态系统,使用Elastic Stack监视和管理部署
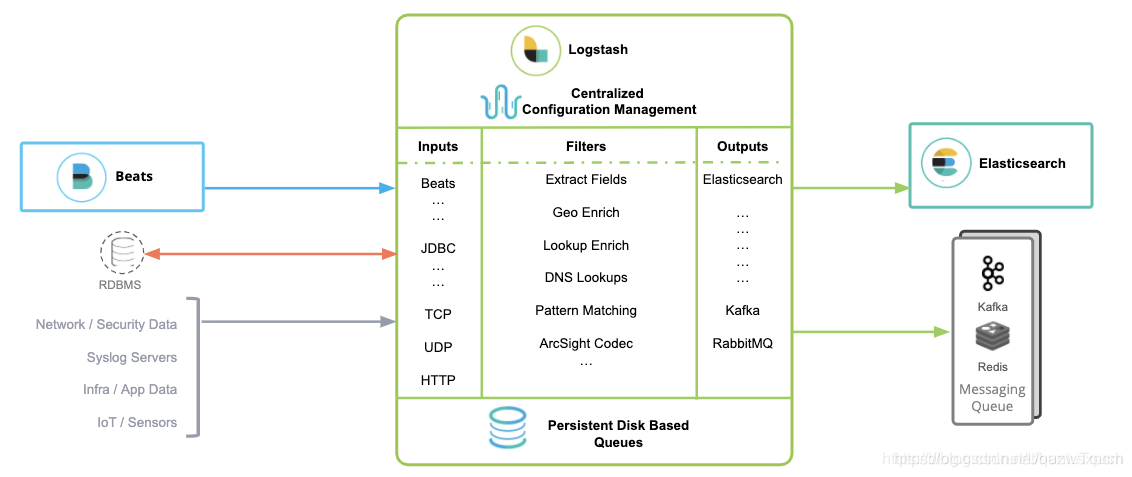
Logstash包含3个主要部分: 输入(inputs),过滤器(filters)和输出(outputs)。
inputs主要用来提供接收数据的规则,比如使用采集文件内容;
filters主要是对传输的数据进行过滤,比如使用grok规则进行数据过滤;
outputs主要是将接收的数据根据定义的输出模式来进行输出数据,比如输出到ElasticSearch中.
示例图:
Kibana介绍
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
Kibana 可以使大数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。
Filebeat介绍
Filebeat 是使用 Golang 实现的轻量型日志采集器,也是 Elasticsearch stack 里面的一员。本质上是一个 agent ,可以安装在各个节点上,根据配置读取对应位置的日志,并上报到相应的地方去。
Filebeat 的可靠性很强,可以保证日志 At least once 的上报,同时也考虑了日志搜集中的各类问题,例如日志断点续读、文件名更改、日志 Truncated 等。
Filebeat 并不依赖于 ElasticSearch,可以单独存在。我们可以单独使用Filebeat进行日志的上报和搜集。filebeat 内置了常用的 Output 组件, 例如 kafka、ElasticSearch、redis 等,出于调试考虑,也可以输出到 console 和 file 。我们可以利用现有的 Output 组件,将日志进行上报。
当然,我们也可以自定义 Output 组件,让 Filebeat 将日志转发到我们想要的地方。
filebeat 其实是 elastic/beats 的一员,除了 filebeat 外,还有 HeartBeat、PacketBeat。这些 beat 的实现都是基于 libbeat 框架。
Filebeat 由两个主要组件组成:harvester 和 prospector。
采集器 harvester 的主要职责是读取单个文件的内容。读取每个文件,并将内容发送到 the output。 每个文件启动一个 harvester,harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态。如果文件在读取时被删除或重命名,Filebeat 将继续读取文件。
查找器 prospector 的主要职责是管理 harvester 并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个 harvester。每个 prospector 都在自己的 Go 协程中运行。
注:Filebeat prospector只能读取本地文件, 没有功能可以连接到远程主机来读取存储的文件或日志。
示例图:

ELK日志系统安装
环境准备
ELK下载地址推荐使用清华大学或华为的开源镜像站。
下载地址:
https://mirrors.huaweicloud.com/logstash
https://mirrors.tuna.tsinghua.edu.cn/ELK
ELK7.3.2百度网盘地址:
链接:https://pan.baidu.com/s/1tq3Czywjx3GGrreOAgkiGg
提取码:cxng
ELasticSearch集群安装
ElasticSearch集群安装依赖JDK,本文的ElasticSearch版本为7.3.2,对应的JDK的版本为12。
1,文件准备
将下载好的elasticsearch文件解压
输入:
tar -xvf elasticsearch-7.3.2-linux-x86_64.tar.gz
然后移动到/opt/elk文件夹 里面,没有该文件夹则创建,然后将文件夹重命名为masternode.
