安装方面,配置方面
当使用WINDOWS身份认证后怎么给SA加密码,切换混合模式

.png)





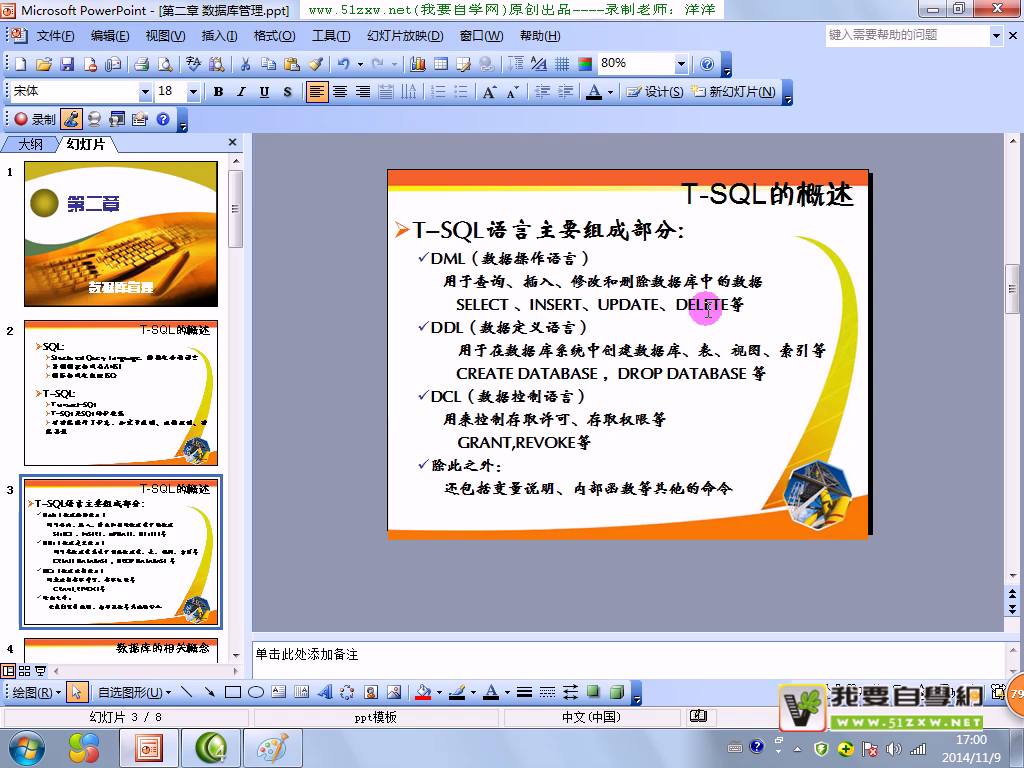
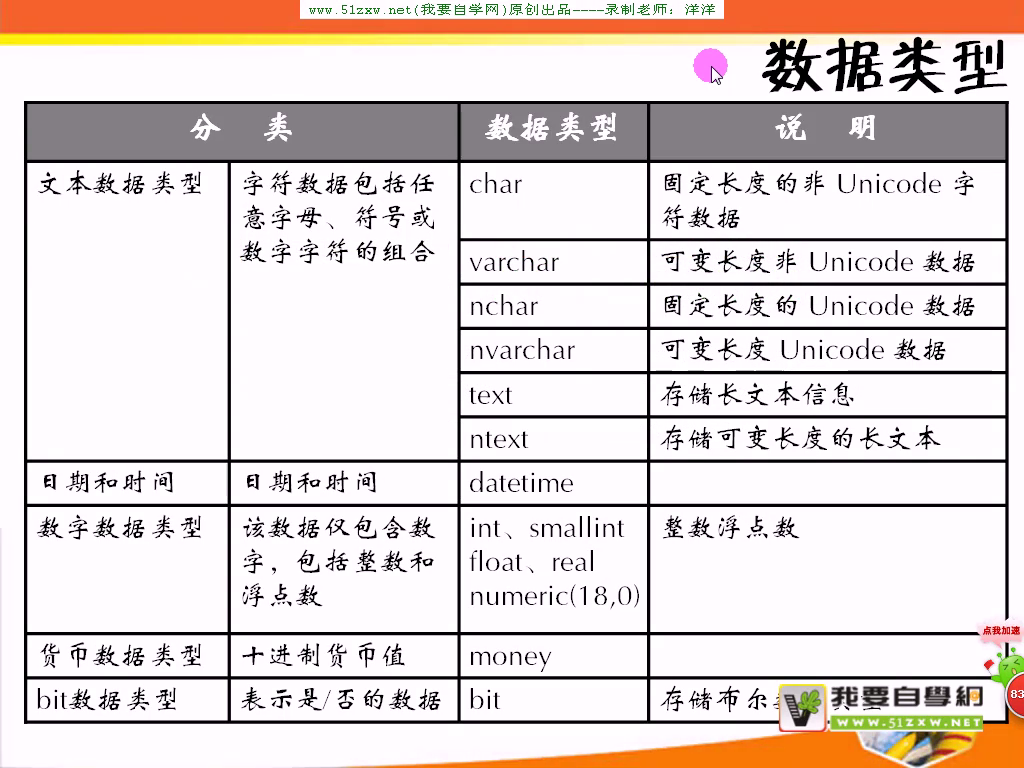
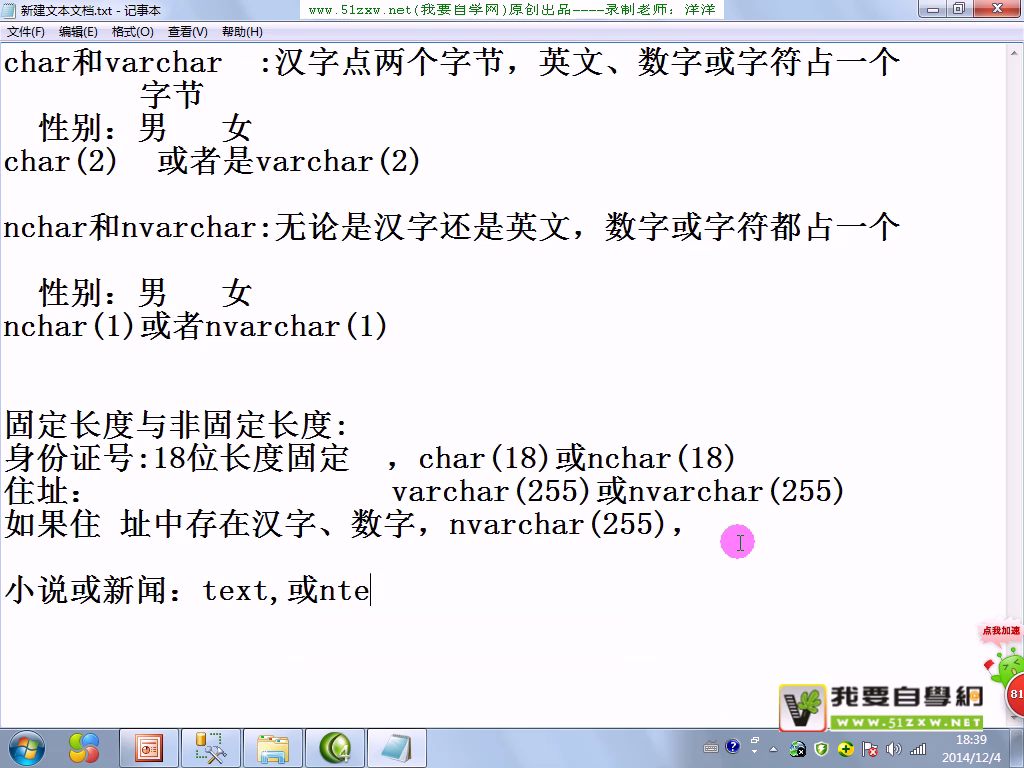
T-SQL的组成部分
数据库的结构

