Hadoop环境搭建测试
1 安装软件
1.1 规划目录 /opt
[root@host2 ~]# cd /opt
[root@host2 opt]# mkdir java
[root@host2 opt]# mkdir cdh
[root@host2 opt]# ls
cdh java

1.2 安装RZ工具
RZ工具:可以直接从win平台拖动下载好的软件到Linux平台
sudo yum -y install lrzsz
1.3 上传软件
将windows准备好的软件上传

1.4 解压
[root@host2 java]# tar -zxf jdk-7u67-linux-x64.tar.gz #解压
[root@host2 java]# rm -rf jdk-7u67-linux-x64.tar.gz #删除压缩包
[root@host2 java]# ls
jdk1.7.0_67
[root@host2 java]# cd /opt/cdh/
[root@host2 cdh]# tar -zxf hadoop-2.5.0-cdh5.3.6.tar.gz #解压
[root@host2 cdh]# ls
hadoop-2.5.0-cdh5.3.6 hadoop-2.5.0-cdh5.3.6.tar.gz
[root@host2 cdh]# rm -rf hadoop-2.5.0-cdh5.3.6.tar.gz #删除压缩包
[root@host2 cdh]# ls
hadoop-2.5.0-cdh5.3.6
1.5删除hadoop说明文档,系统瘦身
