参考:
https://blog.csdn.net/kongtiao5/article/details/82771694
https://www.cnblogs.com/xichji/p/11286443.html
https://blog.csdn.net/zeb_perfect/article/details/54135506
https://blog.csdn.net/huxianbo0807/article/details/102912172
https://blog.csdn.net/lavorange/article/details/83475960
缓存穿透、缓存击穿、缓存雪崩区别和解决方案
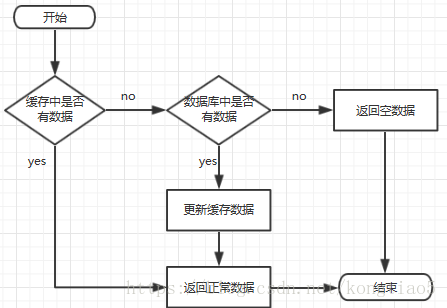
一、缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
二、缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
三、缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
- 设置热点数据永远不过期。
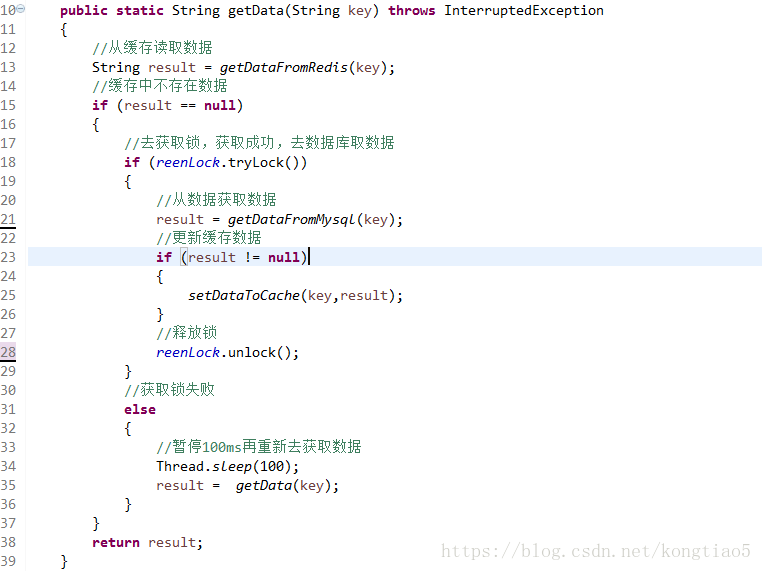
- 加互斥锁,互斥锁参考代码如下:
说明:
1)缓存中有数据,直接走上述代码13行后就返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据key值加锁就更好了,就是线程A从数据库取key1的数据并不妨碍线程B取key2的数据,上面代码明显做不到这点。
四、缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
REDIS缓存穿透,缓存击穿,缓存雪崩原因+解决方案
一、前言
在我们日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
为了克服上述的问题,项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。
redis技术就是NoSQL技术中的一种,但是引入redis又有可能出现缓存穿透,缓存击穿,缓存雪崩等问题。本文就对这三种问题进行较深入剖析。
二、初认识
- 缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
- 缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
- 缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
三、缓存穿透解决方案
一个一定不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
粗暴方式伪代码:
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
}
cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//数据库查询不到,为空
cacheValue = GetProductListFromDB();
if (cacheValue == null) {
//如果发现为空,设置个默认值,也缓存起来
cacheValue = string.Empty;
}
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
return cacheValue;
}
}四、缓存击穿解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}memcache代码:
if (memcache.get(key) == null) {
// 3 min timeout to avoid mutex holder crash
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
}其它方案:待各位补充。
五、缓存雪崩解决方案
与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key。
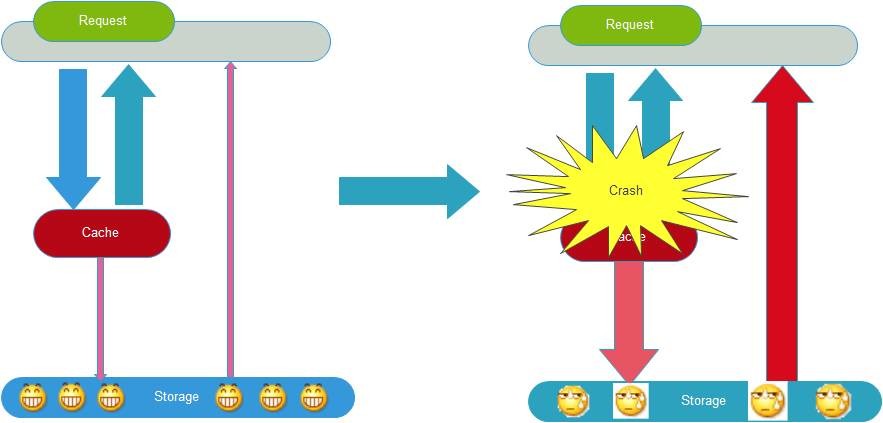
缓存正常从Redis中获取,示意图如下:
缓存失效瞬间示意图如下:
缓存失效时的雪崩效应对底层系统的冲击非常可怕!大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
加锁排队,伪代码如下:
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String lockKey = cacheKey;
String cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
synchronized(lockKey) {
cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//这里一般是sql查询数据
cacheValue = GetProductListFromDB();
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
}
}
return cacheValue;
}
}加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法!
注意:加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
随机值伪代码:
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
//缓存标记
String cacheSign = cacheKey + "_sign";
String sign = CacheHelper.Get(cacheSign);
//获取缓存值
String cacheValue = CacheHelper.Get(cacheKey);
if (sign != null) {
return cacheValue; //未过期,直接返回
} else {
CacheHelper.Add(cacheSign, "1", cacheTime);
ThreadPool.QueueUserWorkItem((arg) -> {
//这里一般是 sql查询数据
cacheValue = GetProductListFromDB();
//日期设缓存时间的2倍,用于脏读
CacheHelper.Add(cacheKey, cacheValue, cacheTime * 2);
});
return cacheValue;
}
} 解释说明:
- 缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存;
- 缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
关于缓存崩溃的解决方法,这里提出了三种方案:使用锁或队列、设置过期标志更新缓存、为key设置不同的缓存失效时间,还有一种被称为“二级缓存”的解决方法。
六、小结
针对业务系统,永远都是具体情况具体分析,没有最好,只有最合适。
于缓存其它问题,缓存满了和数据丢失等问题,大伙可自行学习。最后也提一下三个词LRU、RDB、AOF,通常我们采用LRU策略处理溢出,Redis的RDB和AOF持久化策略来保证一定情况下的数据安全。
参考相关链接:
https://blog.csdn.net/zeb_perfect/article/details/54135506
https://blog.csdn.net/fanrenxiang/article/details/80542580
https://baijiahao.baidu.com/s?id=1619572269435584821&wfr=spider&for=pc
https://blog.csdn.net/xlgen157387/article/details/79530877
视频资源获取,可直进百度云群:
https://pan.baidu.com/mbox/homepage?short=btNBJoN
本文在米兜公众号链接
https://mp.weixin.qq.com/s/ksVC1049wZgPIOy2gGziNA
缓存雪崩问题及处理方案
一、什么是缓存雪崩
- 保证缓存层服务高可用性
- 对缓存访问进行资源隔离(熔断)、Fail Silent 降级
- ehcache本地缓存
- 对源服务访问进行限流、资源隔离(熔断)、Stubbed 降级。
- Redis数据备份和恢复
- 快速缓存预热
如何解决Redis缓存雪崩、缓存穿透、缓存并发等5大难题
01.缓存雪崩
数据未加载到缓存中,或者缓存同一时间大面积的失效,从而导致所有请求都去查数据库,导致数据库CPU和内存负载过高,甚至宕机。
比如一个雪崩的简单过程:
1、redis集群大面积故障
2、缓存失效,但依然大量请求访问缓存服务redis
3、redis大量失效后,大量请求转向到mysql数据库
4、mysql的调用量暴增,很快就扛不住了,甚至直接宕机
5、由于大量的应用服务依赖mysql和redis的服务,这个时候很快会演变成各服务器集群的雪崩,***网站彻底崩溃。
02.缓存雪崩解决方案
1.缓存的高可用性