操作数据库
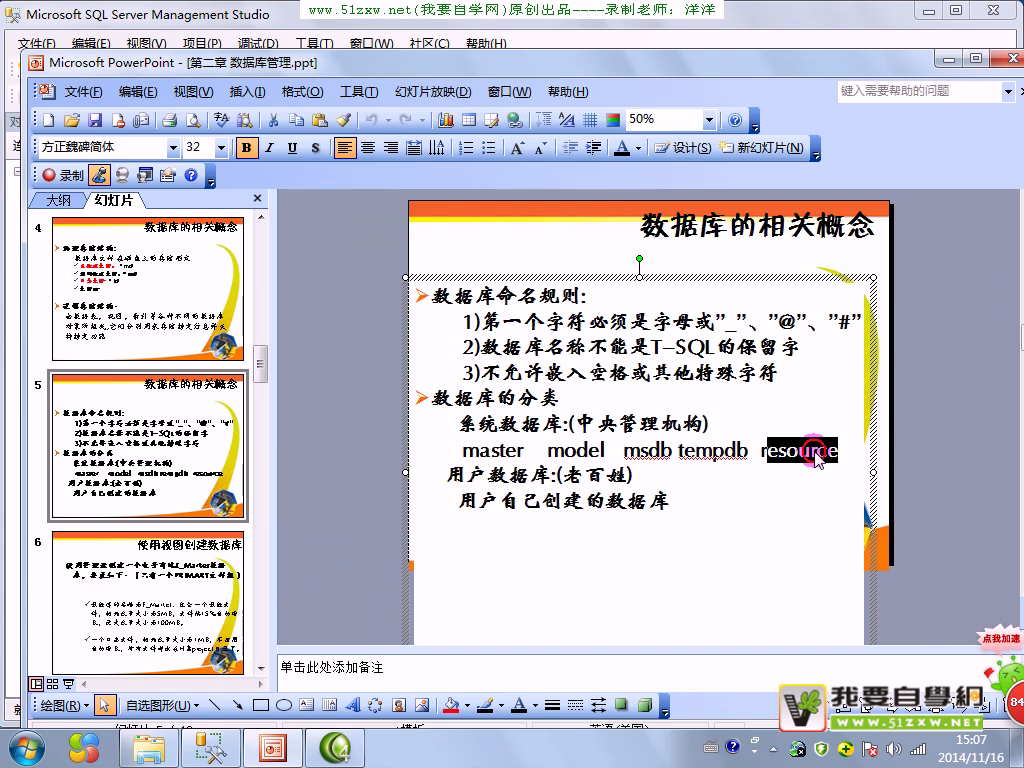
命名规则
限制访问,多用户,单用户

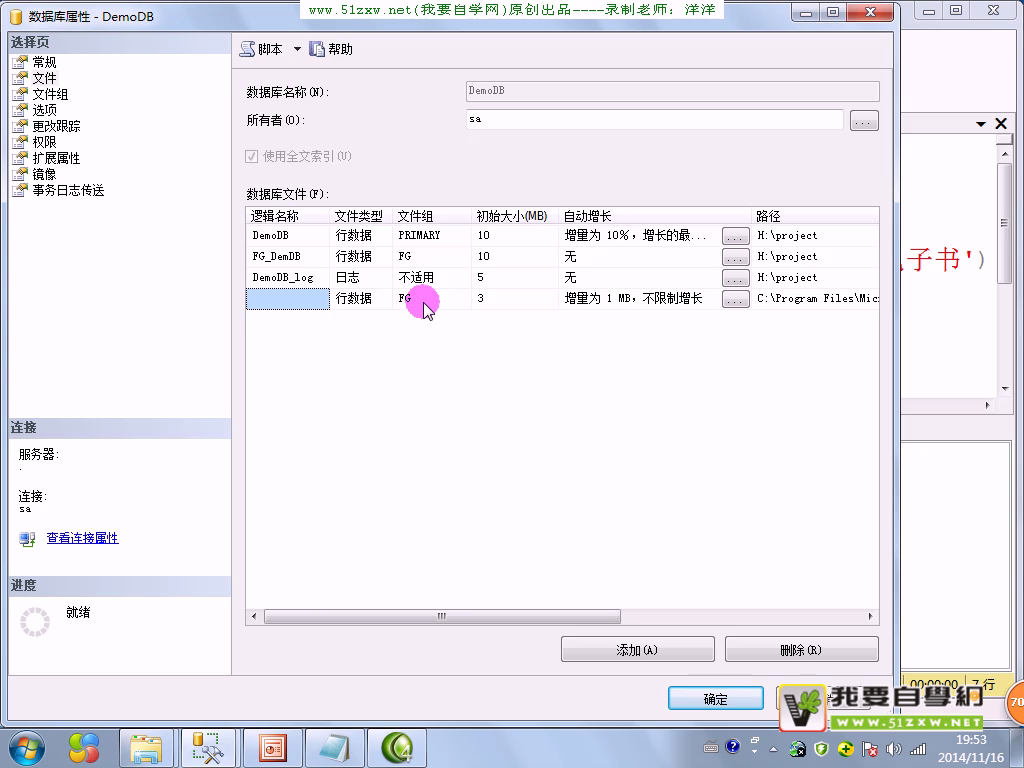
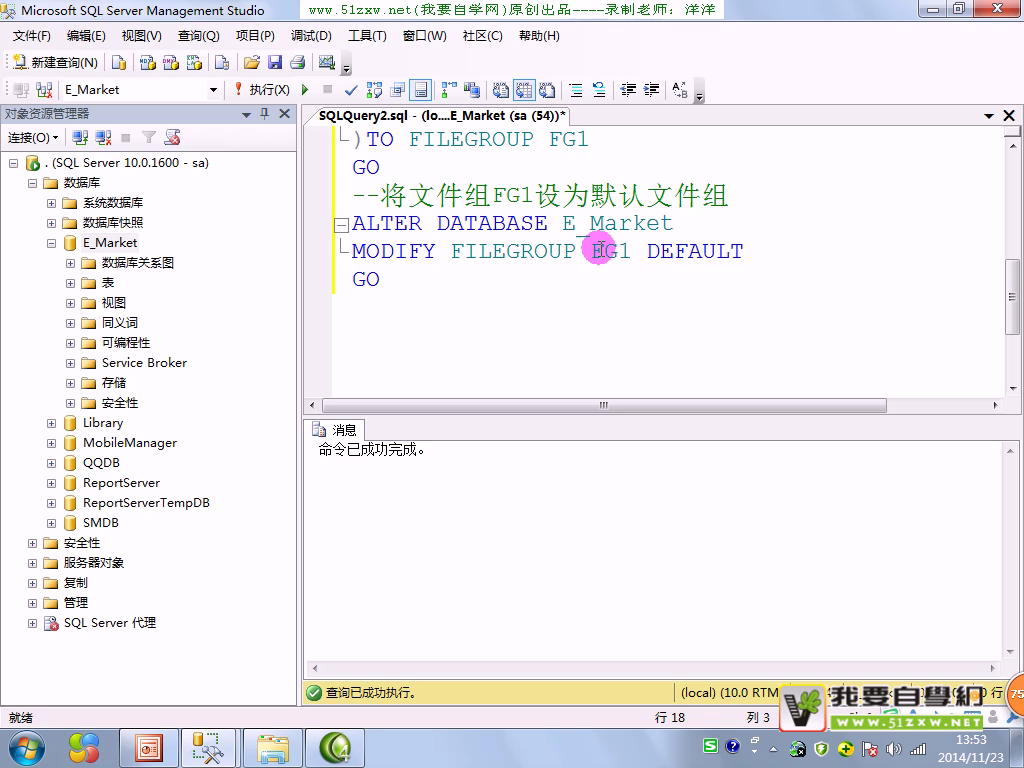
文件组
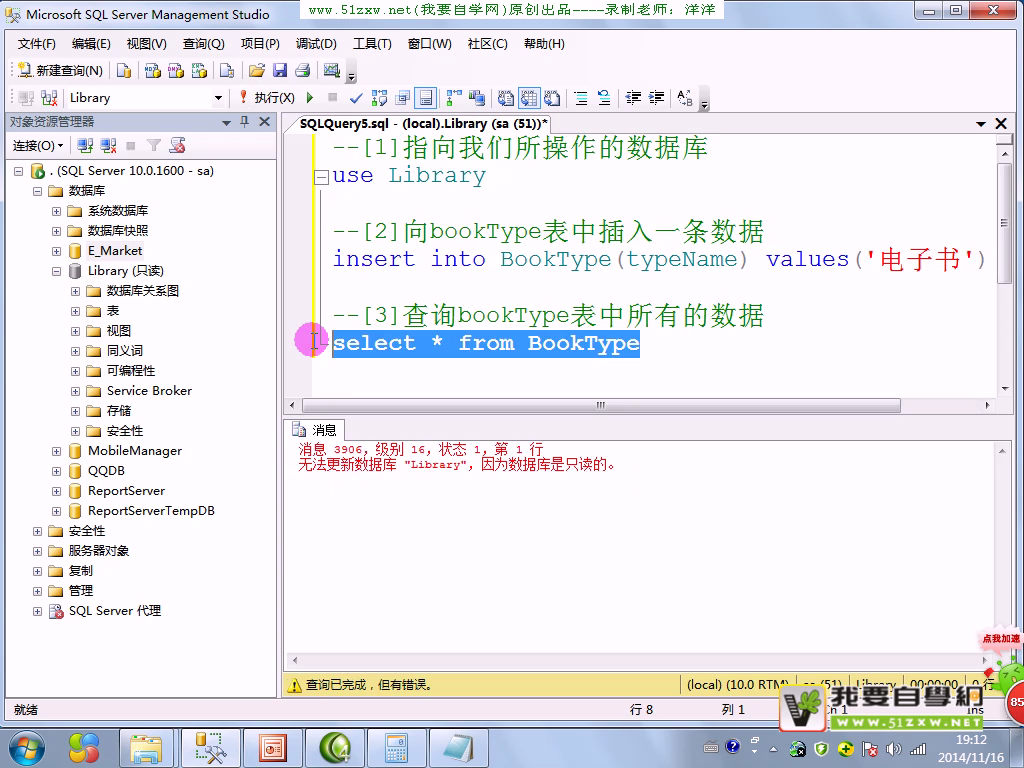
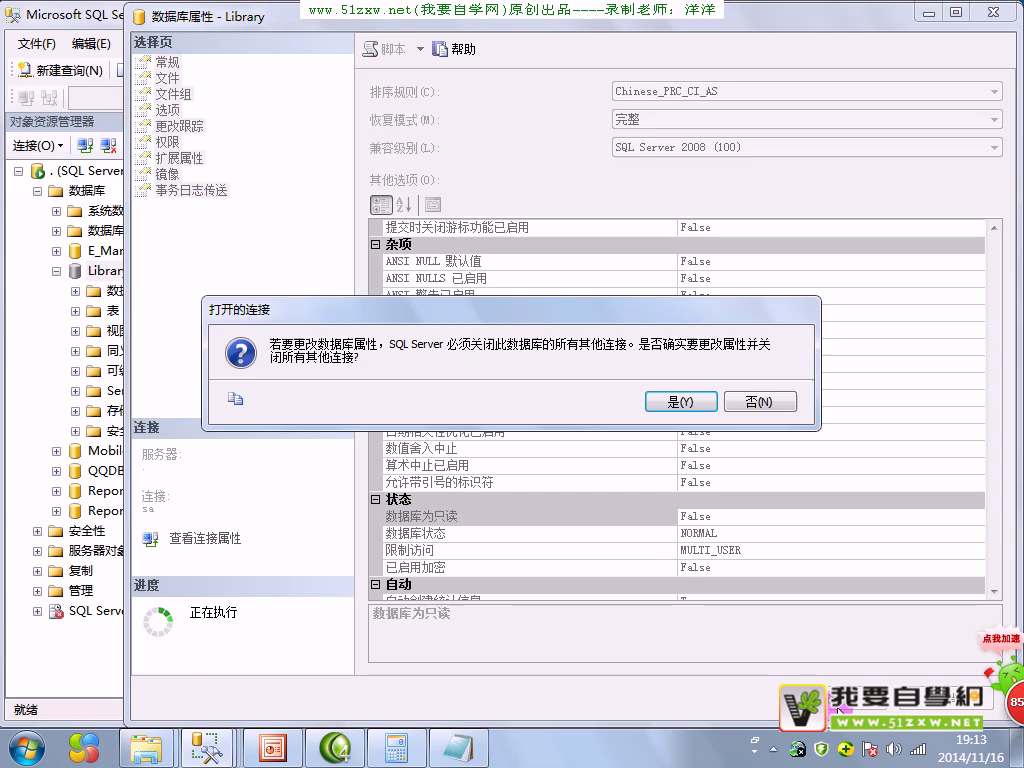
只读属性
sql创建数据库






