- 阅读论文 Optimizing Federated Learning on Non-IID Data with Reinforcement Learning 的笔记
- 如有侵权,请联系作者,将会撤销发布。
主要讲什么
- 提出FAVOR,一个经验驱动控制的框架。
- 智能的选择客户端设备来参与联邦学习中每一轮训练,以抵消数据非独立同分布带啊来的偏差,并提升收敛的速度。
- 使用了deep Q-learning 来学习如何选择每轮参与训练的客户端以最大化一个 鼓励提升正确率并处罚使用更多通信次数的 奖励。
Intro
- 一般联邦学习都是直接随机选取一部分设备参与每轮的训练,以避免由于不稳定的网络状况和straggler设备造成的长尾(long-tailed)等待时间
- FedAvg可能会严重的降低模型的准确性和收敛所需的通信次数
- 而且由于数据非独立同分布,聚合这些不同的模型可能会减慢收敛,并且会降低模型准确性
- 一个设备中的训练数据的分布和训练得到的模型参数之间有内含的联系
这篇文章提出的目标
FAVOR的目标
- 通过学习积极地在每轮选择最好的,可以抵消非独立同分布会带来的偏差的设备集,以加速并稳定联邦学习过程。
选择设备
- 用本地模型参数和共享的全局模型作为状态,从而公平地?选择可能对全局模型有所提升的设备
- 使用基于DQN的强化学习来提高效率和鲁棒性。(在FL的设备选择环节中使用基于DQN的强化学习)
压缩模型参数
- 提出了一个可以压缩模型参数以对状态空间降维
- apply principle component analysis(PCA) to model weights and use the compressed model weights to represent states instead.
- 只根据在第一轮训练(step 2中得到的)的本地模型的参数来计算PCA
# TODO: 看不懂源码,看不懂过程QAQ
非独立同分布的挑战
- 论文中用实验来展现:
- 如果随机选取设备,那么非独立同分布的数据可能会减慢联邦学习的收敛速度。
- 用cluster 算法可以有助于平衡数据分布并加快收敛。
实验过程
- 100个设备下载最初的Global weights(随机生成的)然后根据本地数据执行一个epoch的SGD,获得(w_1^{(k)})
- 对(w_1^{(k)})执行K-Center算法,对100个设备进行聚类,分成了10个组。
- 在每个组里面随机选择一个设备进行联邦学习。
-
结果:
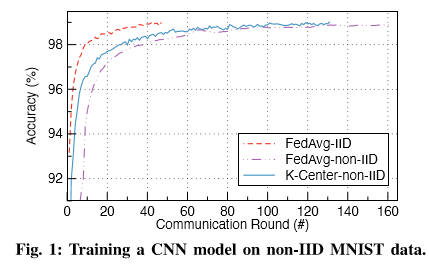
-
这个实验说明了:通过仔细选择每轮参与训练的设备可以提高联邦学习的性能。
用DRL来选择客户端
Agent 基于 Deep Q-Network
- 用DQN来选择k个最合适的设备来参与训练
- 通过一个网络来学习得到(Q^*(s_t,a)),选择(Q^*)最大的k个设备来训练。
- 因为设备中数据非独立同分布的原因,直接随机选择设备来训练效果会不好,所以用这个DQN可以根据每个设备中的模型参数来训练,得到一个选择设备的策略。
- (s_t=(w_t,w_t^{(1)},...,w_t^{(N)}))
- (a): action space为{1,2,...,N}, a=1指选择设备i去参与FL训练
- DQN agent 被训练为要最大化cumulative discounted reward (即R) 的期望。:
- reward: (r_t=Xi ^{(w_t-Omega)}-1)
- (w_t): 在第 t 轮结束后,对held-out validation set(保留验证集)上的测试得出的准确度
- (Omega): 目标准确度
- (Xi ^{(w_t-Omega)}): 激励agent去选择能取得更高准确度(w_t)的设备
- 由于通常随着在机器学习进行,模型准确度的增长速度会变慢,也就是随着t增加,(|w_t-w_{t+1}|)会减小。
- 所以用这样的指数项来放大FL过程靠后阶段中微小的准确度的增长。
- (Xi): 一个正常数,论文中的实验设置为了64
- -1:激励 agent 用更少的训练轮数 (?)
- (R=sum_{t=1}^{T}gamma ^{t-1}r_t)
- 当(w_t=Omega, r_t == 0) 时,联邦学习结束
- reward: (r_t=Xi ^{(w_t-Omega)}-1)
FAVOR过程
- N个可行的设备向FL server报到
-
- 每个设备都从server上下载最初的随机获得的模型参数(w_{init})
- 用 local SGD 训练一个epoch,然后将训练得到的模型参数({w_1^{(k)},k in [N]})传给FL server
-
- 接收到上传的local weights后,对应在server上存的local weights更新
- DQN agent 计算所有设备的(Q(s_t,a; heta))
-
- DQN agent 根据(Q(s_t,a; heta))的大小,选择k个最大Q值对应的k个设备。
- 被选中的k个设备下载最新的global model weights (w_t), 并执行一个epoch的local SGD以获得({w_{t+1}^{(k)}|k in [K]})
- ({w_{t+1}^{(k)}|k in [K]})被传到server,以使用FEDAVG计算(w_{t+1})。重复3-5步直到结束(如达到目标准确率,或者 训练了一定数量的rounds)。
- 论文作者GitHub上还没有给出这部分的代码。
用PCA降维
- 对模型参数使用PCA,然后用压缩后的模型参数来表示states。
- 看不懂这部分代码
用Double DQN 训练Agent
- 使用DDQN来学习函数(Q^*(s_t,a))
- 原来的Q-Learning可能会不稳定
- 而DDQN加入了另一个value function (Q(s,a; heta_t')),这样可以使action-value函数的估计更加稳定