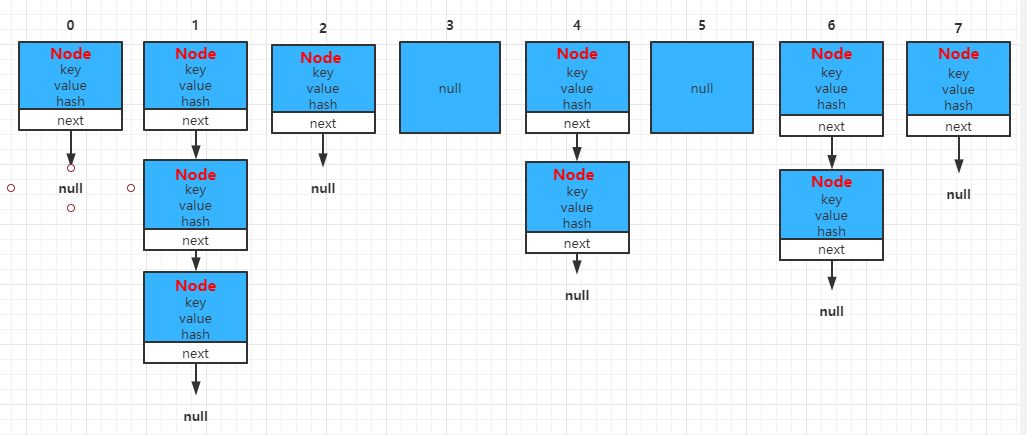
HashMap数据结构
HashMap是以数组+链表的形式进行存储数据。
数组的优缺点:通过下标索引方便查找,但是插入或删除慢。
链表的优缺点:查找一个元素需要以遍历链表的方式查找,但是插入或删除快。
HashMap内部维护了一个Node数组:

其中Node数据结构如下:

HashMap构造方法
HashMap数组默认大小是16,负载因子是0.75。
当创建HashMap集合对象的时候,在jdk8以前,构造方法中会创建一个长度为16的Entry[] table。在jdk8以后不是在HashMap的构造方法创建数组了,是在第一次调用put方法时创建数组--Node[] table。
HashMap,tableSizeFor(Object key)
static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
由于HashMap的 capacity 都是2的幂,因此这个方法用于找到大于等于initialCapacity的最小的2的幂(如果initialCapacity就是2的幂,则返回的还是这个数)。
HashMap中,数组的最大长度是1 << 30,所以采用上面的算法,一定返回一个从cap中有效位数开始,后面全部变成1的数(比如:00010101会变成00011111)。
注意:第一步用cap - 1,是为了防止cap已经是2的幂,如果不执行这个减1操作,则执行完后面的无符号右移操作之后,返回的capacity将是这个cap的2倍。
HashMap,hash(Object key) --- 计算key的hash值
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
1、如果 K 是空,则 hash 值为0,这也就是为啥 HashMap 的 K 可以是空。
2、不同的 K 的hashCode值可能相同。
3、在计算数组下标时,计算公式是 (tab.length - 1) & hash) 。如果数组长度很小(比如是16),那么length - 1即为 00001111,这样的值和 hashCode 直接进行按位与运算,实际上只用到了 hashCode 的后4位。如果当 hashCode 的高位变化很大,低位变化很小,这样就很容易发生 K 碰撞。这里将 hashCode 值右移16位,刚好将该二进制数对半切开,并且使用位异或运算,相当于使用 hashCode 的高16位打乱 hashCode 的低16位。这样就降低了 K 碰撞的几率(称为扰动函数)。
例如:
两个 hashCode 值,后四位相同:1111 1111 1111 1111 1111 0000 1110 1010 、111 0101 1111 1001 1111 0000 1110 1010
计算数组下标 (tab.length - 1) & hash) :
a、如果高位不参与运算,直接得到:0000 0000 0000 0000 0000 0000 1010 、0000 0000 0000 0000 0000 0000 1010 ==>发生碰撞
b、如果高位参与运算:
先进行高低位 ^ 运算,得到:1111 1111 1111 1111 0000 1111 0001 0101、1111 0101 1111 1001 0000 1010 0001 0011
再进行 & 运算,得到:0000 0000 0000 0000 0000 0000 0000 0101、0000 0000 0000 0000 0000 0000 0000 0011 ==>未发生碰撞
HashMap,put(K key, V value) --- 添加元素
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
执行步骤:
1、调用 hash(K) 方法计算K的 hash 值,然后结合数组长度 (tab.length - 1) & hash 得到数组下标。
2、如果 K 的 hash 值在HashMap中不存在,则直接将数据插入到数组中。若存在,则发生碰撞。
3、如果 K 的 hash 值在HashMap中存在,则比较两者 K 的 equals。
a、equals 返回 true,则将该键替换成新值value。
b、equals 返回 false,则新建一个Node节点,并插入到链表的尾部(尾插法)或者红黑树中。
其中,上面的b,是采用遍历当前链表。如果链表长度大于8,则判断数组长度是否大于64,大于64则转为红黑树,否则扩容。
4、判断数组中实际节点个数是否大于threshold,如果大于则扩容。
HashMap,resize() --- 扩容
当HashMap中元素越来越多时,碰撞的几率也就越来越高(数组长度是固定的)。所以为了提高效率(增删改查),就要对HashMap中的数组进行扩容。
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold }
...
1、扩容时,会将 table 长度变为原来的两倍(注意是 table 长度,而不是 threshlod )。
2、扩容时,会重新计算旧数组中节点的位置。节点在新数组中的位置只有两种情况:
a、原下标
b、原下标 + 旧数组长度
因此,在HashMap扩容时,是不需要重新计算 hash 值的,直接将原hash & 新数组长度即可。
HashMap,get(Object key)
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; }
执行步骤:
1、计算目标节点的hash值,并通过 (tab.length - 1) & hash 得到数组下标(这一步和 put 方法一样)。
2、判断下标,得到首节点。判断首节点是否为空,为空则直接返回空。
3、判断首节点 K 与目标节点的的 hash 是否相同,equals 方法是否相同,相同则直接返回首节点。
4、上一步如果不相同,判断首节点的下个节点是否为空,为空则直接返回空。
5、判断首节点是否为红黑树:
a、如果是,则通过红黑树取值并返回
b、如果不是,则遍历链表,直到 hash 值和 equals 相等则跳出返回
HashMap数组长度为啥要是2的幂?
在 put 元素时,需要计算 K 在数组中的下标,计算公式是 (tab.length - 1) & hash。只有数组长度是2的幂,减1后得到的二进制才全部是1。
例如16,减1后就是15,二进制为00001111),这样进行 & 运算时,二进制的每一位都是有效的(如果后面的4位中有个0,进行 & 运算后就还是0,这一位对应的数组下标就永远不会有元素,这样就增加了碰撞的几率)。
HashMap发生扩容的时机有哪些?
a、put元素,数组为空时(第一次put时)
b、put元素,数组中实际节点个数大于 threshold 时
c、put元素,发现链表长度超过8,且数组长度小于64时
HashMap初始化时,如何指定初始化大小?
a、如果无法确定元素个数,那么使用默认值(16)即可。
b、如果可以确定元素个数,initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即loader factor)默认为0.75。
HashMap会发生死循环?
多线程环境下:
jdk1.7在进行扩容操作时,会重新定位每个节点的下标,并采用头插法将节点迁移到新数组中。头插法会将链表的顺序翻转,有可能会出现两个节点成为循环链表(双方节点的next都指向对方),最终造成死循环。
jdk1.8是直接在 resize 函数中完成了数据迁移,并且jdk1.8在进行元素插入时使用的是尾插法,所以不会有死循环的问题。
HashMap为啥线程不安全?
多线程环境下:
在进行 put 操作时,会发生数据覆盖的情况。主要体现在两点:
a、假设两个线程A、B都在进行put操作,并且 hash 函数计算出的插入下标是相同的,当线程A执行完下面代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了 hash 碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。

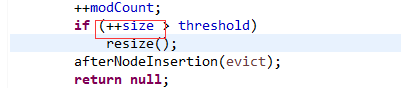
b、插入数据完成后,++size 非原子操作,可能后面的线程会覆盖前一个线程的操作。
ConcurrentHashMap如何保证线程安全?
ConcurrentHashMap成员变量使用 volatile 修饰,避免指令重排序,同时保证内存可见性。另外使用 CAS (引入Unsafe对象)和 synchronized 进行赋值操作,多线程操作只会锁住当前操作索引的节点(即对应链表)。
HashMap的链表转为红黑色的阈值是8,红黑色转链表阈值是6,为什么这么设计?
通过计算,发生 hash 碰撞8次的几率为0.00000006,所以8基本够用了(转为红黑色的概率很低)。
至于为什么转回来是6,因为如果 hash 碰撞次数在8附近徘徊,会一直发生链表和红黑色的转化,为了预防这种情况发生。