缓存层设计成高可用,防止缓存大面积故障。即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如 Redis Sentinel 和 Redis Cluster 都实现了高可用。
2.缓存降级
可以利用ehcache等本地缓存(暂时使用),但主要还需要对源服务访问进行限流、资源隔离(熔断)、降级等。
当访问量剧增、服务出现问题仍然需要保证服务还是可用的。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级,这里会涉及到运维的配合。
降级的最终目的是保证核心服务可用,即使是有损的。
比如我的淘宝页面,由于是非核心页面,后端服务如果暂时不能提供使用的情况,可以考虑直接使用一个静态页面替换掉,这样对于用户也是永远提供服务的状态(再发报警信息提示急需解决),也不至于出现空白或者异常错误的裸奔状态。
在进行降级之前要对系统进行梳理,比如:哪些业务是核心(必须保证),哪些业务可以容许暂时不提供服务(利用静态页面替换)等,以及配合服务器核心指标,来后设置整体预案,比如:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的***阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
3.Redis备份和快速预热
1)Redis数据备份和恢复
2)快速缓存预热
3).提前演练
***,建议还是在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,对高可用提前预演,提前发现问题。
03.缓存穿透
缓存穿透是指查询一个一不存在的数据。例如:从缓存redis没有***,需要从mysql数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
解决思路:
如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。设置一个过期时间或者当有值的时候将缓存中的值替换掉即可。
可以给key设置一些格式规则,然后查询之前先过滤掉不符合规则的Key。
04.缓存并发
这里的并发指的是多个redis的client同时set key引起的并发问题。其实redis自身就是单线程操作,多个client并发操作,按照先到先执行的原则,先到的先执行,其余的阻塞。当然,另外的解决方案是把redis.set操作放在队列中使其串行化,必须的一个一个执行。
05.缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。
这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
解决思路:
1、直接写个缓存刷新页面,上线时手工操作下。
2、数据量不大,可以在项目启动的时候自动进行加载。
目的就是在系统上线前,将数据加载到缓存中。
Redis大Key优化
最近在使用redis存储数据的时候造成了大key的问题,被运维同学挑战,所谓的大key就是存储本身的key值空间太大,或者hash,list,set等存储中value值过多。
业务场景:
即通过hash的方式来存储每一天用户订单次数。那么key = order_20181010, field = order_id, value = 10。那么如果一天有百万千万甚至上亿订单的时候,key后面的值是很多,存储空间也很大,造成所谓的大key。
大key的风险:
1.读写大key会导致超时严重,甚至阻塞服务。
2.如果删除大key,DEL命令可能阻塞Redis进程数十秒,使得其他请求阻塞,对应用程序和Redis集群可用性造成严重的影响。
3.建议每个key不要超过M级别。
简单的解决问题:
将大key进行分割,为了均匀分割,可以对field进行hash并通过质数N取余,将余数加到key上面,我们取质数N为997。
那么新的key则可以设置为:
newKey = order_20181010_String.valueOf( Math.abs(order_id.hashcode() % 997) )
field = order_id
value = 10
hset (newKey, field, value) ;
hget(newKey, field)
Redis Value过大问题 键值过大
Redis Big Key问题
数据量大的 key ,由于其数据大小远大于其他key,导致经过分片之后,某个具体存储这个 big key 的实例内存使用量远大于其他实例,造成内存不足,拖累整个集群的使用。big key 在不同业务上,通常体现为不同的数据,比如:
- 论坛中的大型持久盖楼活动;
- 聊天室系统中热门聊天室的消息列表;
带来的问题
