elasticsearch底层技术lucene解析
elasticsearch是一个分布式搜索引擎,其是一个应用工具,面向用户,而其底层技术是用到了一个叫lucene的技术,主要提供了倒排索引来提高索引的效率。下面简单介绍一下倒排索引,既然有倒排索引,那么必定有正排索引,所以先从正排索引开始,然后引出倒排索引。
正排索引:
(1)简介:一般情况下,数据量小的时候可以通过数据库来索引,但是一旦数据很大,数据库索引就会出现一些问题,比如,查询语句的复杂度太高;关键词索引不全面,查询到的内容不符合;查询反应慢,效率低等。所以出现了正排索引,正排索引是将一个Document文档的内容做split切分,切分成不同的关键词,这样搜索就可以通过关键词搜索到
(2)具体实现:每个文件都有一个文件ID,文件内容是多个关键词的集合,其实在搜索引擎中,关键词也已经变成了关键词ID,例如某文档1,其内容包括100个关键词,每个关键词都会记录它在文档中出现的次数以及位置。
字段:
1)Localld字段(表中简称“Lid”):表示一个文档的局部编号。
2)Wordld字段:表示文档分词后的编号,也可称为“索引词编号”。
3)NHits字段:表示某个索引词在文档中出现的次数。
4)HitList变长字段:表示某个索引词在文档中出现的位置,即相对于正文的偏移量。
(3)问题:在使用正排索引的时候,需要先扫描索引库中的所有文档,再找到包含关键词的所有文档,展现出来。这样会带来一个问题,互联网的文档是非常庞大的,如果扫描所有的文档,那么就很难做到实时返回查询结果。所有就有了倒排索引。

由于正排索引的效率问题,出现了下面的倒排索引
倒排索引:
(1)简介:倒排索引将正排索引的文档到关键词的映射变成关键词到文档的映射,每个关键词都有对应的文档,这些文档都包含了这些关键词。
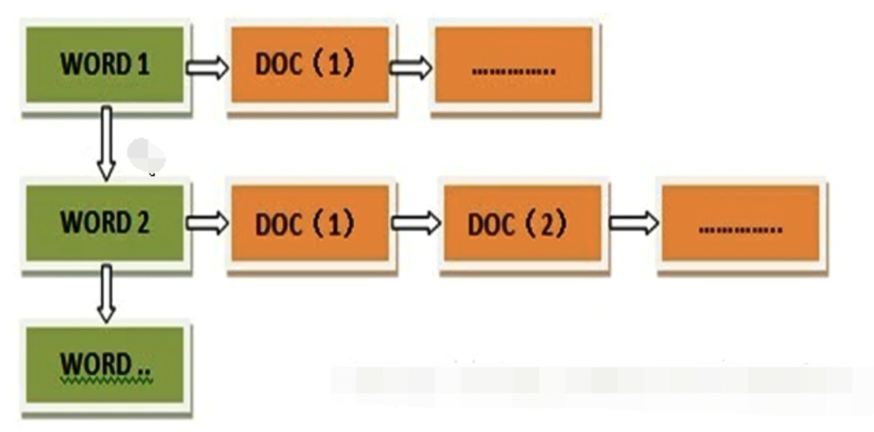
(2)具体实现:文档内容存放在Document文档中,这个文档不止Content内容,还包括了size,path等内容,将Document送到elasticsearch分布式搜索引擎中进行分词过滤,过滤之后生成一个索引文件,index类似于 xs(1:1){1},表示xs在文档1中出现过1次,索引值为1。还会生成一个文件,用来存放docid以及Document内容,其中docid是与index对应的唯一id号,Documnet中的Content内容可以不存放,path是返回的包含关键词的内容的地址。
当client客户端有一个请求搜索,就会到index中找到对应的索引,索引再去找docid,docid中对应了一个path,这个就是最重要的我们最钟找到的结果。这种分布式的搜索引擎加速了查找过程。