[root@host2 opt]# rm -rf /opt/cdh/hadoop-2.5.0-cdh5.3.6/share/doc
2 配置JAVA、Hadoop环境变量
2.1 位置:/etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/java/jdk1.7.0_67
export PATH=$JAVA_HOME/bin:$PATH
#HADOOP_HOME
export HADOOP_HOME=/opt/cdh/hadoop-2.5.0-cdh5.3.6
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPPER_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
2.2 刷新
[root@host2 opt]# source /etc/profile #刷新
[root@host2 opt]# java -version #查看版本
java version "1.7.0_67"
Java(TM) SE Runtime Environment (build 1.7.0_67-b01)
Java HotSpot(TM) 64-Bit Server VM (build 24.65-b04, mixed mode)
3 配置Hadoop环境
当前目录:/opt/cdh/hadoop-2.5.0-cdh5.3.6
3.1 配置JAVA环境变量
3.1.1 etc/hadoop/hadoop-env.sh
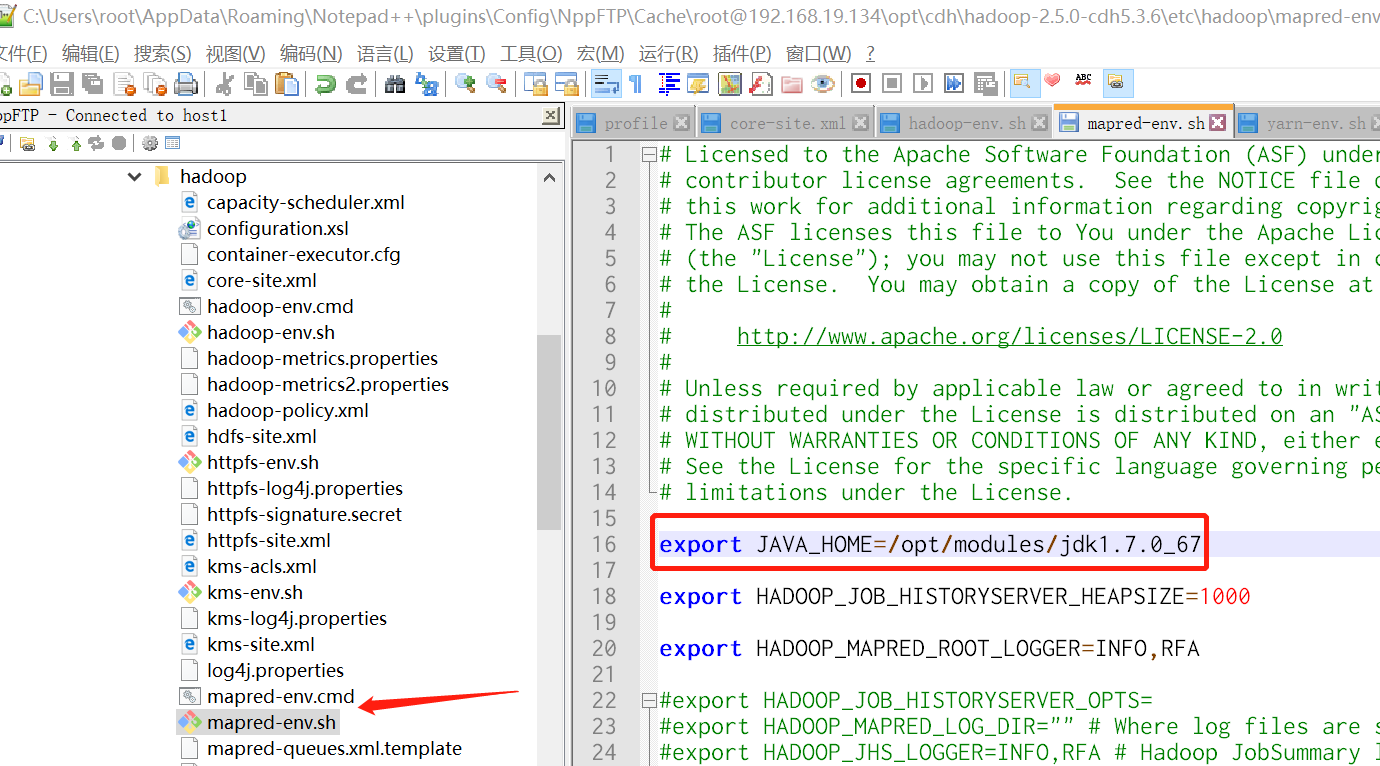
3.1.2 etc/hadoop/mapred-env.sh
3.1.3 etc/hadoop/yarn-env.sh
export JAVA_HOME=/opt/java/jdk1.7.0_67


3.2 配置文件
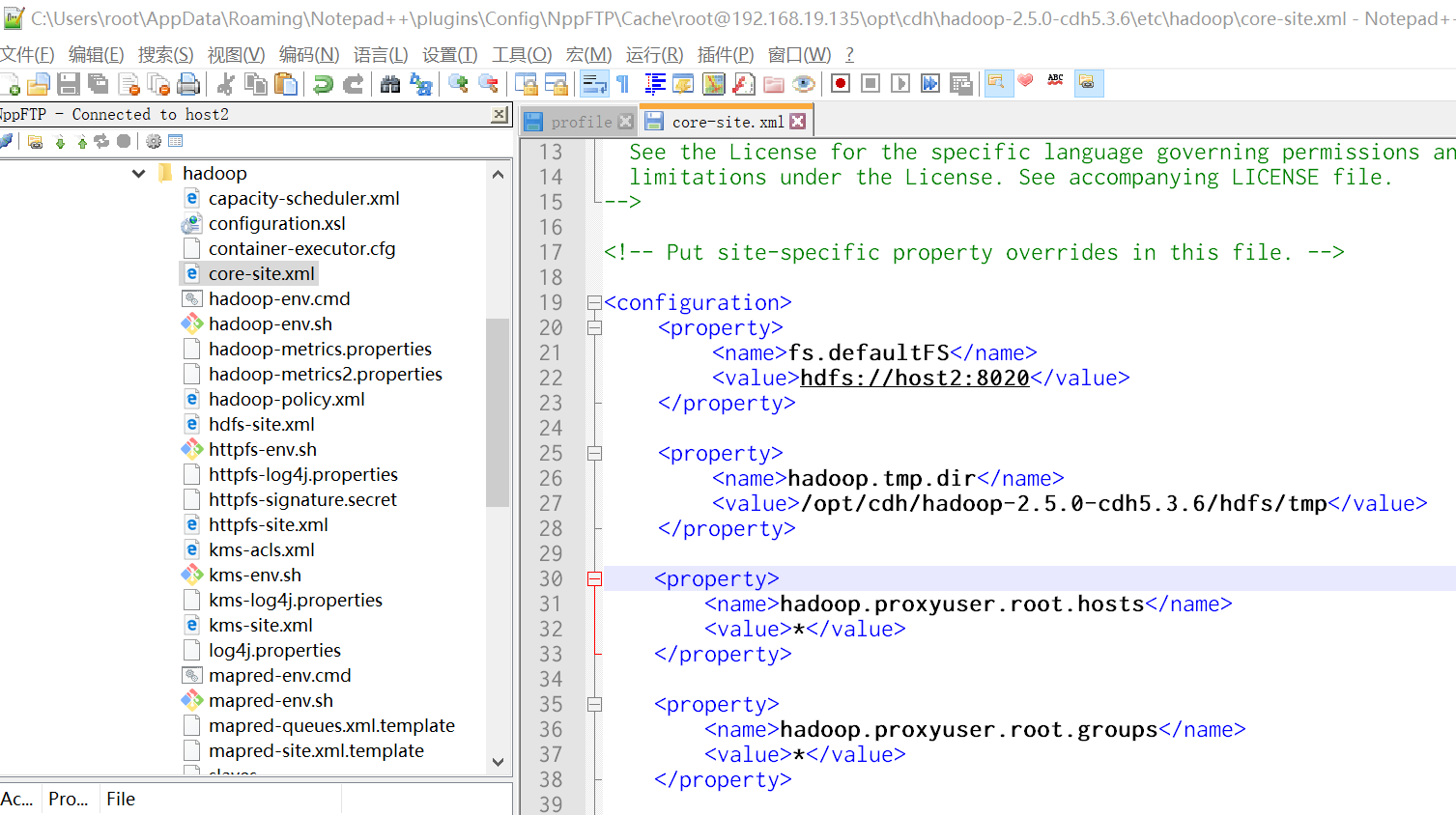
3.2.1 etc/hadoop/core-site.xml
说明:主节点NameNode位置及交互端口
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://host2:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/cdh/hadoop-2.5.0-cdh5.3.6/hdfs/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
3.2.2 etc/hadoop/hdfs-site.xml
说明:系统中文件块的数据副本个数,是所有datanode总和,每个datanode上只能存放1个副本
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>

3.2.3 etc/hadoop/yarn-site.xml:
<configuration>
<!-- reduce获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>host2</value>