bigkey 通常会导致内存空间不平衡,超时阻塞,如果 key 较大,redis 又是单线程,操作 bigkey 比较耗时,那么阻塞 redis 的可能性增大。每次获取 bigKey 的网络流量较大,假设一个 bigkey 为 1MB,每秒访问量为 1000,那么每秒产生 1000MB 的流量,对于普通千兆网卡,按照字节算 128M/S 的服务器来说可能扛不住。而且一般服务器采用单机多实例方式来部署,所以还可能对其他实例造成影响。
- 如果是集群模式下,无法做到负载均衡,导致请求倾斜到某个实例上,而这个实例的QPS会比较大,内存占用也较多;对于Redis单线程模型又容易出现CPU瓶颈,当内存出现瓶颈时,只能进行纵向库容,使用更牛逼的服务器。
- 涉及到大key的操作,尤其是使用hgetall、lrange、get、hmget 等操作时,网卡可能会成为瓶颈,也会到导致堵塞其它操作,qps 就有可能出现突降或者突升的情况,趋势上看起来十分不平滑,严重时会导致应用程序连不上,实例或者集群在某些时间段内不可用的状态。
- 假如这个key需要进行删除操作,如果直接进行DEL 操作,被操作的实例会被Block住,导致无法响应应用的请求,而这个Block的时间会随着key的变大而变长。
什么是 big key
- 字符串类型:一般认为超过 10k 的就是 bigkey,但是这个值和具体的 OPS 相关。
- 非字符串类型:体现在哈希,列表,集合类型元素过多。
寻找big key
-
redis-cli自带
--bigkeys。1 2
$ redis-cli -p 999 --bigkeys -i 0.1 #Scanning the entire keyspace to find biggest keys as well as average sizes per key type. You can use -i 0.1 to sleep 0.1 sec per 100 SCAN commands (not usually needed).
-
获取生产Redis的rdb文件,通过rdbtools分析rdb生成csv文件,再导入MySQL或其他数据库中进行分析统计,根据size_in_bytes统计bigkey
1 2 3 4
$ git clone https://github.com/sripathikrishnan/redis-rdb-tools $ cd redis-rdb-tools $ sudo python setup.py install $ rdb -c memory dump-10030.rdb > memory.csv
-
通过python脚本,迭代scan key,每次scan 1000,对扫描出来的key进行类型判断,例如:string长度大于10K,list长度大于10240认为是big bigkeys
-
其他第三方工具,例如:redis-rdb-cli
优化big key
优化big key的原则就是string减少字符串长度,list、hash、set、zset等减少成员数。
-
string类型的big key,建议不要存入redis,用文档型数据库MongoDB代替或者直接缓存到CDN上等方式优化。有些 key 不只是访问量大,数据量也很大,这个时候就要考虑这个 key 使用的场景,存储在redis集群中是否是合理的,是否使用其他组件来存储更合适;如果坚持要用 redis 来存储,可能考虑迁移出集群,采用一主一备(或1主多备)的架构来存储。
-
单个简单的key存储的value很大
该对象需要每次都整存整取: 可以尝试将对象分拆成几个key-value, 使用multiGet获取值,这样分拆的意义在于分拆单次操作的压力,将操作压力平摊到多个redis实例中,降低对单个redis的IO影响;
该对象每次只需要存取部分数据: 可以像第一种做法一样,分拆成几个key-value,也可以将这个存储在一个hash中,每个field代表一个具体的属性,使用hget,hmget来获取部分的value,使用hset,hmset来更新部分属性。 -
hash, set,zset,list 中存储过多的元素
可以将这些元素分拆。以hash为例,原先的正常存取流程是 hget(hashKey, field) ; hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000, 每次存取的时候,先在本地计算field的hash值,模除 10000,确定了该field落在哪个key上。
1 2 3 |
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value) ; hget(newHashKey, field) |
set, zset, list 也可以类似上述做法。但有些不适合的场景,比如,要保证 lpop 的数据的确是最早push到list中去的,这个就需要一些附加的属性,或者是在 key的拼接上做一些工作(比如list按照时间来分拆)