经常用到的一个系统数据库





删除数据库

用户,角色,权限相关内容


配置远程访问
端口默认1433,防火墙打开高级,入站规则, 2数据库——方面,服务器配置,remoteaccessenabled,remotedacenabled打开,最好重启一下服务






两种方法查看数据库的在线状态





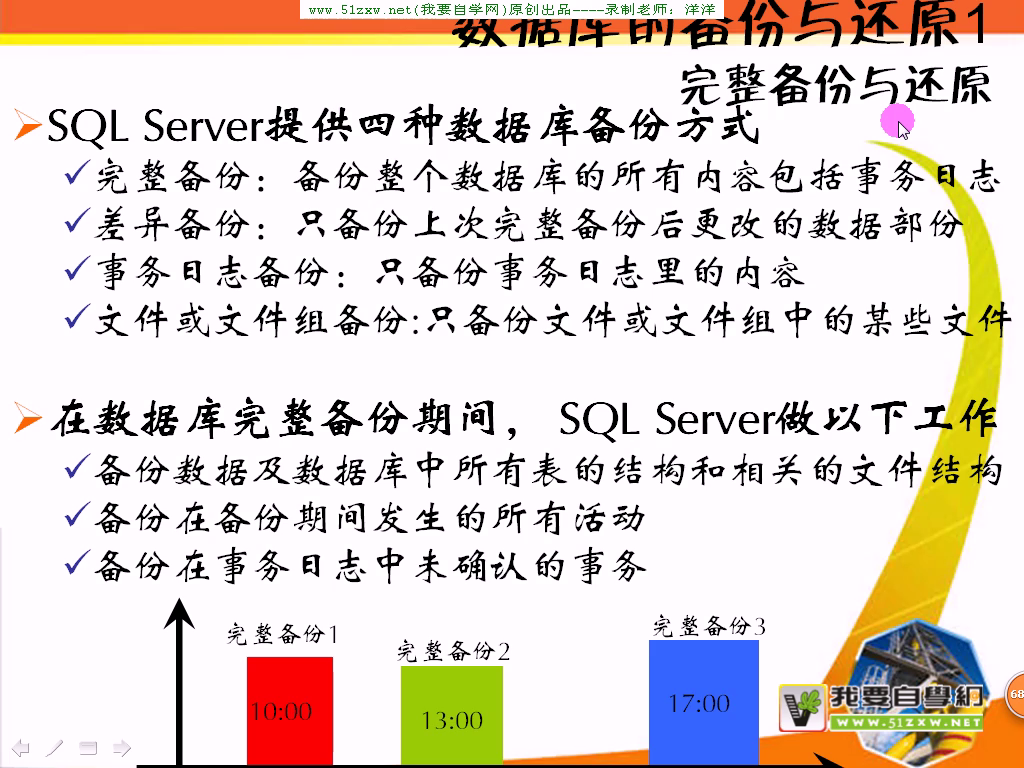
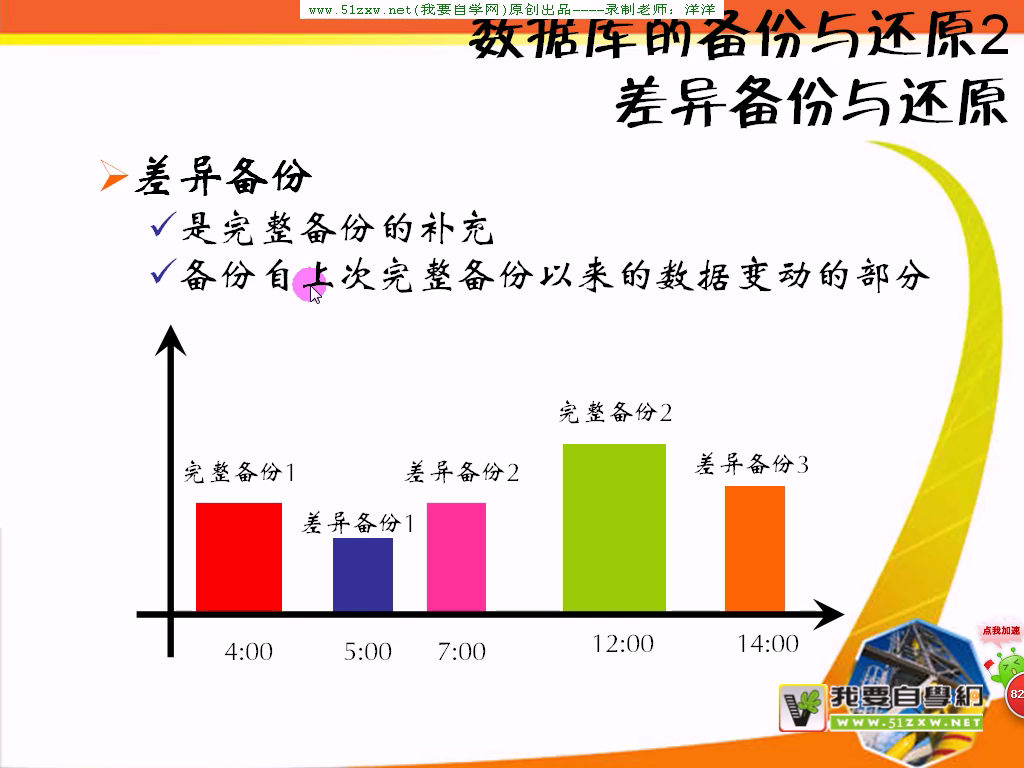