</property>
</configuration>
3.2.4 etc/hadoop/mapred-site.xml
[root@host2 hadoop-2.5.0-cdh5.3.6]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
<configuration>
<!-- 指定MapReduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置历史服务器端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-senior02.ibeifeng.com:10020</value>
</property>
<!-- 开历史服务器的WEB UI界面 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-senior02.ibeifeng.com:19888</value>
</property>
</configuration>
3.2.5 etc/hadoop/salves
说明:配置在从节点DataNode的位置,直接添加主机名
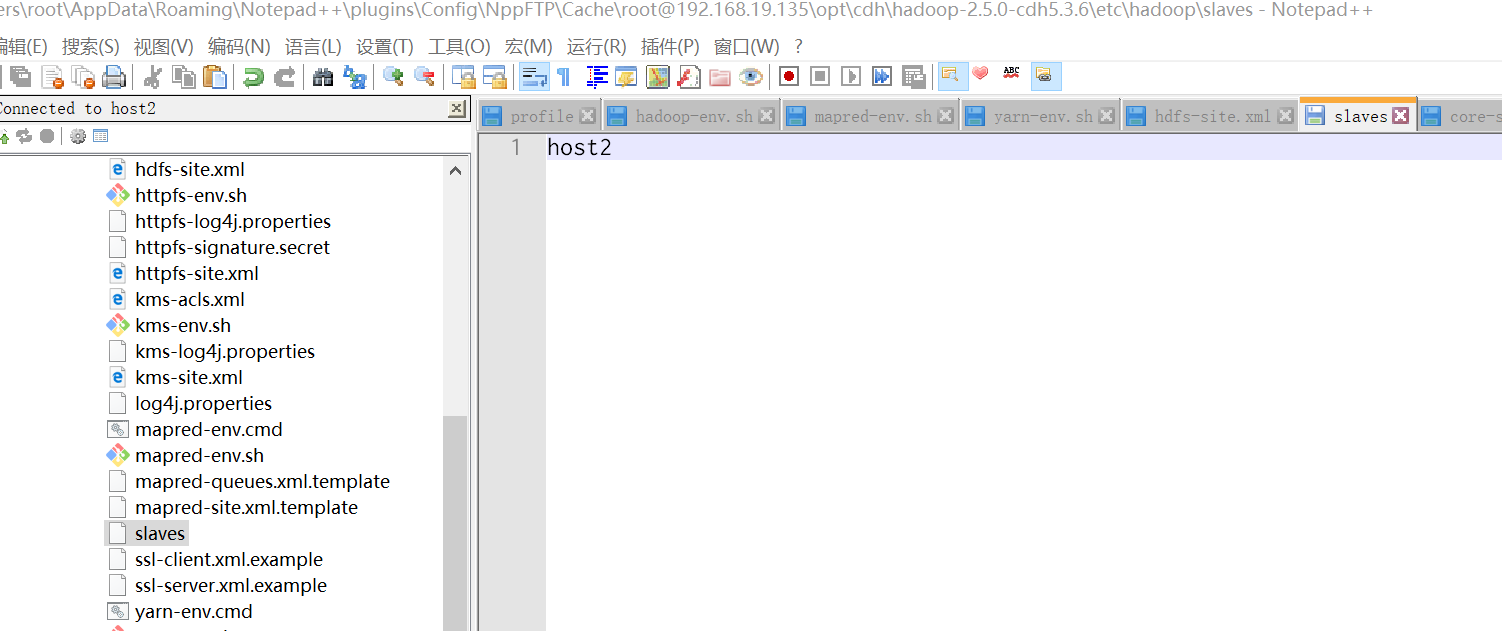
4 启动HDFS文件系统测试读写文件
4.1 格式化HDFS文件系统
[root@host2 ~]# cd /opt/cdh/
[root@host2 cdh]# ls