在/opt/elk输入
mv elasticsearch-7.3.2-linux-x86_64 /opt/elk mv
elasticsearch-7.3.2-linux-x86_64 masternode
2,配置修改
因为elasticsearch需要在非root的用户下面操作,并且elasticsearch的文件夹的权限也为非root权限, 因此我们需要创建一个用户进行操作,我们创建一个elastic用户,并赋予该目录的权限。
命令如下:
chown -R elastic:elastic /opt/elk/masternode
这里我们顺便再来指定ElasticSearch数据和日志存放的路径地址,我们可以先使用df -h命令查看当前系统的盘主要的磁盘在哪,然后在确认数据和日志存放的路径,如果在/home 目录下的话,我们就在home目录下创建ElasticSearch数据和日志的文件夹,这里为了区分,我们可以根据不同的节点创建不同的文件夹。这里的文件夹创建用我们刚刚创建好的用户去创建,切换到elastic用户,然后创建文件夹。
su elastic
mkdir /home/elk
mkdir /home/elk/masternode
mkdir /home/elk/masternode/data
mkdir /home/elk/masternode/logs
mkdir /home/elk/datanode
mkdir /home/elk/datanode/data
mkdir /home/elk/datanode/logs
创建成功之后,我们先修改masternode节点的配置,修改完成之后在同级目录进行copy一下,名称为datanode,然后只需少许更改datanode节点的配置即可。这里我们要修改elasticsearch.yml和jvm.options文件即可! 注意这里还是elastic用户!
cd /opt/elk/
vim masternode/config/elasticsearch.yml
vim masternode/config/jvm.options
masternode配置
这里需要注意的是elasticsearch7.x的配置和6.x有一些不同,主要是在master选举这块。
masternode的elasticsearch.yml文件配置如下:
cluster.name: pancm-cluster
node.name: master-1
network.host: 192.168.0.1
path.data: /home/elastic/masternode/data
path.logs: /home/elastic/masternode/logs
discovery.seed_hosts: ["192.168.0.1:9300","192.168.0.2:9300","192.168.0.3:9300"]
cluster.initial_master_nodes: ["192.168.0.1:9300","192.168.0.2:9300","192.168.0.3:9300"]
node.master: true
node.data: false
transport.tcp.port: 9301
http.port: 9201
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
cluster.routing.allocation.cluster_concurrent_rebalance: 16
cluster.routing.allocation.node_concurrent_recoveries: 16
cluster.routing.allocation.node_initial_primaries_recoveries: 16
elasticsearch.yml文件参数配置说明:
- cluster.name: 集群名称,同一集群的节点配置应该一致。es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
- node.name: 该节点的名称。命名格式建议为节点属性+ip末尾
- path.data: 数据存放的路径。
- path.logs: 日志存放的路径。
- network.host: 设置ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
- transport.tcp.port:设置节点间交互的tcp端口,默认是9300。
- http.port:设置对外服务的http端口,默认为9200。
- node.master: 指定该节点是否有资格被选举成为node,默认是true。
- node.data: 指定该节点是否存储索引数据,默认为true。
- 。。。
将jvm.options配置Xms和Xmx改成4G,配置如下:
-Xms4g
-Xmx4g
datanode配置
在配置完masternode节点的ElasticSearch之后,我们再来配置datanode节点的,我们将masternode节点copy一份并重命名为datanode,然后根据上述示例图中红色框出来简单更改一下即可。
命令如下:
cd /opt/elk/
cp -r masternode/ datanode
vim datanode/config/elasticsearch.yml
vim datanode/config/jvm.options
datenode的elasticsearch.yml文件配置如下:
cluster.name: pancm-cluster
node.name: data-1
network.host: 192.168.0.1
path.data: /home/elastic/datanode/data
path.logs: /home/elastic/datanode/logs
discovery.seed_hosts: ["192.168.0.1:9300","192.168.0.2:9300","192.168.0.3:9300"]
cluster.initial_master_nodes: ["192.168.0.1:9300","192.168.0.2:9300","192.168.0.3:9300"]
node.master: false
node.data: true
transport.tcp.port: 9300
http.port: 9200
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
cluster.routing.allocation.cluster_concurrent_rebalance: 16
cluster.routing.allocation.node_concurrent_recoveries: 16
cluster.routing.allocation.node_initial_primaries_recoveries: 16
datanode的jvm配置请遵循如下规则,如果内存小于64G,则取对半,否则取32G。比如内存16G,该jvm设置8G,如果是128G,就可以设置32G。
将jvm.options配置Xms和Xmx改成8G,配置如下:
-Xms8g
-Xmx8g
注:配置完成之后需要使用ll命令检查一下masternode和datanode权限是否属于elastic用户的,若不属于,可以使用chown -R elastic:elastic +路径 命令进行赋予权限。
上述配置完成之后,可以使用相同的方法在其他的机器在操作一次,或者使用ftp工具进行传输,又或者使用scp命令进行远程传输文件然后根据不同的机器进行不同的修改。
scp命令示例:
jdk环境传输:
scp -r /opt/java root@slave1:/opt
scp -r /opt/java root@slave2:/opt
ElasticSearch环境传输:
scp -r /opt/elk root@slave1:/opt
scp -r /home/elk root@slave1:/opt
scp -r /opt/elk root@slave2:/opt
scp -r /home/elk root@slave2:/opt
传输完成之后,在其他服务主要修改node.name、network.host这两个配置即可。
3,elasticsearch启动
完成elasticsearch集群安装配置之后,需要使用elastic用户来进行启动,每台机器的每个节点都需要进行操作!
在/opt/elk的目录下输入:
su elastic
cd /opt/elk
./masternode/bin/elasticsearch -d
./datanode/bin/elasticsearch -d
启动成功之后,可以输入jps命令进行查看或者在浏览器上输入 ip+9200或ip+9201进行查看。
出现以下界面表示成功!

Elasticsearch的6.x版本可以看这篇文章:https://www.cnblogs.com/xuwujing/p/11385255.html
Kibana安装
注:只需要在一台服务器上安装即可!
1,文件准备
将下载下来的kibana-7.3.2-linux-x86_64.tar.gz的配置文件进行解压
在linux上输入:
tar -xvf kibana-7.3.2-linux-x86_64.tar.gz
然后移动到/opt/elk 里面,然后将文件夹重命名为 kibana-7.3.2
输入:
mv kibana-7.3.2-linux-x86_64 /opt/elk
mv kibana-7.3.2-linux-x86_64 kibana-7.3.2
2,配置修改
进入文件夹并修改kibana.yml配置文件:
cd /opt/elk/kibana-7.3.2
vim config/kibana.yml
将配置文件新增如下配置:
server.port: 5601
server.host: "192.168.0.1"
elasticsearch.hosts: ["http://192.168.0.1:9200"]
elasticsearch.requestTimeout: 180000
3,Kinaba 启动
在启动这块,和kibana6.x有一些区别。
root用户下启动
在kibana上一级文件夹输入:
nohup ./kibana-7.3.2/bin/kibana --allow-root >/dev/null 2>&1 &
非root用户启动
需要将kibana设置的权限改为对用的用户权限
权限修改命令实例:
chown -R elastic:elastic /opt/elk/kibana-7.3.2
非root用户启动命令:
nohup ./kibana-7.3.2/bin/kibana >/dev/null 2>&1 &
启动成功之后再浏览器输入:
http://IP:5601

示例图:

Logstash安装
注:只需要在一台服务器上安装即可!