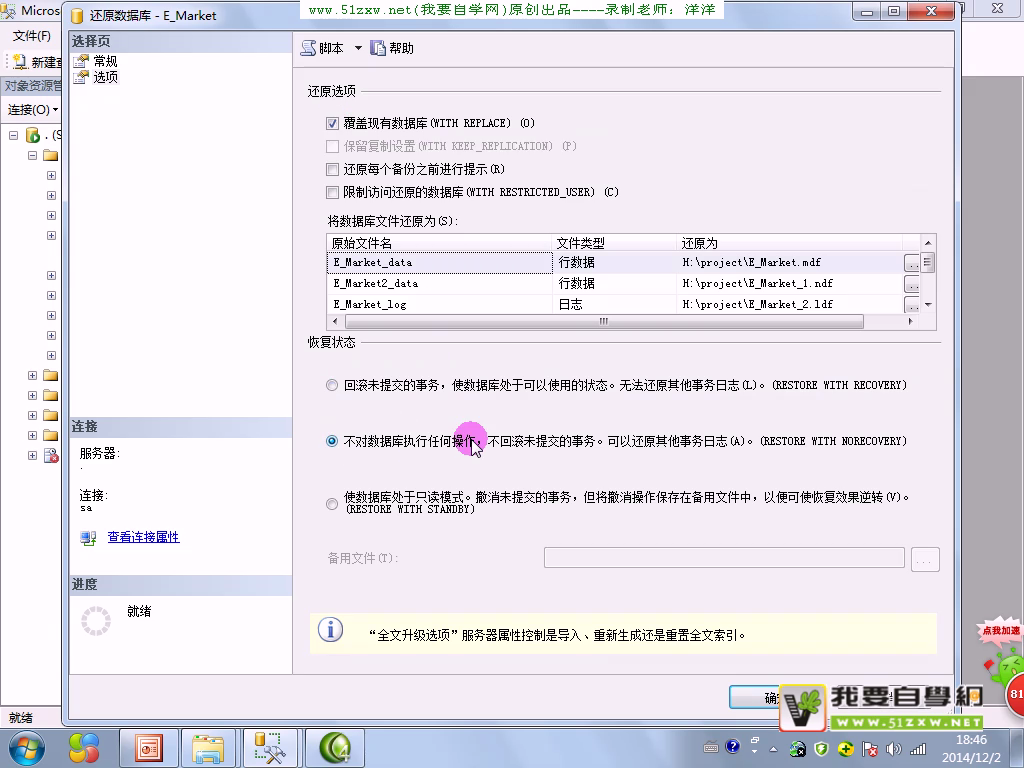
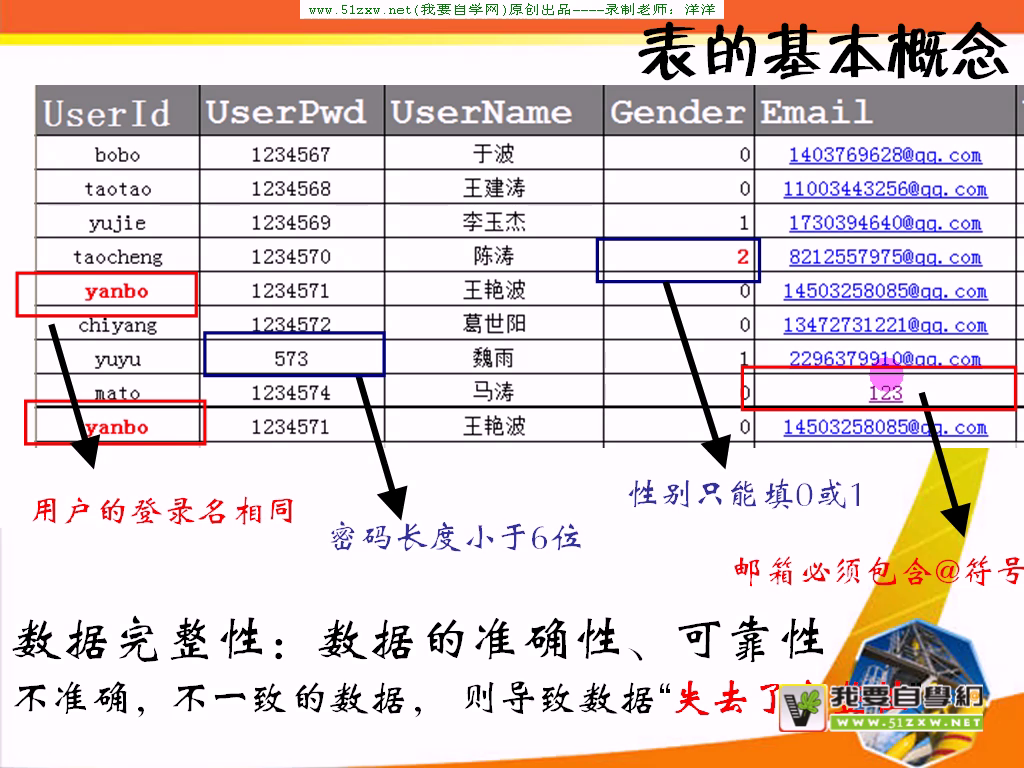
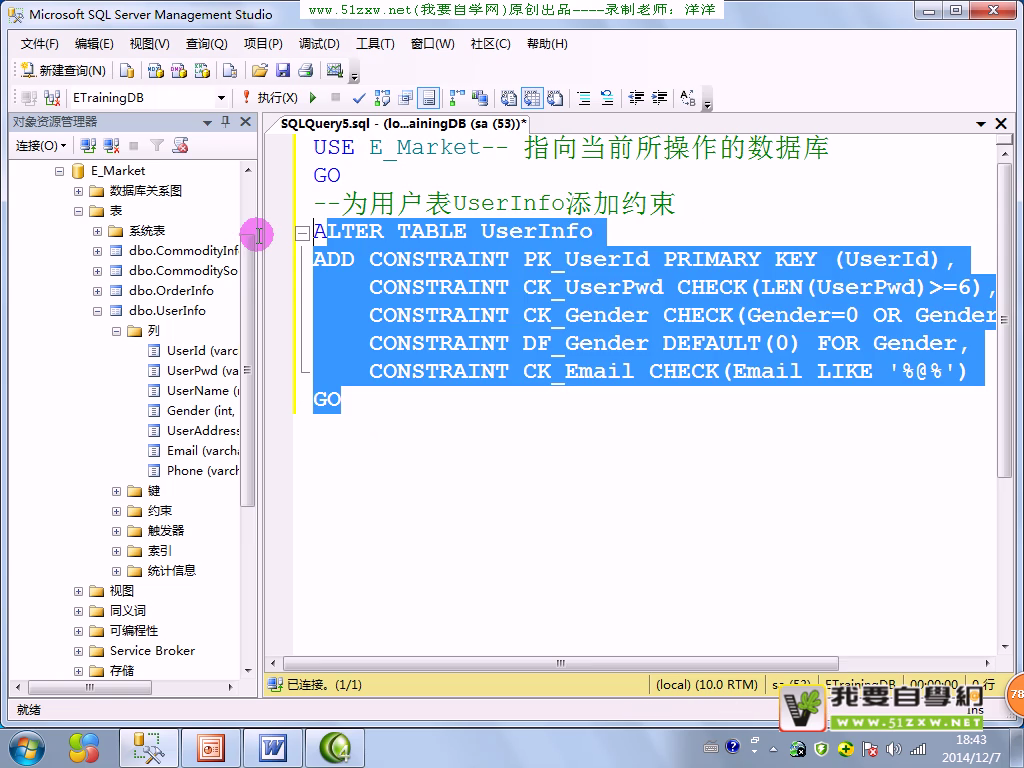
约束性