hadoop-2.5.0-cdh5.3.6
[root@host2 cdh]# cd hadoop-2.5.0-cdh5.3.6/
[root@host2 hadoop-2.5.0-cdh5.3.6]# ls
bin bin-mapreduce1 cloudera etc examples examples-mapreduce1 include lib libexec sbin share src
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs namenode -format
18/06/03 10:57:06 INFO namenode.NameNode: STARTUP_MSG:
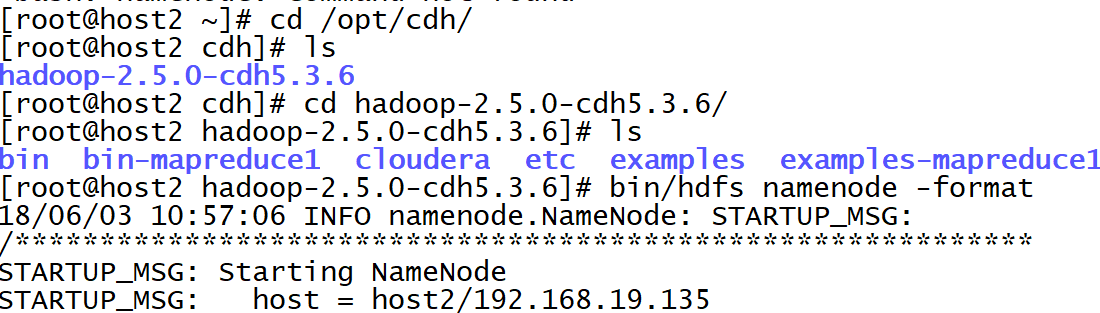
格式化成功
4.2 启动namenode和datanote
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/cdh/hadoop-2.5.0-cdh5.3.6/logs/hadoop-root-namenode-host2.out
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/cdh/hadoop-2.5.0-cdh5.3.6/logs/hadoop-root-datanode-host2.out
[root@host2 hadoop-2.5.0-cdh5.3.6]# jps
1255 Jps
1184 DataNode
