参考:
https://blog.csdn.net/u011109881/article/details/80379505
https://blog.csdn.net/duan19920101/article/details/51579136
todo
https://blog.csdn.net/weixin_39084521/article/details/90735067
数据结构 Hash表(哈希表)
参考链接:数据结构(严蔚敏)
一、什么是Hash表
要想知道什么是哈希表,那得先了解哈希函数
哈希函数
对比之前博客讨论的二叉排序树 二叉平衡树 红黑树 B B+树,它们的查找都是先从根节点进行查找,从节点取出数据或索引与查找值进行比较。那么,有没有一种函数H,根据这个函数和查找关键字key,可以直接确定查找值所在位置,而不需要一个个比较。这样就**“预先知道”**key所在的位置,直接找到数据,提升效率。
即
地址index=H(key)
说白了,hash函数就是根据key计算出应该存储地址的位置,而哈希表是基于哈希函数建立的一种查找表
二、哈希函数的构造方法
根据前人经验,统计出如下几种常用hash函数的构造方法:
直接定制法
哈希函数为关键字的线性函数如 H(key)=a*key+b
这种构造方法比较简便,均匀,但是有很大限制,仅限于地址大小=关键字集合的情况
使用举例:
假设需要统计中国人口的年龄分布,以10为最小单元。今年是2018年,那么10岁以内的分布在2008-2018,20岁以内的分布在1998-2008……假设2018代表2018-2008直接的数据,那么关键字应该是2018,2008,1998……
那么可以构造哈希函数H(key)=(2018-key)/10=201-key/10
那么hash表建立如下
| index | key | 年龄 | 人数(假设数据) |
| 0 | 2018 | 0-10 | 200W |
| 1 | 2008 | 10-20 | 250W |
| 2 | 1998 | 20-30 | 253W |
| 3 | 1988 | 30-40 | 300W |
| …… |
数字分析法
假设关键字集合中的每个关键字key都是由s位数字组成(k 1 , k 2 , … … , k n k_1,k_2,……,k_nk1,k2,……,kn),分析key中的全体数据,并从中提取分布均匀的若干位或他们的组合构成全体
使用举例
我们知道身份证号是有规律的,现在我们要存储一个班级学生的身份证号码,假设这个班级的学生都出生在同一个地区,同一年,那么他们的身份证的前面数位都是相同的,那么我们可以截取后面不同的几位存储,假设有5位不同,那么就用这五位代表地址。
H(key)=key%100000
此种方法通常用于数字位数较长的情况,必须数字存在一定规律,其必须知道数字的分布情况,比如上面的例子,我们事先知道这个班级的学生出生在同一年,同一个地区。
平方取中法
如果关键字的每一位都有某些数字重复出现频率很高的现象,可以先求关键字的平方值,通过平方扩大差异,而后取中间数位作为最终存储地址。
使用举例
比如key=1234 1234^2=1522756 取227作hash地址
比如key=4321 4321^2=18671041 取671作hash地址
这种方法适合事先不知道数据并且数据长度较小的情况
折叠法
如果数字的位数很多,可以将数字分割为几个部分,取他们的叠加和作为hash地址
使用举例
比如key=123 456 789
我们可以存储在61524,取末三位,存在524的位置
该方法适用于数字位数较多且事先不知道数据分布的情况
除留余数法用的较多
H(key)=key MOD p (p<=m m为表长)
很明显,如何选取p是个关键问题。
使用举例
比如我们存储3 6 9,那么p就不能取3
因为 3 MOD 3 == 6 MOD 3 == 9 MOD 3
p应为不大于m的质数或是不含20以下的质因子的合数,这样可以减少地址的重复(冲突)
比如key = 7,39,18,24,33,21时取表长m为9 p为7 那么存储如下
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| key | 7 | 21(冲突后移) | 24 | 4 | 18(冲突后移) | 33冲突后移) |