1,文件准备
将下载下来的logstash-7.3.2.tar.gz的配置文件进行解压
在linux上输入:
tar -xvf logstash-7.3.2.tar.gz
然后移动到/opt/elk 里面,然后将文件夹重命名为 logstash-7.3.2
输入:
mv logstash-7.3.2.tar /opt/elk
mv logstash-7.3.2.tar logstash-7.3.2
2,配置修改
进入文件夹并创建logstash-filebeat.conf配置文件:
cd /opt/elk/logstash-7.3.2
touch logstash-filebeat.conf
vim logstash-filebeat.conf
在配置文件新增如下配置,filter部分请根据对应情况修改
input {
beats {
type => "java"
port => "5044"
}
}filter {
grok {
match => { "message" =>"|%{DATA:log_time}|%{DATA:thread}|%{DATA:log_level}|%{DATA:class_name}|-%{GREEDYDATA:content}" }
}ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 86060)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}date {
match => [ "log_timestamp", "yyyy-MM-dd-HH:mm:ss" ]
locale => "cn"
}mutate {
rename => { "host" => "host.name" }
}}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["192.168.0.1:9200"]
index => "mylogs-%{+YYYY.MM.dd}"
}
}
-
port :是logstash接受filebeat数据的端口,保证filebeat传输到logstash的端口是该端口即可。
-
hosts: 这个填写elasticsearch的地址和设置的端口,集群地址可以用逗号隔开。
-
Index : 写入索引库的名称。%{+YYYY.MM.dd} 表示按天创建索引库。
3,Logstash 启动
root用户下启动
在 Logstash 文件夹输入:
nohup ./bin/logstash -f logstash-filebeat.conf >/dev/null 2>&1 &
或对配置文件进行热加载启动:
nohup ./bin/logstash -f logstash-filebeat.conf --config.reload.automatic >/dev/null 2>&1 &
示例图:

Filebeat安装
1,文件准备
将下载下来的filebeat-7.3.2-linux-x86_64.gz的配置文件进行解压
在linux上输入:
tar -xvf filebeat-7.3.2-linux-x86_64.tar.gz
然后移动到/opt/elk 里面,然后将文件夹重命名为 filebeat-7.3.2
输入
mv filebeat-7.3.2-linux-x86_64 /opt/elk
mv filebeat-7.3.2-linux-x86_64 filebeat-7.3.2
配置启动测试,使用root用户在filebeat文件夹输入:
./filebeat -c filebeat_test.yml test config
启动命令:
./filebeat -e -c filebeat_logstash.yml
后台启动命令:
nohup ./filebeat -c filebeat_logstash.yml >/dev/null 2>&1 &
若是后台启动,可以在filebeat统计目录的logs目录查看日志信息。
其它
- ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
- ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解
- ElasticSearch实战系列三: ElasticSearch的JAVA API使用教程
- ElasticSearch实战系列四: ElasticSearch理论知识介绍
- ElasticSearch实战系列五: ElasticSearch的聚合查询基础使用教程之度量(Metric)聚合
- ElasticSearch实战系列六: Logstash快速入门
- ElasticSearch实战系列七: Logstash实战使用-图文讲解
- ElasticSearch实战系列八: Filebeat快速入门和使用---图文详解
音乐推荐
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
掘金出处:https://juejin.im/user/5ae45d5bf265da0b8a6761e4
个人博客出处:http://www.panchengming.com