1109 NameNode

4.3 登陆HDFS的WEB界面
端口号:50070
登陆WEB:http://host2:50070/explorer.html#/
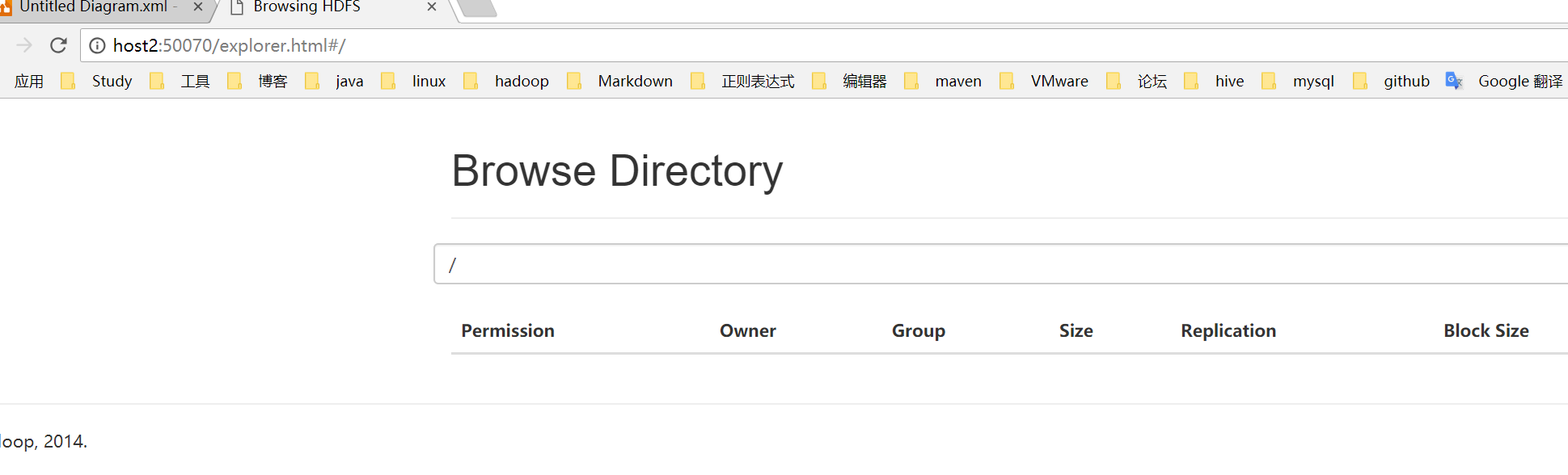
5 文件操作
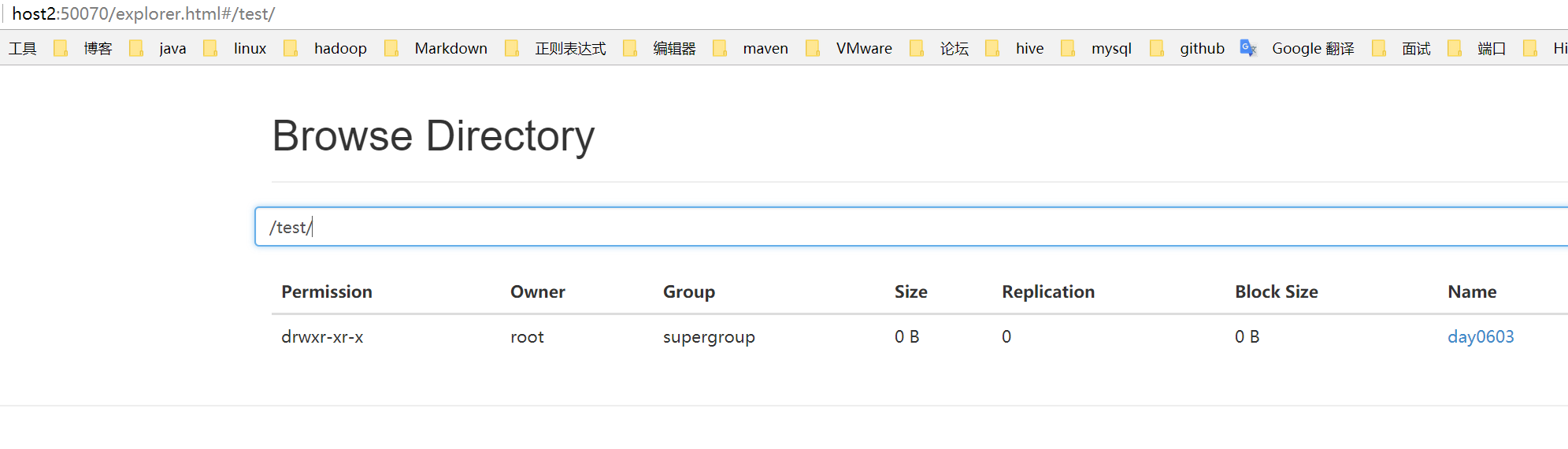
5.1 创建目录
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -mkdir -p /test/day0603
5.2 上传文件
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -put hdfs/060318-TheWolfAndTheDog.txt /test/day0603
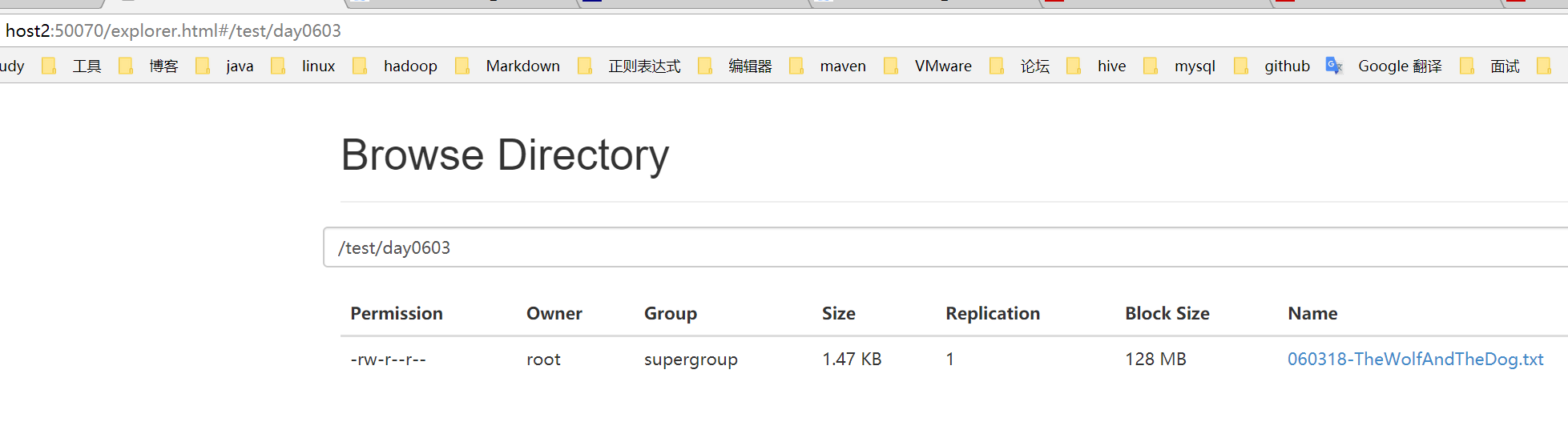
5.3 读取文件
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -cat /test/day0603/060318-TheWolfAndTheDog.txt

5.4 启动yarn并开启历史服务器
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/yarn-daemon.sh start nodemanager
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/yarn-daemon.sh start resourcemanager