**随机数法** H(key) =Random(key) 取关键字的随机函数值为它的散列地址
hash函数设计的考虑因素
1.计算散列地址所需要的时间(即hash函数本身不要太复杂)
2.关键字的长度
3.表长
4.关键字分布是否均匀,是否有规律可循
5.设计的hash函数在满足以上条件的情况下尽量减少冲突
三、哈希冲突
即不同key值产生相同的地址,H(key1)=H(key2)
比如我们上面说的存储3 6 9,p取3是
3 MOD 3 == 6 MOD 3 == 9 MOD 3
此时3 6 9都发生了hash冲突
哈希冲突的解决方案
不管hash函数设计的如何巧妙,总会有特殊的key导致hash冲突,特别是对动态查找表来说。
hash函数解决冲突的方法有以下几个常用的方法
1.开放定制法
2.链地址法
3.公共溢出区法
建立一个特殊存储空间,专门存放冲突的数据。此种方法适用于数据和冲突较少的情况。
4.再散列法
准备若干个hash函数,如果使用第一个hash函数发生了冲突,就使用第二个hash函数,第二个也冲突,使用第三个……
重点了解一下开放定制法和链地址法
开放定制法
首先有一个H(key)的哈希函数
如果H(key1)=H(keyi)
那么keyi存储位置H i = ( H ( k e y ) + d i ) M O D m H_i=(H(key)+d_i)MOD mHi=(H(key)+di)MODmm为表长
d i d_idi有三种取法
1)线性探测再散列
d i = c ∗ i d_i=c*idi=c∗i
2)平方探测再散列
d i = 1 2 , − 1 2 , 2 2 , − 2 2 d_i=1^2,-1^2,2^2,-2^2di=12,−12,22,−22……
3)随机探测在散列(双探测再散列)
d i d_idi是一组伪随机数列
注意
增量di应该具有以下特点(完备性):产生的Hi(地址)均不相同,且所产生的s(m-1)个Hi能覆盖hash表中的所有地址
- 平方探测时表长m必须为4j+3的质数(平方探测表长有限制)
- 随机探测时m和di没有公因子(随机探测di有限制)
三种开放定址法解决冲突方案的例子
废话不多说,上例子就明白了
有一组数据
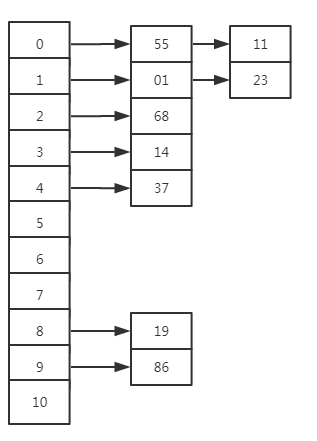
19 01 23 14 55 68 11 86 37要存储在表长11的数组中,其中H(key)=key MOD 11
那么按照上面三种解决冲突的方法,存储过程如下:
(表格解释:从前向后插入数据,如果插入位置已经占用,发生冲突,冲突的另起一行,计算地址,直到地址可用,后面冲突的继续向下另起一行。最终结果取最上面的数据(因为是最“占座”的数据))
线性探测再散列
我们取di=1,即冲突后存储在冲突后一个位置,如果仍然冲突继续向后
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| key | 55 | 1 | 14 | 19 | 86 | ||||||
| 23冲突 | 23 | ||||||||||
| 68冲突 | 68冲突 | 68 | |||||||||
| 11冲突 | 11冲突 | 11冲突 | 11冲突 | 11冲突 | 11 | ||||||
| 37冲突 | 37冲突 | 37 | |||||||||
| 最终存储结果 | 55 | 1 | 23 | 14 | 68 | 11 | 37 | 19 | 86 |
**平方探测再散列**
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| key | 55 | 1 | 14 | 37 | 19 | 86 | |||||
| 23冲突 | H(23)+1 | ||||||||||
| H(68)-1冲突 | 68冲突 | H(68)+1冲突 | H(68)+4 | ||||||||
| 11冲突 | H(11)+1冲突 | H(11)-1 | |||||||||
| 最终存储结果 | 55 | 1 | 23 | 14 | 37 | 68 | 19 | 86 | 11 |
**随机探测在散列(双探测再散列)** 发生冲突后 H(key)‘=(H(key)+di)MOD m 在该例子中 H(key)=key MOD 11 我们取di=key MOD 10 +1 则有如下结果:
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| key | 55 | 1 | 68 | 14 | 19 | 86 | |||||