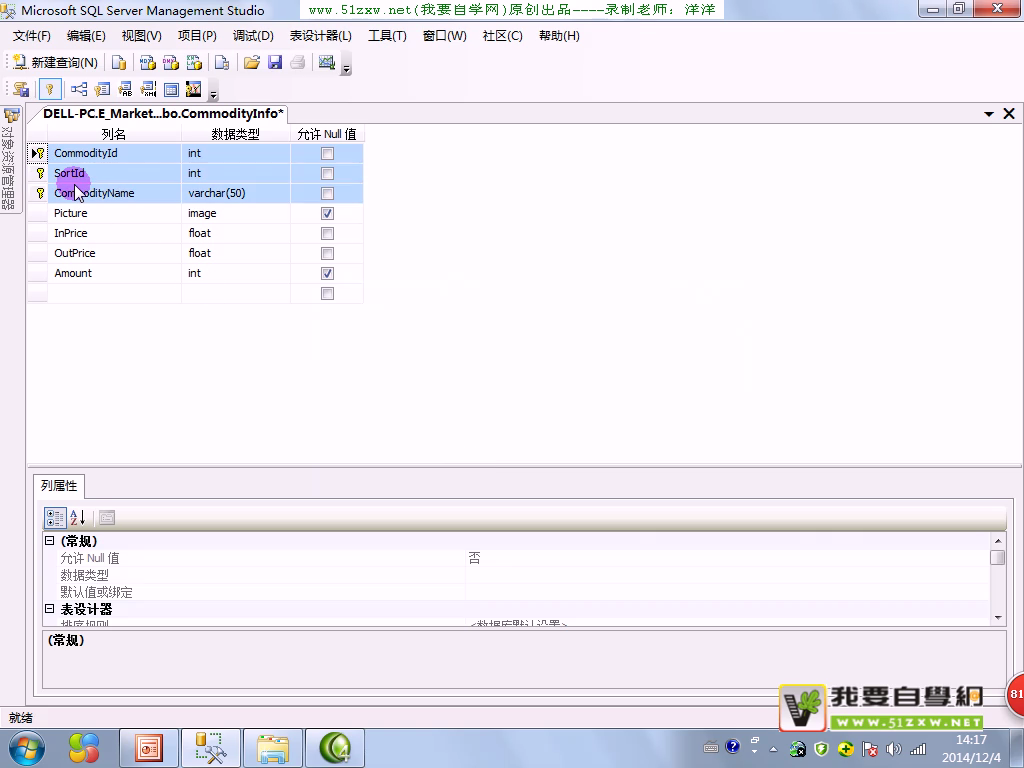









命令行做约束

删除约束
use demo
go
alter table employy
drop CONSTRAINT pk_employee--删除主键
go
alter table emplyee
drop constraint ck_employeeid--删除检查约束
go
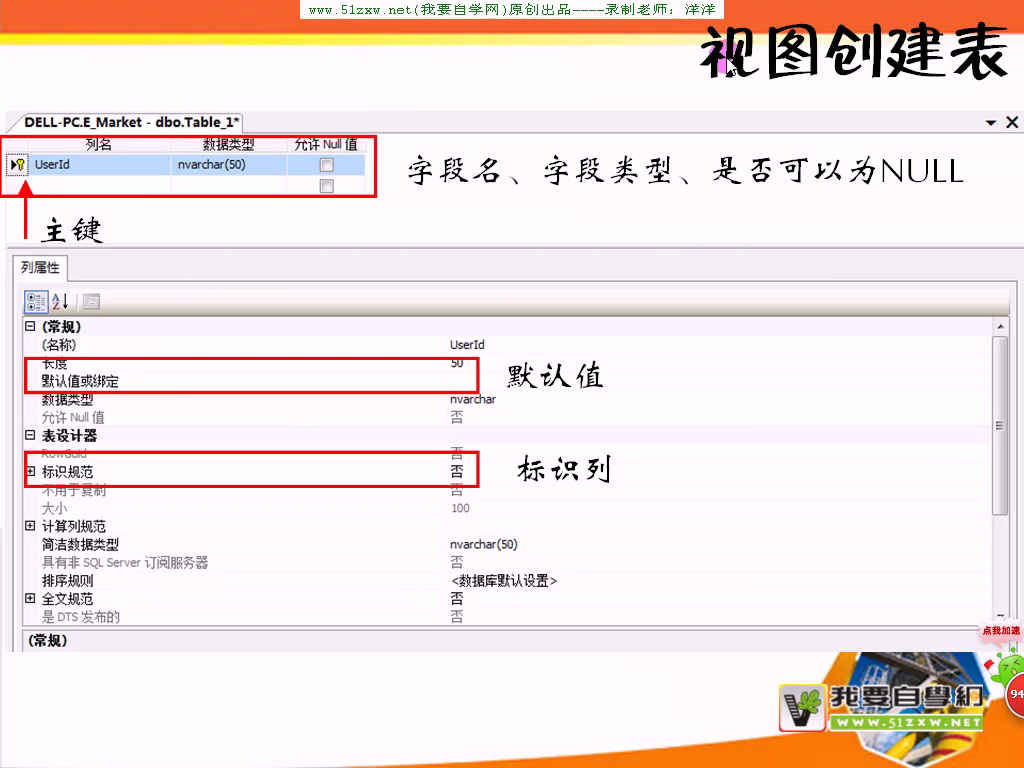
数据库关系图
钥匙指的外键,尾巴指的是外键,主外键关系可以通过关系图创建,拖拉。
删除表
use e_market
drop table 表名
if exists(select * from sysobjects where name='commodityinfo') drop table commodityinfo
create table commodityinfo
(
....
)
go--有外键约束的 先删约束,要不删不了
数据管理
--算术运算符,
select 3+4 as 加的结果
go
select 5/2 as 除的结果 --2.5, 左右两边都是整数,结果是整数,
go
select 5.0/2 as 除的结果 --2.5000000
go
select 5%2 as 模
go
DECLARE @age int
set @age=18--赋值运算符,将等号的右边赋值给左边的变量或者是表达式,
select @age
go
--比较运算符,=,>,<,>=,<=,<>,!=(非92标准)
if(3>5 or 6>3 and not 6>4) select 'true'
else select 'false'
数据插入单行
insert userinfo values ('yoyo','iloveyou','luxiaofeng',1,'lxf@sohu.com','北京海淀','03754955210')
--非空列插入数据,列的个数与数据的个数要完全相同
insert into commodityinfo (sortid,commodityname)
values(1,'xiaoxu')
--默认值表添加数据,用DEFAULT代表
insert into orderinfo (userid,commodityid,amount,payway,ordertime)
values('youyou',1,2,8589,default,'2014-3-24')
--不能为标识列指定值
insert into commoditysort values ('手机数码')--虽然有ID 但不是写
多行数据插入
--通过将现有表中的数据添加到已存在的表中,表中列数数据类型与USERINFO中的数据类型相同
insert into table1 (column1) select <column> from <源表名>
--将现有表中的数据添加到新表中
select (列名) into <表名> from <源表名>
if exists (select * from sysobjects where name='userinfo') drop table userinfo
go
create table useraddress
(
uid varchar(20) primary key(uid) not null,
uname varchar(50) not null,
uaddress varchar(200) ,
uphone varchar(20) not null
)
go
insert into useraddress(uid,uname,uaddress,uphone)
select userid,username,useraddress,phone from userinfo--新表是存在的,没有表执行不了,如果不存在主键就可以执行多次
--新表不存在,而且要一个自动增长列
select userid,username,useraddress,identity(int,1,1) as id--不能选标识列
into addresslist from userinfo--不能执行多次,执行过一次表就已经存在了
更新数据
use uc3
go
--update,如果要更新的值 是多个,那要用,分隔 如果不写WHERE 那就会更新所有的数据,用UPDATE可能更新一条,多条,或者 不会更新数据
update userinfo set gender=1--更新所有的数据
update userinfo set gender=1 where gender=0--一行影响
update userinfo set username='李四',address='河南平顶山' where userid='daxia'
--修改数据的三要素,要修改哪个表,哪个列,改成什么
删除数据
delete [from] 表名 [where <删除条件>] truncate table 表名
use uc3
go
delete e_market--全部删除 如果删除的表里面有标识别,再插入数据的是时候标识种子不是一而是接上上面的,注意主外键关系
--删除的原素,哪个表,条件是什么
--truncate table 也可以删除数据 类似于没有where条件的语句,他的不同点是标识种子,会从种子开始,如果有主外键就删除不了。
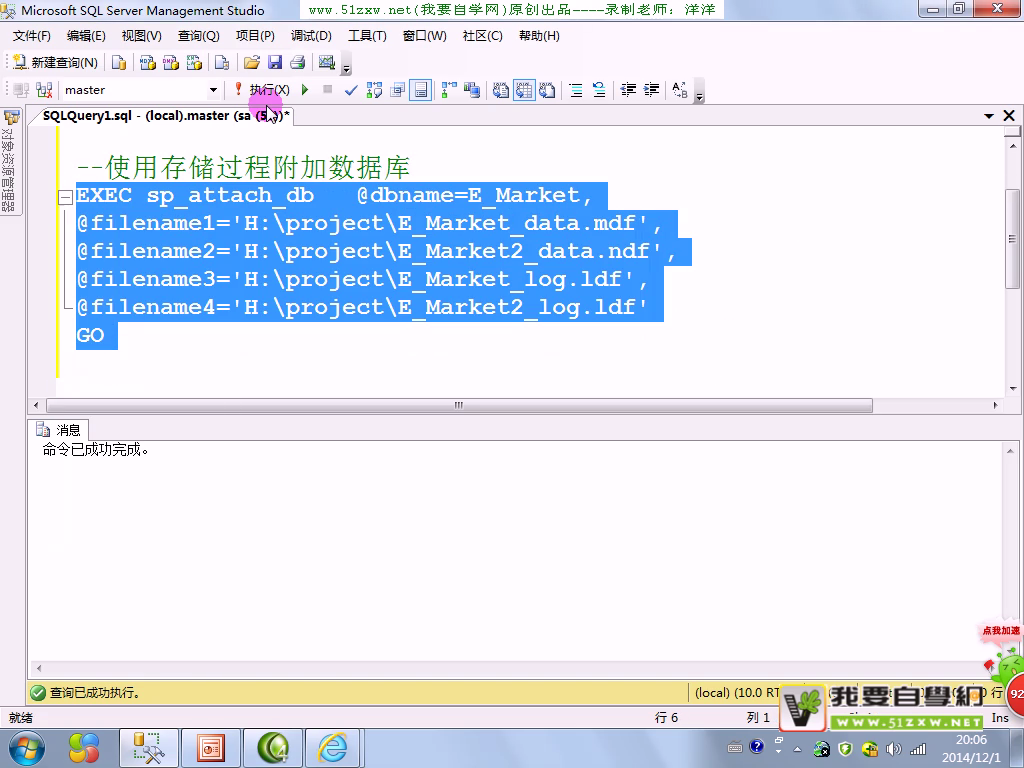
数据的导入导出
先导入外键来源表,再导外键表,里面有一个忽略 两个都点 针对EXCEL
TXT文件 是平面文件,
数据导出,如果导入EXCEL 需要先建文件,
批处理
批处理是指从应用程序一次性地发送一组完整SQL语句到SQL SERVER上执行,
批处理的所有语句被当作一个整体,被成批地分析,编译和执行。
所有的批处理指令以GO作为结束标志
GO的特点:
GO 语句必须**自成一行,只有注释可以在同一行上
每个批处理单独发送到服务器
GO语句不是T-SQL命令
先创建数据库,再创建表,如果这两件事情同时进行的话,必须要加上GO要不然你在充电表的时候,他默认,你使用的是master数据库,他就会在master里面创建表,因为这件事情是有先后顺序的,只有创建了数据库才能创建表,
select 用户名=username from userinfo--重命名
select username as 用户名 from userinfo--重命名
select username 用户名 from userinfo --重命名
select * from userinfo where email is null or email=''--如果原来有值后来被删了,那就不是NULL 是空''
--在查询当中使用常量列
select username,password,'这是用户名和密码'as 购物网站 from orderinfo
--返回限制的行数 使用TOP 1限定的行数 2 限定的百分比
select top 5 username as 用户名 from userinfo
select top 20 percent username as 用户名 from userinfo --但是百分比是小数相乘可能是小说,如果有就进1
--order by [asc,desc]升或降序
select * from userinfo order by username
select * from userinfo order by usernaame desc,password asc
字符串函数


select left(email,charindex('@',email)-1) from userinfo where username='xxx'
select RIGHT(KHBH,len(khbh)-CHARINDEX('h',khbh)) from Hion_Customer
日期函数


dateadd(mm,1.4,getdate()) --小数会直接丢了
datediff(yy,'2008-8-8',getdate())--时间差
select datename(YY,getdate())+datename(dd,getdate())--两边都是字符,相连的效果
select datepart(YY,getdate())+datepart(dd,getdate())--数字 , 是数字相加的结果
数字函数,系统函数