[root@host2 hadoop-2.5.0-cdh5.3.6]# sbin/mr-jobhistory-daemon.sh start historyserver #启动历史服务器
yarn管理界面
6 运行MapReduce WordCount程序
6.1 找到hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar

6.2 使用jar
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /test/day0603/060318-TheWolfAndTheDog.txt /test/output0603-1
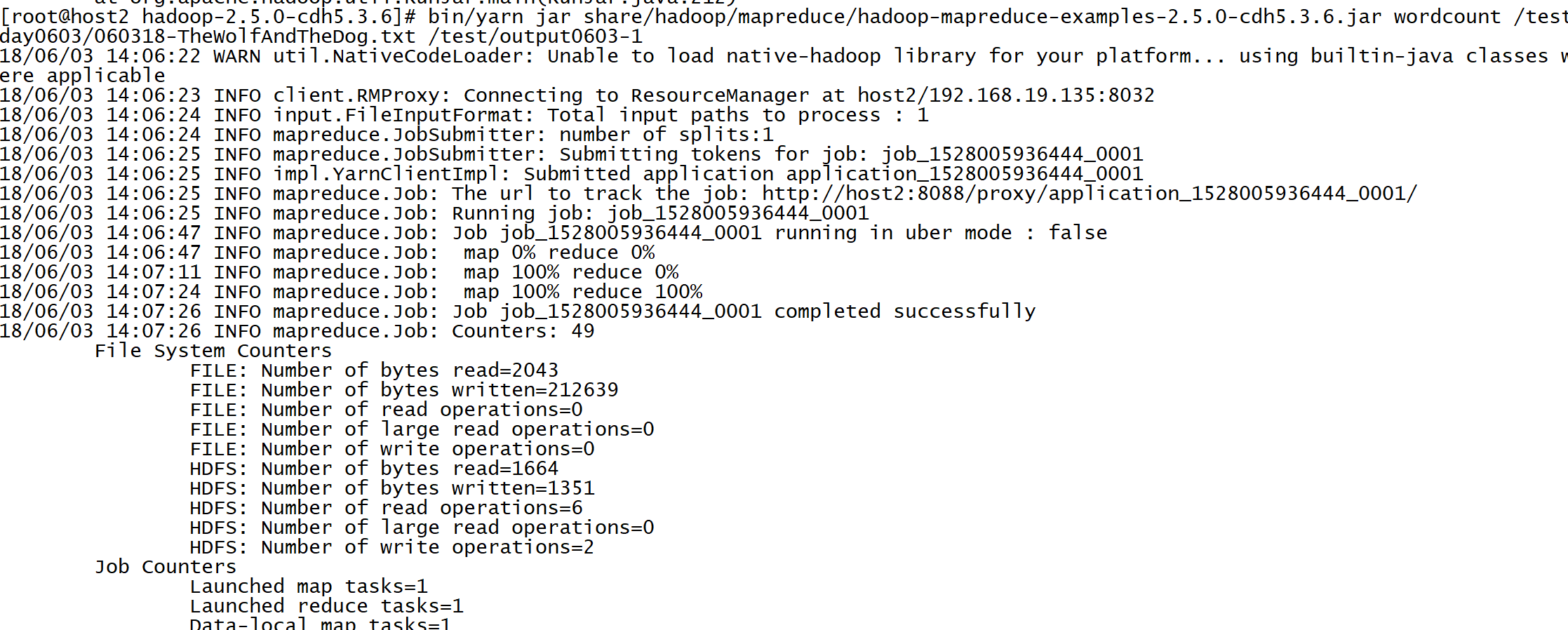
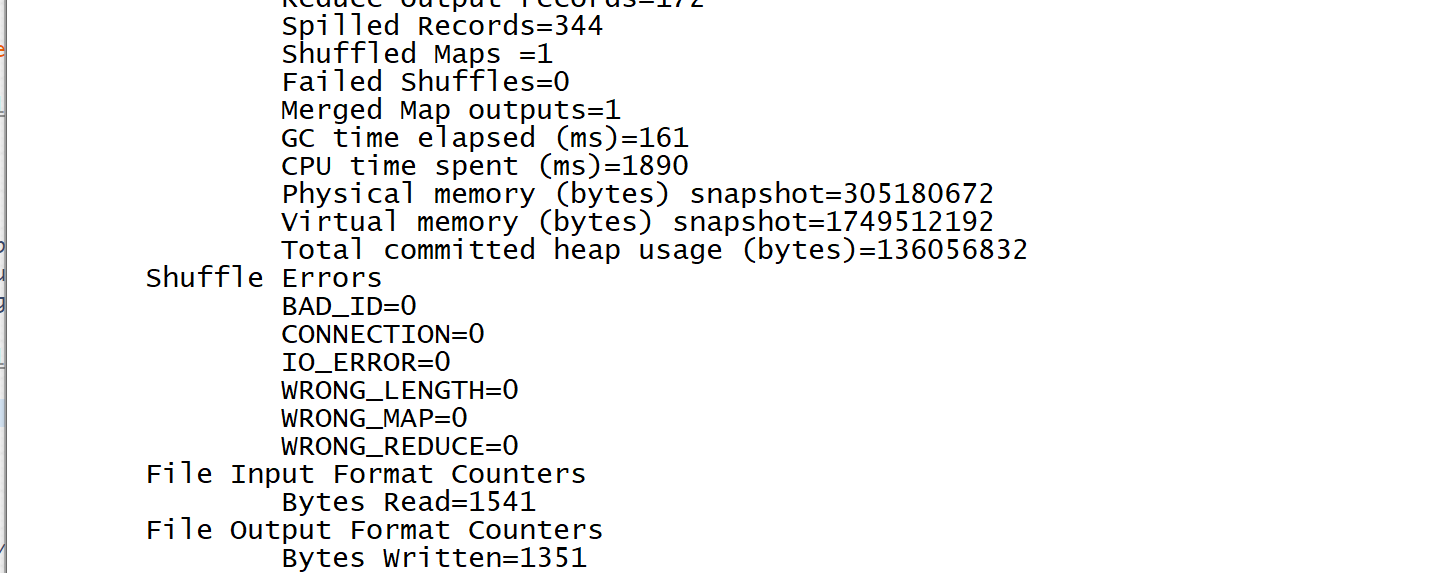
6.3 查看结果
[root@host2 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -text /test/output0603-1/part*
18/06/03 14:10:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
After 1
Are 1
As 2
Asks 1
Come 1
He 2
I 12
If 1
In 2
It’s 1
I’m 3
My 1
MapReduce 会针对key进行排序