| 23冲突 | H(23)+3+1 | ||||||||||
| 11冲突 | H(11)+1+1冲突 | H(11)+1+1+1+1 | |||||||||
| (H(37)+8)模11冲突 | 37冲突 | (H(37)+8+8+8)模11 | (H(37)+8+8)模11冲突 | ||||||||
| 最终存储结果 | 55 | 1 | 68 | 14 | 23 | 11 | 37 | 19 | 86 |
链地址法
产生hash冲突后在存储数据后面加一个指针,指向后面冲突的数据
上面的例子,用链地址法则是下面这样:
四、hash表的查找
查找过程和造表过程一致,假设采用开放定址法处理冲突,则查找过程为:
对于给定的key,计算hash地址index = H(key)
如果数组arr【index】的值为空 则查找不成功
如果数组arr【index】== key 则查找成功
否则 使用冲突解决方法求下一个地址,直到arr【index】== key或者 arr【index】==null
hash表的查找效率
决定hash表查找的ASL因素:
1)选用的hash函数
2)选用的处理冲突的方法
3)hash表的饱和度,装载因子 α=n/m(n表示实际装载数据长度 m为表长)
一般情况,假设hash函数是均匀的,则在讨论ASL时可以不考虑它的因素
hash表的ASL是处理冲突方法和装载因子的函数
前人已经证明,查找成功时如下结果:
可以看到无论哪个函数,装载因子越大,平均查找长度越大,那么装载因子α越小越好?也不是,就像100的表长只存一个数据,α是小了,但是空间利用率不高啊,这里就是时间空间的取舍问题了。通常情况下,认为α=0.75是时间空间综合利用效率最高的情况。

上面的这个表可是特别有用的。假设我现在有10个数据,想使用链地址法解决冲突,并要求平均查找长度<2
那么有1+α/2 <2
α<2
即 n/m<2 (n=10)
m>10/2
m>5 即采用链地址法,使得平均查找长度< 2 那么m>5
之前我的博客讨论过各种树的平均查找长度,他们都是基于存储数据n的函数,而hash表不同,他是基于装载因子的函数,也就是说,当数据n增加时,我可以通过增加表长m,以维持装载因子不变,确保ASL不变。
那么hash表的构造应该是这样的:

五、hash表的删除
首先链地址法是可以直接删除元素的,但是开放定址法是不行的,拿前面的双探测再散列来说,假如我们删除了元素1,将其位置置空,那 23就永远找不到了。正确做法应该是删除之后置入一个原来不存在的数据,比如-1
哈希表(散列表)原理详解
什么是哈希表?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
记录的存储位置=f(关键字)
这里的对应关系f称为散列函数,又称为哈希(Hash函数),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
哈希表hashtable(key,value) 就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。(或者:把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。)
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
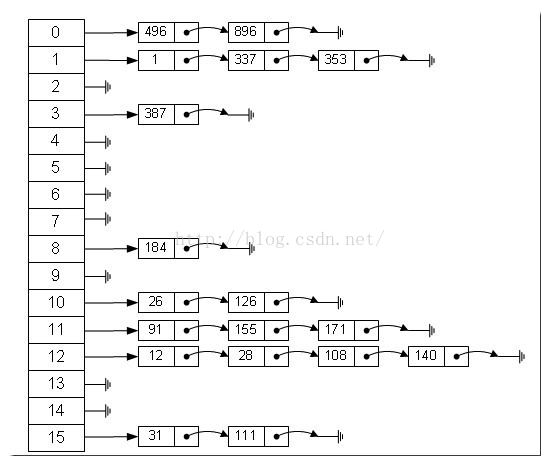
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
Hash的应用
1、Hash主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做Hash值. 也可以说,Hash就是找到一种数据内容和数据存放地址之间的映射关系。
2、查找:哈希表,又称为散列,是一种更加快捷的查找技术。我们之前的查找,都是这样一种思路:集合中拿出来一个元素,看看是否与我们要找的相等,如果不等,缩小范围,继续查找。而哈希表是完全另外一种思路:当我知道key值以后,我就可以直接计算出这个元素在集合中的位置,根本不需要一次又一次的查找!