select rand(100)=select rand(100)-- 100是种子, 种子相同返回的随机数相同,没有种子就每次都不一样都是0到1的随机数
select rand()<> select rand()
select celling(9.00000)--10
select celling(-9.000000)---9 永远取的是大值 ,
select floor(9.9999);select floor(-9.0000001) --永远取小值,
select round(9.55555,1)--9.6 select round(9.11111,2) 9.1 需要第二个参数
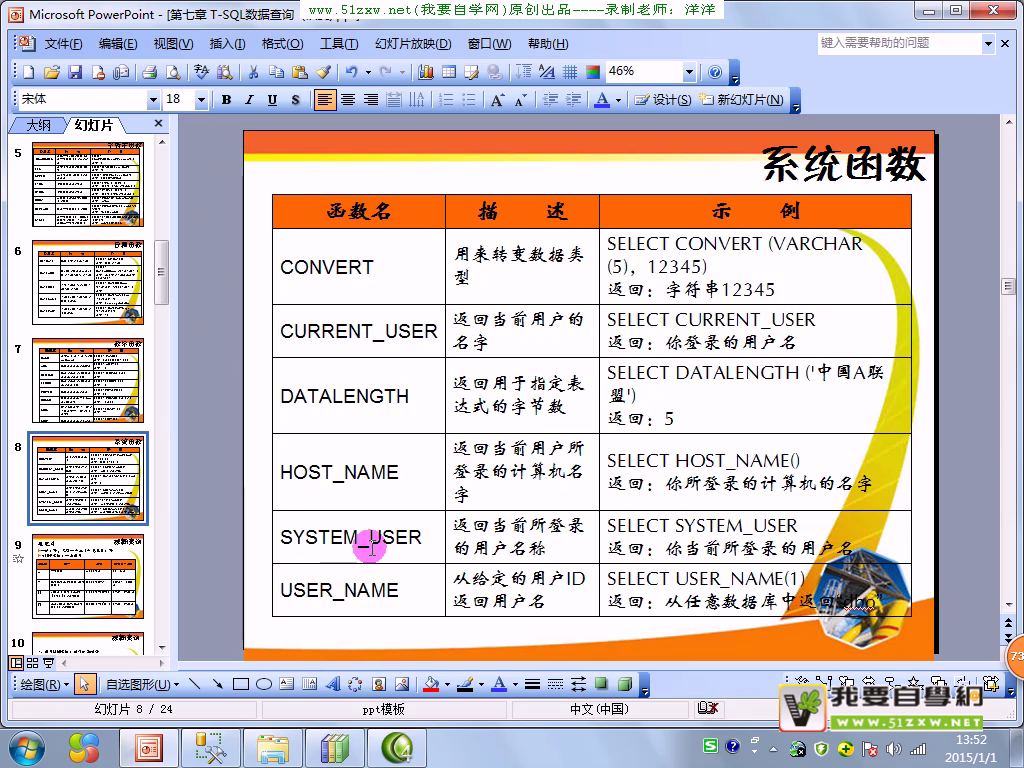
select CONVERT(int,'12')+CONVERT(int,'10')--数字相加
select CONVERT(varchar(10),12)+CONVERT(varchar(3),10) --1210
Date 和 Time 样式
如果 expression 为 date 或 time 数据类型,则 style 可以为下表中显示的值之一。其他值作为 0 进行处理。SQL Server 使用科威特算法来支持阿拉伯样式的日期格式。
| 不带世纪数位 (yy) (1) | 带世纪数位 (yyyy) | 标准 | 输入/输出 (3) |
|---|---|---|---|
| - | 0 或 100 (1, 2) | 默认 | mon dd yyyy hh:miAM(或 PM) |
| 1 | 101 | 美国 | mm/dd/yyyy |
| 2 | 102 | ANSI | yy.mm.dd |
| 3 | 103 | 英国/法国 | dd/mm/yyyy |
| 4 | 104 | 德国 | dd.mm.yy |
| 5 | 105 | 意大利 | dd-mm-yy |
| 6 | 106 (1) | - | dd mon yy |
| 7 | 107 (1) | - | mon dd, yy |
| 8 | 108 | - | hh:mi:ss |
| - | 9 或 109 (1, 2) | 默认设置 + 毫秒 | mon dd yyyy hh:mi:ss:mmmAM(或 PM) |
| 10 | 110 | 美国 | mm-dd-yy |
| 11 | 111 | 日本 | yy/mm/dd |
| 12 | 112 | ISO | yymmdd yyyymmdd |
| - | 13 或 113 (1, 2) | 欧洲默认设置 + 毫秒 | dd mon yyyy hh:mi:ss:mmm(24h) |
| 14 | 114 | - | hh:mi:ss:mmm(24h) |
| - | 20 或 120 (2) | ODBC 规范 | yyyy-mm-dd hh:mi:ss(24h) |
| - | 21 或 121 (2) | ODBC 规范(带毫秒) | yyyy-mm-dd hh:mi:ss.mmm(24h) |
| - | 126 (4) | ISO8601 | yyyy-mm-ddThh:mi:ss.mmm(无空格) |
| - | 127(6, 7) | 带时区 Z 的 ISO8601。 | yyyy-mm-ddThh:mi:ss.mmmZ (无空格) |
| - | 130 (1, 2) | 回历 (5) | dd mon yyyy hh:mi:ss:mmmAM |
| - | 131 (2) | 回历 (5) | dd/mm/yy hh:mi:ss:mmmAM |
select CONVERT(varchar(10),getdate(),102) --