举一个例子,假如我的数组A中,第i个元素里面装的key就是i,那么数字3肯定是在第3个位置,数字10肯定是在第10个位置。哈希表就是利用利用这种基本的思想,建立一个从key到位置的函数,然后进行直接计算查找。
3、Hash表在海量数据处理中有着广泛应用。
Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。
hash就是找到一种数据内容和数据存放地址之间的映射关系。
散列法:元素特征转变为数组下标的方法。
我想大家都在想一个很严重的问题:“如果两个字符串在哈希表中对应的位置相同怎么办?”,毕竟一个数组容量是有限的,这种可能性很大。解决该问题的方法很多,我首先想到的就是用“链表”。我遇到的很多算法都可以转化成链表来解决,只要在哈希表的每个入口挂一个链表,保存所有对应的字符串就OK了。
散列表的查找步骤
当存储记录时,通过散列函数计算出记录的散列地址
当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录
关键字——散列函数(哈希函数)——散列地址
优点:一对一的查找效率很高;
缺点:一个关键字可能对应多个散列地址;需要查找一个范围时,效果不好。
散列冲突:不同的关键字经过散列函数的计算得到了相同的散列地址。
好的散列函数=计算简单+分布均匀(计算得到的散列地址分布均匀)
哈希表是种数据结构,它可以提供快速的插入操作和查找操作。
优缺点
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即0(1)的时间级。实际上,这只需要几条机器指令。
哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。
如果不需要有序遍历数据,并且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的:
1,除法散列法
最直观的一种,上图使用的就是这种散列法,公式:
index = value % 16
学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫“除法散列法”。
2,平方散列法
求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28 (右移,除以2^28。记法:左移变大,是乘。右移变小,是除。)
如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。也许你还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
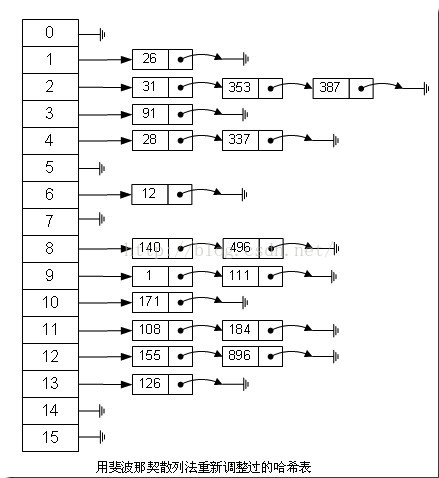
3,斐波那契(Fibonacci)散列法
平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
1,对于16位整数而言,这个乘数是40503
2,对于32位整数而言,这个乘数是2654435769
3,对于64位整数而言,这个乘数是11400714819323198485
这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377, 610, 987, 1597, 2584, 4181, 6765, 10946,…。另外,斐波那契数列的值和太阳系八大行星的轨道半径的比例出奇吻合。
对我们常见的32位整数而言,公式:
index = (value * 2654435769) >> 28
如果用这种斐波那契散列法的话,那上面的图就变成这样了:
注:用斐波那契散列法调整之后会比原来的取摸散列法好很多。
适用范围
快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
基本原理及要点
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
散列冲突的解决方案:
1.建立一个缓冲区,把凡是拼音重复的人放到缓冲区中。当我通过名字查找人时,发现找的不对,就在缓冲区里找。
2.进行再探测。就是在其他地方查找。探测的方法也可以有很多种。
(1)在找到查找位置的index的index-1,index+1位置查找,index-2,index+2查找,依次类推。这种方法称为线性再探测。
(2)在查找位置index周围随机的查找。称为随机在探测。
(3)再哈希。就是当冲突时,采用另外一种映射方式来查找。
这个程序中是通过取模来模拟查找到重复元素的过程。对待重复元素的方法就是再哈希:对当前key的位置+7。最后,可以通过全局变量来判断需要查找多少次。我这里通过依次查找26个英文字母的小写计算的出了总的查找次数。显然,当总的查找次数/查找的总元素数越接近1时,哈希表更接近于一一映射的函数,查找的效率更高。
扩展
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同 时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个 位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例(海量数据处理)
我们知道hash 表在海量数据处理中有着广泛的应用,下面,请看另一道百度面试题:
题目:海量日志数据,提取出某日访问百度次数最多的那个IP。
方案:IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。