select * from orderinfo where amount between 2 and 10 ==select * from orderinfo where amount>=2 and amount<=10--BETWEEN 用法 可以数字,日期一起用。
select * from orderinfo where name in ('小徐','小李')--和OR相同,通常用在子查询
聚合函数
select sum(amount) from oderinfo where commodityid=6 --返回单行单列
select sum(amount),payway from orderinfo --出错,要用GROUP BY 因为payway没有用聚合函数,这需要GROUP BY
group by
select count(*) from userinfo where gender=0
select count(*) from userinfo where gender=1--需要两条查到两个性别的人的个数 那如果有很多类别需要查那就麻烦了
select count(*),gender from userinfo group by gender--分组查询
--想再看看姓名需要放到分组项
--举例,查询每种商品的销售总量并按降序排列,小技巧:‘每’,‘各’后面的名词就是分组的项,GROU BY后面要不是分组的项要么是聚合函数
select commodityid as 商品编号,sum(amount) from orderinfo group by commodityid order by sum(amount)
--对分组后的数据进行筛选,HAVING
select commodityid as 商品编号,sum(amount) as '销量' from orderinfo group by commodity having sum(amount)>10
order by sum(amount)
多表查询
实际上是通过各个表之间共同列的关联性来查询数据的,它是关系数据库查询最主要的特征
有内连接和外连接
内连接
内连接的两个特点,两个表存在主外键关系,参与查询的两个表的地位相同无主次之分。
实现方式1在WHERE子句指定老连接条件,2在FROM子句中使用INNER JOIN ,,,ON
SELECT orderinfo.orderid,userinfo.username FROM ORDERinfo,userinfo where orderinfo.userid=userinfo.userid--两个上表查询
use UC3
go
select * from Hion_Customer as a,Hion_Contact as b where a.Recid=b.Recid
use UC3
go
select lxr.Contact,lxr.Mobile,phone.province,tonghua.Remarks from Hion_Customer as tonghua
inner join Hion_Contact as lxr on tonghua.Recid=lxr.Recid
inner join Hion_Mobile as phone on LEFT(lxr.mobile,7)=phone.number
order by phone.province
三表查询
外连接查询
至少返回一个表中的所有记录,根据匹配条件,有选择性的返回另一张表的记录。
外链接的特点:
1,参与外连接的表有主从之分,
2,以主表的每行数所匹配从表的数据列将符合条件的数据直接返回到结果集中,
3对那些不符合连接条件的列将被填上null值,然后再返回到结果集中,
外连接的分类
左外连接,右外连接,
合并查询
1,合并表中的列的个数,数据类型必须相同或者相兼容,
2,UNION默认去掉重复值,如果允许有重复,只需要使用,union all
3,执行顺序与左向右(可通过列的顺序或空格改变结果集中的排列顺序)
4,可以与select into,一起使用但是,into必须放在第1个select语句中.
5,可以对合并的结果进行排序,但排序的,order by必须放在最后的一个select后面,所使用的列明也必须是第1个
6,列的名称由第1个select语句里面的字段表示,
简单子查询
1在一个查询语句中包含另一个查询语句,
2此查询必须放在一对小括号内,
3要求子查询的列只能有一个,
4只查询通常作为where的条件,
5子查询中不能出现order by 子句,
use UC3
go
select * from Hion_Customer where Recid in (select Recid from Hion_Contact where Hion_Contact.Contact='李群')
多表之间只查询,
通常情况下多表连接查询都可以使用子查询替换,反过来则不成立,不是所有的子查询都能被表连接查询替换,
只查询只能查询主表的字段,
连接查询可以查看连接表中的任意字段,
exists
只注重子查询是否有返回行,如查有返回行返回结果 为值否则为假。并不使用子查询 的结果,仅用于测试子查询是否有返回结果,
语法 if exists(子查询) BEGIN 语句块 end
if exists(select * from sysdatabases where name='e_market')
drop database e_market
go
create database e_market
(
)
go
--资金购买手机产品数量超过三个的消费金额打8折,
use e_market
go
select sortid from commoditysort where sortname='手机数码'
--
select commodityid from commodityinfo where sortid=
(
select sortid from commoditysort where sortname='手机数码'
)
--
select * from orderinfo where commodityid in
(
select commodityid from commodityinfo where sortid=
(
select sortid from commoditysort where sortname='手机数码'
)
) and amount>3
--
if exists
(
select * from orderinfo where commodityid in
(
select commodityid from commodityinfo where sortid=
(
select sortid from commoditysort where sortname='手机数码'
)
) and amount>3
)
begin
update orderinfo set paymoney=paymoney*0.8
where commodityid in
(
select commodityid from orderinfo where commodityid in
(
select commodityid from commodityinfo where sortid=
(
select sortid from commoditysort where sortname='手机数码'
)
) and amount>3
)
end
--通常用NOT exists对子查询的结果进行取反
相关子查询
ALL:所有
any:部分
some:与any等同,使用any的地方都可以使用some替换
all:父查询中列的值必须大于子查询返回的值列表的第一个值
any:像查询的返回值必须至少大于子查询中的一个值
=any:与in等效:像查询中列的值必须在子查询返回值列表中存在
<>any:与not in的区别
<>any:父查询的结果中的列的值与子查询返回值列表中只要有一个不相同就返回
not in:像查询的结果中的列的值必须不能存在在子查询中
表1 2,3 表2 1,2,3,4
--all
select * from table2 where n>all(select n from table1)--在表2里面查N的值比表1里面都大的值 4
select * from table2 where n>any(select n from table1)--大于其中一个就行了 3,4
select * from table2 where n>some(select n from table1)--大于其中一个就行了 3,4 一样的
select * from table2 where n=any(select n from table1)=select * from table2 where n in(select n from table1)--两个相同
select * from table2 where n<>any(select n from table1)--1,2,3,4 复查询的结果中列表的是鱼子查询,返回的值列表中有一个不相同,有点OR的意思
select * from table2 where n not in(select n from table1)--1,4 and的意思
子查询的注意事项
任何允许使用表达式的地方都可以使用子查询,
select sortname from commoditysort where sortid=1--手机数码
select commodityname as 商品名称,
(select sortname from commoditysort where sortid=1) from commodityinfo where sortid=1--列名使用
--
select sum(amount)as cnt from commodityinfo
group by sortid
having sum(amount)>10000
--将查询作为表使用
select s.sortname as 商品名称 from commoditysort as s
inner join (select sum(amount)as cnt from commodityinfo
group by sortid
having sum(amount)>10000) as t on s.sortid=t.sortid
TSQL程序
变量:
指的是在程序运行过程中值 可以发生变化 的量,可以存储数据值 的对象,能够向sq语句传递数据
变量的分类:
全局变量:系统定义和维护,可以直接使用以@@开头
局部变量:同操作者定义,以@开头,使用关键字DECLARE声明
特点:先声明再赋值
作用域:只在定义它的批处理或过程中可见
局问她变量的作用:在上下语句中传递数据
语法:DECLARE @变量名 数据 类型
变量赋值:
关键字:set 赋给变量常量值
关键字:select 从表中查询数据,然后再赋给变量
全用set与select语句赋值的区别
1、set不支持对多个变量赋值,select可以
2、表达式返回多个值 时set出错,将返回的最后一个值
3、表达式未返回值 时SET赋null,select保持原值 不变
declare @userid varchar(10)
set @userid='xiaoxu'
use UC3
go
declare @name VARCHAR(10),@pwd varchar(10)
set @name='杨利'
select @pwd=mobile from Hion_Contact where Contact=@name
select Mobile from Hion_Contact where Contact=@name
print @pwd
--同时为多个变量赋值
set @name='张三',@pwd='lisi'--直接报错 不能在一行做
select @name='张三',@provice='李四'--语法不报错
--当结果集是多个值的时候可以这样赋值
select @province=useraddress from userinfo --结果只是返回了最后一个值,多结果 的时候
set @name=(select username from userinfo where userid='yaya')--null 当结果 是没有记录就是null值
select @name=username from userinfo where userid='yaya'--当用SELECT赋值的时候,如果没有结果集,那就不改@NAME的值 还是张三
全局变量
是系统已经定义好的变量,主要反映SQL数据库的操作的状态
全局变量名称以@@开头
@@indentity:返加最后插入的标识值
@@error:返回执行的上一个t-sql语句的错误号
select * from Hion_CustomerType
--INSERT into Hion_CustomerType VALUES ('一般会员')
select @@identity--14
select @@error--正确是0,不正确是大于0的数
数据类型转换
隐式转换:类型相兼容自动转换
显示转换:可以使用convert函数或cast函数
相同点
用于将某数据类型的各地怕啊转换为另一种数据类型的表达式
不同点
在转换日期时间类型/浮点类型的数据 转换为字符串时convert()可以通过第三个参数指定转换后的字符样式,不同的样式使用转换后字符数据的显示格式不同。
print '错误号'+cast(@@error as varchar(5))
print '错误号'+convert(varchar(5),@@error)
select CAST(getdate() as varchar(20))--12 10 2019 1:20PM
select convert(varchar(20),getdate(),102)--2019.12.10更灵活
日期转字符表
| 不带世纪数位 (yy) | 带世纪数位 (yyyy) | 标准 | 输入/输出** |
|---|---|---|---|
| - | 0 或 100 (*) | 默认值 | mon dd yyyy hh:miAM(或 PM) |
| 1 | 101 | 美国 | mm/dd/yyyy |
| 2 | 102 | ANSI | yy.mm.dd |
| 3 | 103 | 英国/法国 | dd/mm/yy |
| 4 | 104 | 德国 | dd.mm.yy |
| 5 | 105 | 意大利 | dd-mm-yy |
| 6 | 106 | - | dd mon yy |
| 7 | 107 | - | mon dd, yy |
| 8 | 108 | - | hh:mm:ss |
| - | 9 或 109 (*) | 默认值 + 毫秒 | mon dd yyyy hh:mi:ss:mmmAM(或 PM) |
| 10 | 110 | 美国 | mm-dd-yy |
| 11 | 111 | 日本 | yy/mm/dd |
| 12 | 112 | ISO | yymmdd |
| - | 13 或 113 (*) | 欧洲默认值 + 毫秒 | dd mon yyyy hh:mm:ss:mmm(24h) |
| 14 | 114 | - | hh:mi:ss:mmm(24h) |
| - | 20 或 120 (*) | ODBC 规范 | yyyy-mm-dd hh:mm:ss[.fff] |
| - | 21 或 121 (*) | ODBC 规范(带毫秒) | yyyy-mm-dd hh:mm:ss[.fff] |
| - | 126(***) | ISO8601 | yyyy-mm-dd Thh:mm:ss.mmm(不含空格) |
| - | 130* | Hijri**** | dd mon yyyy hh:mi:ss:mmmAM |
| - | 131* | Hijri**** | dd/mm/yy hh:mi:ss:mmmAM |
表中‘*’表示的含义说明: * 默认值(style 0 或 100、9 或 109、13 或 113、20 或 120、21 或 121)始终返回世纪数位 (yyyy)。
** 当转换为 datetime时输入;当转换为字符数据时输出。
*** 专门用于 XML。对于从 datetime或 smalldatetime 到 character 数据的转换,输出格式如表中所示。对于从 float、money 或 smallmoney 到 character 数据的转换,输出等同于 style 2。对于从 real 到 character 数据的转换,输出等同于 style 1。
**** Hijri 是具有几种变化形式的日历系统,Microsoft? SQL Server? 2000 使用其中的科威特算法。
流程控制
流程控制语句:是用来控制程序执行流程的语句。常用的流程控制语句的分类
顺序结构:begin end
分支结构 :if。。。else 或 case。。。end
循环结构:while
语法:
begin
语句块
end
--特点:1必须成对出现,2通常与分支结构和循环结构一起使用3可以嵌套
declare @x varchar(10),@y varchar(10),@t varchar(10)
set @x='1'
set @y='2'
print '交换前他们的值是:x'+@x+'y是:'+@y
begin
set @t=@x
set @x=@y
set @y=@t
end
print '交换后x='+@x+' y='+@y
go --在顺序结构中 效果不明显 但是在分支结构或者循环结构中必须 要写,语句超过1就要写
if....else
特点:1.else并不一定是必须 的2。如果条件为真,将执行语句或语句块1,条件为假则执行语句或语句圬2。 无论哪种情况,最后都要执行if。。。else语句的下一条语句3、if else 可以嵌套4、如果只有一条语句begin。。end可以省略
use uc3
go
DECLARE @x int,@y int
SELECT @x=10,@y=20
if (@x>=@y)
print 'x大于y'
print ' '--出错
else
PRINT 'x小于y'
go
--这样执行没有问题但是如果,if 或者ELSE有多条语句就不行了。
if (@x>@y)
begin
print 'x大于y'
print ' '--这样没问题
end
分支结构case..end
语法:
case
when 条件1 then 结果1
when 条件2 then 结果2
。。。。
else
执行顺序:
条件1成产执行结果 1
条件2 成立执行结果2
如果所有的WHEN中的条件都不成立,则执行ELSE中的结果
说明:else可省略,如果省略else并且when 的条件表达式的结果都不为true,则case语句返回null
declare @score int
set @score=60
select 成绩=case
when @score>=90 then 'a'
when @score between 80 and 89 then 'b'
when @score between 70 and 79 then 'c'
when @score between 60 and 69 then 'd'
else 'e'
end
go
事务
事务(transaction)是作为单个逻辑工作单元执行的一系列操作外人操作作为一个整体向系统提交,要么都执行、要么都不执行,事务是一个不可分割的工作逻辑单元
转帐过程就是一个事务
它需要两条UPDATE语句来完成,这两个语句是一个整体如果其中作一条出现错误,则整个转帐业务也应取消,两个的余额应恢复到原来的数据,从而确保转帐前和围巾后的余额不变,即都是250
事务必须具备以下四个属性,简称ACID属性:
原子性(ATOMICITY)
事务是一个赛鱼听操作,事务的各步操作是不可分(原子的);要么都执行,要么都不执行
一致性(CONSISTENCY)
当事务完成时,数据必须处于一致状态
隔离性(isolation)
张三和李四之间的转帐与王五和赵二之间的转帐,永远是相互独立的。
永久性
事务完成后,它对数据库的修改被永久保持
创建事务
开始事务 BEGIN TRANSACTION
提交事务 commit transaction
回滚(撤消事务) rollback transaction
一旦事务提交或回滚,则事务结束
操作步骤:
1,BEGIN TRAN
2,声明变量用于累加错误号,错误号使用全局变量@@error
3,为(2)中声明的变量赋初值为0
4,增、删、改T-SQL语句
5,SET @变量=@变量+@@error --累计错误号
。。。
重复(4)(5)直到所有的业务完成
6,使用if。。else判断 累加的错误号是否》0,大于0就回滋,否则就提交
use e_market
go
set nocount on --不显示受影响的行数
select * from bank
go
--开始事务(从此处开妈中,后续的T-SQL语句是一个整体
begin tran--开始事务
declare @error int--用这个变量累计事务执行过程中的错误
set @error=0
update bank set currentmoney=currentmoney-500 where customername='张小虎'
set @error=@error+@@error--累计错误值
update bank set currentmoney=currentmoney+500 where customername='王小丽'
set @error=@error+@@error--累计错误
print '查看转帐过程中的余额'
select * from bank
--使用if。。else去判断 累加的错误值 ,
if (@error>0)--括号是可以不写的
begin
print '交易失败!回滚事务'
rollback tran --回滚事务
end
else
begin
print '交易成功,提交事务,写入硬盘'
commit tran
end
select * from bank
go
嵌套事务及事务分类
全局变量@@trancount
返回当前 老婆如若活动事务数
显 式事务
用BEGIN TRANSACTION明确指定事务的开始
最学用的事务类型
隐性事务
能过设置set implicit_transactions on 语句,将隐性事务模式设置为打开
基后的T-SQL语句自动启动一个新事务
提交或回滚一个事务后,下一个T-SQL语句又将启动一个新事务
自动提交事务
sql SERVER的默认模式
每条单独的T-SQL语句视为一个事务
--commit 对事务数量的影响(使用了嵌套事务)
print @@trancount --在没有事务的时候查看一下事务数
begin tran
print @@trancount--开始事务,@@trancount 将被设置为1
begin tran
print @@trancount--事务数再加1
commit tran
print @@trancount--提交一个变量减去1
commit tran
print @@trancount
--rollback(回滚/撤销)对事务数的影向
print @@trancount
begin tran
print @@trancount
begin tran
print @@trancount
rollback tran --回滚事务,所有事物都回滚变成0
print @@trancount
事务的相关问题
事务的分类
串行方式:处理效率慢,但是准确,自上而下的执行
并发方式 :处理效率高,但要注意的东西多
事务并发所产生的问题
数据丢失更新:两个事务同时一组数据项更新,导致后面的更新覆盖前面的更新。
读“脏”数据:一个事务正在读另一个更新事务沿未提交的数据
不可重复读:当一个事务读取某一数据 后,另一事务对该数据 执行了更新操作,合得第一个事务无法再次读取与前一 次相同的结果
解决并发事务的问题的解决方案--封锁
共享锁:一个数据对象上已存在共享锁时,其他事务可以读取数据但不能修改数据
排他锁:它所锁定的资源 ,其他事务不能读取也不能修改。
更新锁:在修改操作的初始化阶段用来锁定可能要被 修改的资源
意向锁:意向锁表示一个事务为了访问数据库对象层次结构中的某些底层资源而加共享锁或排他锁的意向。
隔离级别
未制授权读取:允许读“脏”数据,但不允许更新丢失,如果一个事务已经开始写数据 ,则允许 其他事务读此数据,但不允许同时进行写操作
授权读取:读取数据 的看下咯国允许 其他并行事务访问该数据 ,但是未提交的写事务将禁止其他事和轴时访问该数据
可重复读:禁止不可重复读和读“脏”数据,但有时可能出现“幻读”数据 。
序列化:它要求事务序列化扫行,妈事务只能一个接着一个地执行。
表级锁是由程序员设定的可以对select,insert,update,delete语句进行精确控制,一般来说,读操作需要
视图和索引
视图是保存在数据库中的SELECT查询,是一线虚拟表,能够从多个表中提取数据,并以单个表的形式展现数据。
视图中不存放数据
数据存放在视图所引用的原始表中
一个原始表,根据不同用户的不同需求,可以创建个不同的视图
查询与视图有哪些异同点
不同点:存储上:视图存储在数据库中,查询以.SQL文件形式保存
排序上:要排序必须 有TOP关键字,查询无要求
安全上:视图可以加密,查询 不可以
相同点:都是SQL语句定义的
创建视图的方式:
使用SSMS创建视图
使用T-SQL语句创建视图
试图一般以vw开头,
使用方法和t-sql语句一样
select * from vw_userinfo --查看视图内容
--创建视图
create view view_name
as <select 语句>
--删除视图
if exists (select * from sysobjects where name='view_name') drop view view_name
use e_market
if exists (select * from sysobjects where name='vw_userinfo') drop view vw_userinfo
go
create view vw_userinfo-- 必须是批处理里面的第1个语句,所以说前面要加go
as
select userid as 登陆名 ,usernmae as 姓名,email as 邮箱,useraddress as 地址 from userinfo
--试图的内容来源于多张表,并且待查询条件,
if exists (select * from sysobjects where name='vw_commodity') drop view vw_commodity
go
create view vw_commodity
as
select top 100 percent * from commodityinfo as c inner join commoditysort as s on c.sortid=s.sortid
where s.sortname='图书印象'
order by c.amount desc--如果有order by 必须 有TOP
视图的优缺点
使用视图的优点
视图着重于特定的数据
简化数据 的操作,易维护
使用视图的缺点
操作视图会比直接操作基础表要慢
修改限制
使用视图的注意事项
视图定义中的select语句不能名手下列内容
order by子句,除非在select语句的选择列表中也有一个top 子句
into 关键字
引用临时表或表变量
临时表,1存储在tempdb22本地临时表已“#“开头,全局临时表以”##“开头3断开连接时临时表被删除
create table #newtable
(
id int,
username varchar(20)
)go
创建视图的时候不能创建临时表,
表变量,1,表变量实际 是变量一种形式2,以@开头3,存在内存中
declare @table table
(
id int,
name varchar(20)
)
索引
sql纺排数据的内部方法
为swl server提供了一种方法来编排查询数据
索引分类
聚集索引:正文内容本身就是一种按照一定规则排列的目录称为‘聚集索引’
非聚集索引:目录纯粹是目录,正文纯粹是正文的排序方式称为‘非聚集索引’
作用:大提高数据库的检索速度,改善数据库性能
建立索引的一般原则 :
每个表只能创建一个聚集索引
每个表最多可创建249个非聚集索引
在写磁盘数据要求的字段上建立索引
TEXT,IMAGE和BIT数据类型的列上不要建立索引
外建可以建立索引
主键列必须建立索引
重复值比较多,查询 较少的列上不要建立索引
索引的创建方式:
SSMS管理器创建索引
使用T-SQL语句创建索引
语法
if exists(select * from sysindexes where name='索引名') go
drop index 表名:索引名
create [unique] [clustered|nonclustered]
index 索引名
on 表名:(列名)
[with fillfactor=x]
--unique:唯一索引
--clustered|nonclustered:聚集索引或非聚集索引
--fillfactor:填充因子(系数):指定一个0~100之间的数表示索引页填充的百分比
use UC3--创建索引,
go
if exists(select * from sysindexes where name='KH2') drop index hion_contact.KH2
go
create nonclustered index KH2
on hion_contact(khbh)
with fillfactor=30
go
--使用索引,
use UC3
select * from Hion_Contact
with(index=PK_Hion_Contact_1)--用不用这个都行,默认已经给你索引了,根据创建的索引自动优化查询
where Recid like '57%'
查看索引
使用ssms查看索引
使用系统存储过程查看索引 exec sp_helpindex 表名
使用视图查看索引 use 当前所使用的数据库 select * from sysindexes where name='索引名'
use e_market
go
exec sp_helpindex userinfo
use UC3
exec sp_helpindex hion_contact
use UC3
select * from sysindexes where name='kh3' --ID就是表的ID 在下面的命令中可以看那个表的ID
select * from sysobjects where name='hion_contact'
存储过程
预编译SQL语句的集合
代替了传统的逐条执行SQL语句的方式
可包含查询 ,插入删除,更新等操作的一系列sql语句
存储在sqlserver中
通过名称和参数执行
可带参数,也可返回结果
可包含数据操纵语句,变量,逻辑控件语句
优点
执行速度更快
因为存储过程在创建时已经被 编译,每次执行次不需要编译,而sql语句每次执行都需要编译
允许模块化程序 设计
存储过程一旦被创建,以后即可在程序 中调用任意多次,这可以改进应用程序 的可维护性,并允许应用程序 统一访问数据库
提高系统 安全性
存储过程在数据 库中,用户只需提交存储过程名称就可以直接执行,避免了攻击者非法截取sqk代码获得用户数据 的可能 性。
减少网络流通量
一个需要数百行sql语句代码的操作可以通过一条执行过程代友来执行,而不需要在网络中发送数百行代码。
重要优点:安全县城执行速度快
存储过程的分类
系统 存储过程:
用来管理sql server和显示 有关数据库和用户信息的存储过程SP_开头存放在MASTER数据库中
扩展存储过程:
使用其他编程语言创建外部存储过程,并将这个存储过程在SQL SERVER 中作为存储过程来使用。XP_开头
自定义存储过程:
用户在SQL SERVER中能过采SQL语句创建存储过程,通常以USP_开头
存储过程的调用
EXECUTE 过程名 [参数]
或
exec 过程名 [参数]
use master--常用的系统存储过程
go
execute sp_databases--列出当前的系统中的数据库
exec sp_renamedb @dbname='UC4',@newname='DEMO' --修改数据库的名称
exec sp_renamedb 'demo','demo1'--可以直接写修改数据库名称
use UC3
exec sp_help hion_contact--查看表的所有信息
--常用的扩展存储过程 xp__cmdshell
use master
go
exec sp_configure 'show advanced option',1 --启用XP_CMDSHELL
GO
RECONFIGURE --重新配置
go
exec sp_configure 'xp_cmdshell',1 --打开XP_CMDSHELL,可以调用
go
RECONFIGURE
GO
--使用XP_CMDSHELL 在D盘创建MYFILE文件加
exec xp_cmdshell 'mkdir d:myfile1',no_output --是否现实返回信息 不返回
go
--扩展的存储过程在以后的版本很可能被废除,所在提醒最好不要使用扩展存储过程
创建不带参数的存储过程
语法
create proc [edure]
as
sql 语句
go--必须要加批处理的GO
use UC3
go
if exists(select * from sysobjects where name='usp_info')drop proc usp_info
go
create proc usp_info--必须 是批处理的第一句话前面要加GO
as
select * from Hion_Contact
go
use UC3
exec usp_info
创建带输入参数的存储过程
语法
create proc[edure]
@参数1 数据类型=默认值
@参数2 数据类型=默认值
as
sql 语句
go
use UC3
if exists (select * from sysobjects where name='usp_contact') drop proc usp_contact
go
create proc usp_contact
@name varchar(10)='曹振'
as
select * from Hion_Contact where Contact like @name
go
use UC3
go
exec usp_contact
use e_market
go
create proc usp_getorderinfo
@startdate datetime,--开始时间
@enddate datetime=null,结束时间
@userid varchar(20)=null--指定用户
as
if @enddate is null
begin
set @enddate=getdate()--赋当前时间
end
if @userid is null--查询指定时间段内的所有订单信息
begin
select * from orderinfo as o
inner join commodityinfo as c on o.commodityid=c.commodityid
inner join commoditysort as s on c.sortid = s.sortid
where o.ordertime between @startdate and @enddate
end
else
begin
select * from orderinfo as o
inner join commodityinfo as c on o.commodityid=c.commodityid
inner join commoditysort as s on c.sortid = s.sortid
where o.ordertime between @startdate and @enddate
and userid=@userid
end
go
--隐式调用和显式调用, 隐式调要求顺序都一样, 显式调用如果为空可以用@STATTIME=DEFAULT,如果 是显式调用,如果一个写的显式形式, 那以后都要用@变量=值
--可以通过声明变量来调用
declare @d1 datetime,@d2 datetime @uid varchar(20)
set @d1='2014-11-1'
set @d2='2014-12-1'
set @uid='xiangxiang'
exec usp_getorderinfo @d1,@d2,@uid
创建带输出参数的存储过程
语法
create proc [edure]
@参数1 数据类型=默认值 output,
@参数2 数据类型=默认值 output
as
sql 语句
go
--一般用在如果 插入成功那插插入的信息是什么,可以返回一个ID